 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntuitive control of supernumerary robotic limbs through a tactile-encoded neural interface
Nov 11, 2025



Brain-computer interfaces (BCIs) promise to extend human movement capabilities by enabling direct neural control of supernumerary effectors, yet integrating augmented commands with multiple degrees of freedom without disrupting natural movement remains a key challenge. Here, we propose a tactile-encoded BCI that leverages sensory afferents through a novel tactile-evoked P300 paradigm, allowing intuitive and reliable decoding of supernumerary motor intentions even when superimposed with voluntary actions. The interface was evaluated in a multi-day experiment comprising of a single motor recognition task to validate baseline BCI performance and a dual task paradigm to assess the potential influence between the BCI and natural human movement. The brain interface achieved real-time and reliable decoding of four supernumerary degrees of freedom, with significant performance improvements after only three days of training. Importantly, after training, performance did not differ significantly between the single- and dual-BCI task conditions, and natural movement remained unimpaired during concurrent supernumerary control. Lastly, the interface was deployed in a movement augmentation task, demonstrating its ability to command two supernumerary robotic arms for functional assistance during bimanual tasks. These results establish a new neural interface paradigm for movement augmentation through stimulation of sensory afferents, expanding motor degrees of freedom without impairing natural movement.
Can We Afford The Perfect Prompt? Balancing Cost and Accuracy with the Economical Prompting Index
Dec 02, 2024



As prompt engineering research rapidly evolves, evaluations beyond accuracy are crucial for developing cost-effective techniques. We present the Economical Prompting Index (EPI), a novel metric that combines accuracy scores with token consumption, adjusted by a user-specified cost concern level to reflect different resource constraints. Our study examines 6 advanced prompting techniques, including Chain-of-Thought, Self-Consistency, and Tree of Thoughts, across 10 widely-used language models and 4 diverse datasets. We demonstrate that approaches such as Self-Consistency often provide statistically insignificant gains while becoming cost-prohibitive. For example, on high-performing models like Claude 3.5 Sonnet, the EPI of simpler techniques like Chain-of-Thought (0.72) surpasses more complex methods like Self-Consistency (0.64) at slight cost concern levels. Our findings suggest a reevaluation of complex prompting strategies in resource-constrained scenarios, potentially reshaping future research priorities and improving cost-effectiveness for end-users.
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Oct 08, 2024



We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.
DyGMamba: Efficiently Modeling Long-Term Temporal Dependency on Continuous-Time Dynamic Graphs with State Space Models
Aug 08, 2024



Learning useful representations for continuous-time dynamic graphs (CTDGs) is challenging, due to the concurrent need to span long node interaction histories and grasp nuanced temporal details. In particular, two problems emerge: (1) Encoding longer histories requires more computational resources, making it crucial for CTDG models to maintain low computational complexity to ensure efficiency; (2) Meanwhile, more powerful models are needed to identify and select the most critical temporal information within the extended context provided by longer histories. To address these problems, we propose a CTDG representation learning model named DyGMamba, originating from the popular Mamba state space model (SSM). DyGMamba first leverages a node-level SSM to encode the sequence of historical node interactions. Another time-level SSM is then employed to exploit the temporal patterns hidden in the historical graph, where its output is used to dynamically select the critical information from the interaction history. We validate DyGMamba experimentally on the dynamic link prediction task. The results show that our model achieves state-of-the-art in most cases. DyGMamba also maintains high efficiency in terms of computational resources, making it possible to capture long temporal dependencies with a limited computation budget.
Picturing Ambiguity: A Visual Twist on the Winograd Schema Challenge
May 28, 2024



Large Language Models (LLMs) have demonstrated remarkable success in tasks like the Winograd Schema Challenge (WSC), showcasing advanced textual common-sense reasoning. However, applying this reasoning to multimodal domains, where understanding text and images together is essential, remains a substantial challenge. To address this, we introduce WinoVis, a novel dataset specifically designed to probe text-to-image models on pronoun disambiguation within multimodal contexts. Utilizing GPT-4 for prompt generation and Diffusion Attentive Attribution Maps (DAAM) for heatmap analysis, we propose a novel evaluation framework that isolates the models' ability in pronoun disambiguation from other visual processing challenges. Evaluation of successive model versions reveals that, despite incremental advancements, Stable Diffusion 2.0 achieves a precision of 56.7% on WinoVis, only marginally surpassing random guessing. Further error analysis identifies important areas for future research aimed at advancing text-to-image models in their ability to interpret and interact with the complex visual world.
Towards Unified Interactive Visual Grounding in The Wild
Jan 30, 2024



Interactive visual grounding in Human-Robot Interaction (HRI) is challenging yet practical due to the inevitable ambiguity in natural languages. It requires robots to disambiguate the user input by active information gathering. Previous approaches often rely on predefined templates to ask disambiguation questions, resulting in performance reduction in realistic interactive scenarios. In this paper, we propose TiO, an end-to-end system for interactive visual grounding in human-robot interaction. Benefiting from a unified formulation of visual dialogue and grounding, our method can be trained on a joint of extensive public data, and show superior generality to diversified and challenging open-world scenarios. In the experiments, we validate TiO on GuessWhat?! and InViG benchmarks, setting new state-of-the-art performance by a clear margin. Moreover, we conduct HRI experiments on the carefully selected 150 challenging scenes as well as real-robot platforms. Results show that our method demonstrates superior generality to diversified visual and language inputs with a high success rate. Codes and demos are available at https://github.com/jxu124/TiO.
Tri-Attention: Explicit Context-Aware Attention Mechanism for Natural Language Processing
Nov 05, 2022



In natural language processing (NLP), the context of a word or sentence plays an essential role. Contextual information such as the semantic representation of a passage or historical dialogue forms an essential part of a conversation and a precise understanding of the present phrase or sentence. However, the standard attention mechanisms typically generate weights using query and key but ignore context, forming a Bi-Attention framework, despite their great success in modeling sequence alignment. This Bi-Attention mechanism does not explicitly model the interactions between the contexts, queries and keys of target sequences, missing important contextual information and resulting in poor attention performance. Accordingly, a novel and general triple-attention (Tri-Attention) framework expands the standard Bi-Attention mechanism and explicitly interacts query, key, and context by incorporating context as the third dimension in calculating relevance scores. Four variants of Tri-Attention are generated by expanding the two-dimensional vector-based additive, dot-product, scaled dot-product, and bilinear operations in Bi-Attention to the tensor operations for Tri-Attention. Extensive experiments on three NLP tasks demonstrate that Tri-Attention outperforms about 30 state-of-the-art non-attention, standard Bi-Attention, contextual Bi-Attention approaches and pretrained neural language models1.
Generative Category-Level Shape and Pose Estimation with Semantic Primitives
Oct 03, 2022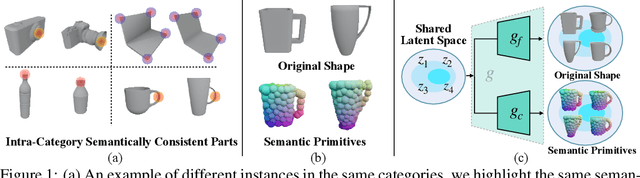
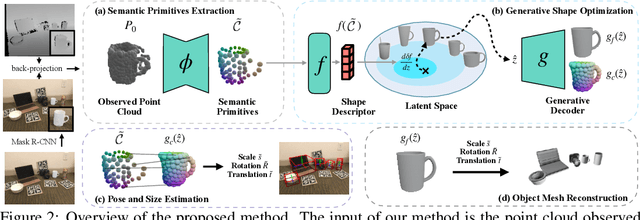
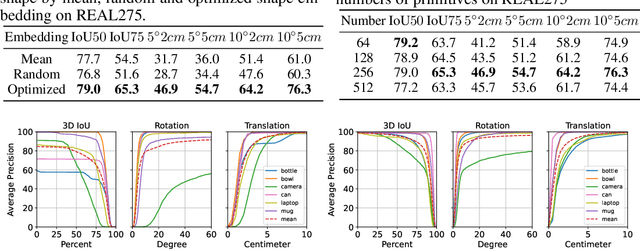

Empowering autonomous agents with 3D understanding for daily objects is a grand challenge in robotics applications. When exploring in an unknown environment, existing methods for object pose estimation are still not satisfactory due to the diversity of object shapes. In this paper, we propose a novel framework for category-level object shape and pose estimation from a single RGB-D image. To handle the intra-category variation, we adopt a semantic primitive representation that encodes diverse shapes into a unified latent space, which is the key to establish reliable correspondences between observed point clouds and estimated shapes. Then, by using a SIM(3)-invariant shape descriptor, we gracefully decouple the shape and pose of an object, thus supporting latent shape optimization of target objects in arbitrary poses. Extensive experiments show that the proposed method achieves SOTA pose estimation performance and better generalization in the real-world dataset. Code and video are available at https://zju3dv.github.io/gCasp
Look Before You Leap: Improving Text-based Person Retrieval by Learning A Consistent Cross-modal Common Manifold
Sep 13, 2022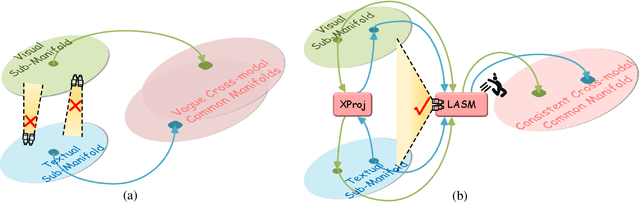
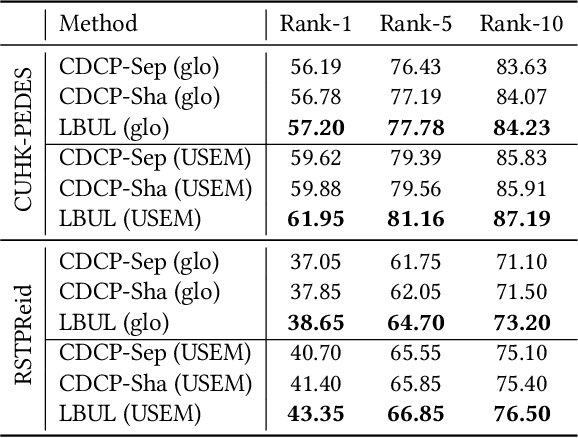
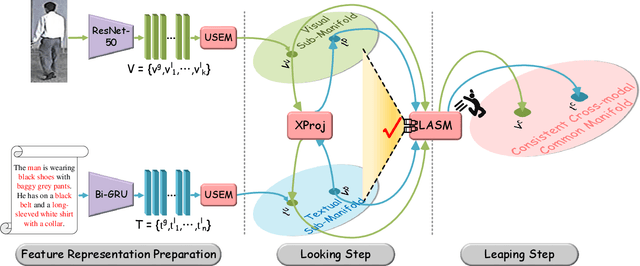
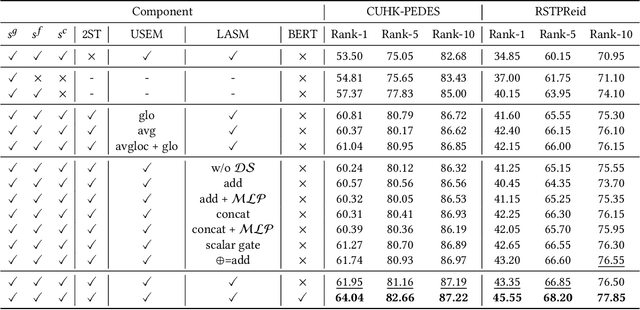
The core problem of text-based person retrieval is how to bridge the heterogeneous gap between multi-modal data. Many previous approaches contrive to learning a latent common manifold mapping paradigm following a \textbf{cross-modal distribution consensus prediction (CDCP)} manner. When mapping features from distribution of one certain modality into the common manifold, feature distribution of the opposite modality is completely invisible. That is to say, how to achieve a cross-modal distribution consensus so as to embed and align the multi-modal features in a constructed cross-modal common manifold all depends on the experience of the model itself, instead of the actual situation. With such methods, it is inevitable that the multi-modal data can not be well aligned in the common manifold, which finally leads to a sub-optimal retrieval performance. To overcome this \textbf{CDCP dilemma}, we propose a novel algorithm termed LBUL to learn a Consistent Cross-modal Common Manifold (C$^{3}$M) for text-based person retrieval. The core idea of our method, just as a Chinese saying goes, is to `\textit{san si er hou xing}', namely, to \textbf{Look Before yoU Leap (LBUL)}. The common manifold mapping mechanism of LBUL contains a looking step and a leaping step. Compared to CDCP-based methods, LBUL considers distribution characteristics of both the visual and textual modalities before embedding data from one certain modality into C$^{3}$M to achieve a more solid cross-modal distribution consensus, and hence achieve a superior retrieval accuracy. We evaluate our proposed method on two text-based person retrieval datasets CUHK-PEDES and RSTPReid. Experimental results demonstrate that the proposed LBUL outperforms previous methods and achieves the state-of-the-art performance.
CAIBC: Capturing All-round Information Beyond Color for Text-based Person Retrieval
Sep 13, 2022
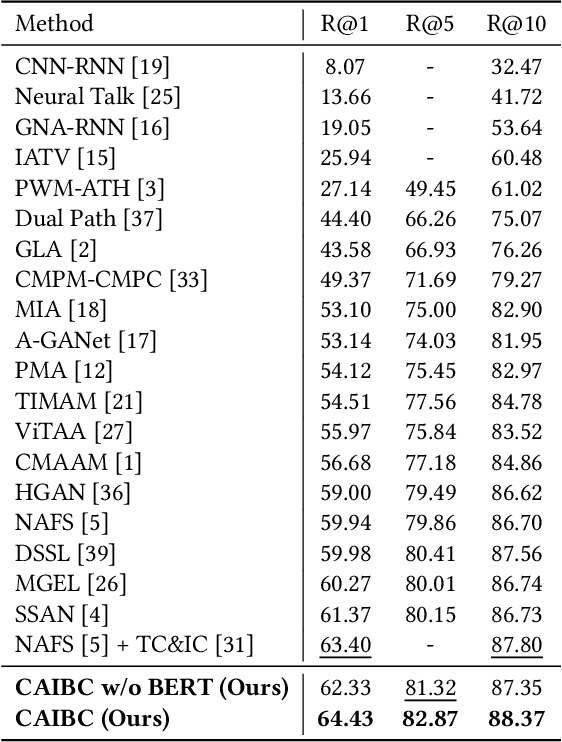
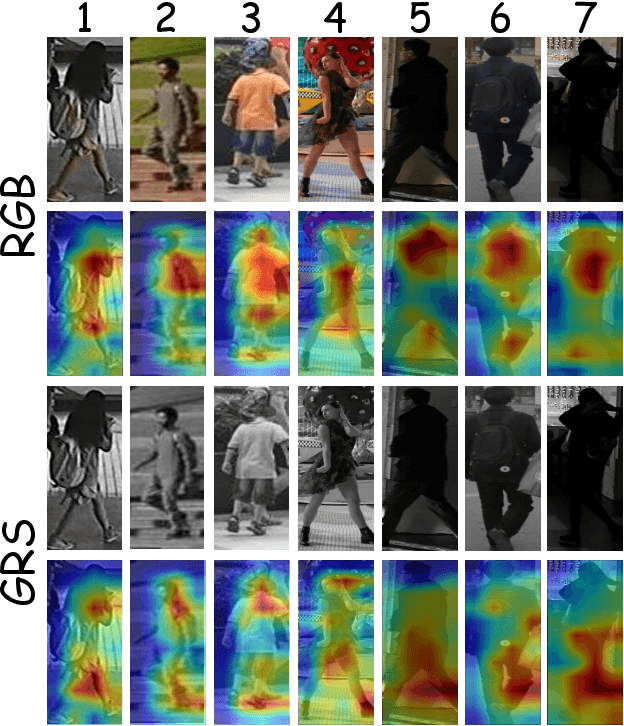
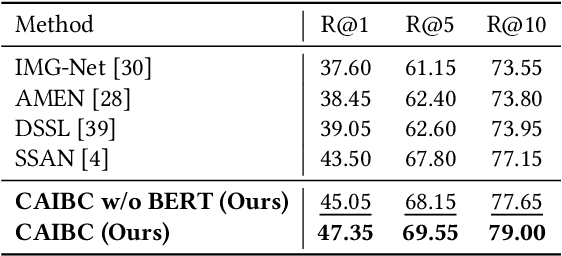
Given a natural language description, text-based person retrieval aims to identify images of a target person from a large-scale person image database. Existing methods generally face a \textbf{color over-reliance problem}, which means that the models rely heavily on color information when matching cross-modal data. Indeed, color information is an important decision-making accordance for retrieval, but the over-reliance on color would distract the model from other key clues (e.g. texture information, structural information, etc.), and thereby lead to a sub-optimal retrieval performance. To solve this problem, in this paper, we propose to \textbf{C}apture \textbf{A}ll-round \textbf{I}nformation \textbf{B}eyond \textbf{C}olor (\textbf{CAIBC}) via a jointly optimized multi-branch architecture for text-based person retrieval. CAIBC contains three branches including an RGB branch, a grayscale (GRS) branch and a color (CLR) branch. Besides, with the aim of making full use of all-round information in a balanced and effective way, a mutual learning mechanism is employed to enable the three branches which attend to varied aspects of information to communicate with and learn from each other. Extensive experimental analysis is carried out to evaluate our proposed CAIBC method on the CUHK-PEDES and RSTPReid datasets in both \textbf{supervised} and \textbf{weakly supervised} text-based person retrieval settings, which demonstrates that CAIBC significantly outperforms existing methods and achieves the state-of-the-art performance on all the three tasks.