 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOASIS: Observation-Action Space Alignment via SE(3) Trajectory Prediction for Robotic Manipulation
May 25, 2026Recent vision-language-action (VLA) models and world action models (WAMs) advance robotic manipulation by enriching intermediate representations with auxiliary spatial features or future visual-state prediction. However, these representations largely remain within the observation space and do not share the rigid-body geometry of the action space, forcing the action decoder to implicitly recover this geometry. We propose OASIS, a visuomotor policy that aligns the intermediate representation with the action space via $SE(3)$ end-effector trajectory prediction. OASIS couples a 3D-aware feature encoder that fuses vision-language and metric-depth features with an $SE(3)$ trajectory predictor that produces a camera-frame end-effector trajectory. Conditioned on the predictor's pose-supervised hidden states, the action decoder generates action chunks consistent with rigid-body motion. Across simulation and real-world experiments, OASIS outperforms VLA and WAM baselines in success rate and out-of-distribution generalization. Our project page is available at https://npuhandsome.github.io/OASIS_web.
AffordSim: A Scalable Data Generator and Benchmark for Affordance-Aware Robotic Manipulation
Apr 13, 2026Simulation-based data generation has become a dominant paradigm for training robotic manipulation policies, yet existing platforms do not incorporate object affordance information into trajectory generation. As a result, tasks requiring precise interaction with specific functional regions--grasping a mug by its handle, pouring from a cup's rim, or hanging a mug on a hook--cannot be automatically generated with semantically correct trajectories. We introduce AffordSim, the first simulation framework that integrates open-vocabulary 3D affordance prediction into the manipulation data generation pipeline. AffordSim uses our VoxAfford model, an open-vocabulary 3D affordance detector that enhances MLLM output tokens with multi-scale geometric features, to predict affordance maps on object point clouds, guiding grasp pose estimation toward task-relevant functional regions. Built on NVIDIA Isaac Sim with cross-embodiment support (Franka FR3, Panda, UR5e, Kinova), VLM-powered task generation, and novel domain randomization using DA3-based 3D Gaussian reconstruction from real photographs, AffordSim enables automated, scalable generation of affordance-aware manipulation data. We establish a benchmark of 50 tasks across 7 categories (grasping, placing, stacking, pushing/pulling, pouring, mug hanging, long-horizon composite) and evaluate 4 imitation learning baselines (BC, Diffusion Policy, ACT, Pi 0.5). Our results reveal that while grasping is largely solved (53-93% success), affordance-demanding tasks such as pouring into narrow containers (1-43%) and mug hanging (0-47%) remain significantly more challenging for current imitation learning methods, highlighting the need for affordance-aware data generation. Zero-shot sim-to-real experiments on a real Franka FR3 validate the transferability of the generated data.
Progressive Refinement Regulation for Accelerating Diffusion Language Model Decoding
Mar 04, 2026Diffusion language models generate text through iterative denoising under a uniform refinement rule applied to all tokens. However, tokens stabilize at different rates in practice, leading to substantial redundant refinement and motivating refinement control over the denoising process. Existing approaches typically assess refinement necessity from instantaneous, step-level signals under a fixed decoding process. In contrast, whether a token has converged is defined by how its prediction changes along its future refinement trajectory. Moreover, changing the refinement rule reshapes future refinement trajectories, which in turn determine how refinement rules should be formulated, making refinement control inherently dynamic. We propose \emph{Progressive Refinement Regulation} (PRR), a progressive, trajectory-grounded refinement control framework that derives a token-level notion of empirical convergence progress from full decoding rollouts. Based on this signal, PRR learns a lightweight token-wise controller to regulate refinement via temperature-based distribution shaping under a progressive self-evolving training scheme. Experiments show that PRR substantially accelerates diffusion language model decoding while preserving generation quality.
Scaling World Model for Hierarchical Manipulation Policies
Feb 12, 2026Vision-Language-Action (VLA) models are promising for generalist robot manipulation but remain brittle in out-of-distribution (OOD) settings, especially with limited real-robot data. To resolve the generalization bottleneck, we introduce a hierarchical Vision-Language-Action framework \our{} that leverages the generalization of large-scale pre-trained world model for robust and generalizable VIsual Subgoal TAsk decomposition VISTA. Our hierarchical framework \our{} consists of a world model as the high-level planner and a VLA as the low-level executor. The high-level world model first divides manipulation tasks into subtask sequences with goal images, and the low-level policy follows the textual and visual guidance to generate action sequences. Compared to raw textual goal specification, these synthesized goal images provide visually and physically grounded details for low-level policies, making it feasible to generalize across unseen objects and novel scenarios. We validate both visual goal synthesis and our hierarchical VLA policies in massive out-of-distribution scenarios, and the performance of the same-structured VLA in novel scenarios could boost from 14% to 69% with the guidance generated by the world model. Results demonstrate that our method outperforms previous baselines with a clear margin, particularly in out-of-distribution scenarios. Project page: \href{https://vista-wm.github.io/}{https://vista-wm.github.io}
Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
Jan 31, 2026Reinforcement learning has shown strong promise for quadrupedal agile locomotion, even with proprioception-only sensing. In practice, however, sim-to-real gap and reward overfitting in complex terrains can produce policies that fail to transfer, while physical validation remains risky and inefficient. To address these challenges, we introduce a unified framework encompassing a Mixture-of-Experts (MoE) locomotion policy for robust multi-terrain representation with RoboGauge, a predictive assessment suite that quantifies sim-to-real transferability. The MoE policy employs a gated set of specialist experts to decompose latent terrain and command modeling, achieving superior deployment robustness and generalization via proprioception alone. RoboGauge further provides multi-dimensional proprioception-based metrics via sim-to-sim tests over terrains, difficulty levels, and domain randomizations, enabling reliable MoE policy selection without extensive physical trials. Experiments on a Unitree Go2 demonstrate robust locomotion on unseen challenging terrains, including snow, sand, stairs, slopes, and 30 cm obstacles. In dedicated high-speed tests, the robot reaches 4 m/s and exhibits an emergent narrow-width gait associated with improved stability at high velocity.
PRISM: Projection-based Reward Integration for Scene-Aware Real-to-Sim-to-Real Transfer with Few Demonstrations
Apr 29, 2025Learning from few demonstrations to develop policies robust to variations in robot initial positions and object poses is a problem of significant practical interest in robotics. Compared to imitation learning, which often struggles to generalize from limited samples, reinforcement learning (RL) can autonomously explore to obtain robust behaviors. Training RL agents through direct interaction with the real world is often impractical and unsafe, while building simulation environments requires extensive manual effort, such as designing scenes and crafting task-specific reward functions. To address these challenges, we propose an integrated real-to-sim-to-real pipeline that constructs simulation environments based on expert demonstrations by identifying scene objects from images and retrieving their corresponding 3D models from existing libraries. We introduce a projection-based reward model for RL policy training that is supervised by a vision-language model (VLM) using human-guided object projection relationships as prompts, with the policy further fine-tuned using expert demonstrations. In general, our work focuses on the construction of simulation environments and RL-based policy training, ultimately enabling the deployment of reliable robotic control policies in real-world scenarios.
Playing Non-Embedded Card-Based Games with Reinforcement Learning
Apr 07, 2025Significant progress has been made in AI for games, including board games, MOBA, and RTS games. However, complex agents are typically developed in an embedded manner, directly accessing game state information, unlike human players who rely on noisy visual data, leading to unfair competition. Developing complex non-embedded agents remains challenging, especially in card-based RTS games with complex features and large state spaces. We propose a non-embedded offline reinforcement learning training strategy using visual inputs to achieve real-time autonomous gameplay in the RTS game Clash Royale. Due to the lack of a object detection dataset for this game, we designed an efficient generative object detection dataset for training. We extract features using state-of-the-art object detection and optical character recognition models. Our method enables real-time image acquisition, perception feature fusion, decision-making, and control on mobile devices, successfully defeating built-in AI opponents. All code is open-sourced at https://github.com/wty-yy/katacr.
* Match videos: https://www.bilibili.com/video/BV1xn4y1R7GQ, All code: https://github.com/wty-yy/katacr, Detection dataset: https://github.com/wty-yy/Clash-Royale-Detection-Dataset, Expert dataset: https://github.com/wty-yy/Clash-Royale-Replay-Dataset
MInCo: Mitigating Information Conflicts in Distracted Visual Model-based Reinforcement Learning
Apr 05, 2025


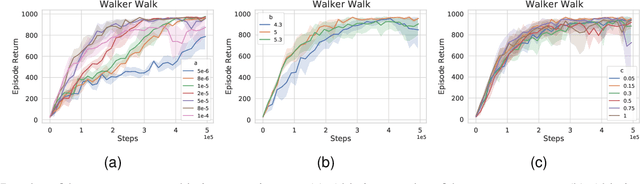
Existing visual model-based reinforcement learning (MBRL) algorithms with observation reconstruction often suffer from information conflicts, making it difficult to learn compact representations and hence result in less robust policies, especially in the presence of task-irrelevant visual distractions. In this paper, we first reveal that the information conflicts in current visual MBRL algorithms stem from visual representation learning and latent dynamics modeling with an information-theoretic perspective. Based on this finding, we present a new algorithm to resolve information conflicts for visual MBRL, named MInCo, which mitigates information conflicts by leveraging negative-free contrastive learning, aiding in learning invariant representation and robust policies despite noisy observations. To prevent the dominance of visual representation learning, we introduce time-varying reweighting to bias the learning towards dynamics modeling as training proceeds. We evaluate our method on several robotic control tasks with dynamic background distractions. Our experiments demonstrate that MInCo learns invariant representations against background noise and consistently outperforms current state-of-the-art visual MBRL methods. Code is available at https://github.com/ShiguangSun/minco.
Bootstrapped Model Predictive Control
Mar 24, 2025



Model Predictive Control (MPC) has been demonstrated to be effective in continuous control tasks. When a world model and a value function are available, planning a sequence of actions ahead of time leads to a better policy. Existing methods typically obtain the value function and the corresponding policy in a model-free manner. However, we find that such an approach struggles with complex tasks, resulting in poor policy learning and inaccurate value estimation. To address this problem, we leverage the strengths of MPC itself. In this work, we introduce Bootstrapped Model Predictive Control (BMPC), a novel algorithm that performs policy learning in a bootstrapped manner. BMPC learns a network policy by imitating an MPC expert, and in turn, uses this policy to guide the MPC process. Combined with model-based TD-learning, our policy learning yields better value estimation and further boosts the efficiency of MPC. We also introduce a lazy reanalyze mechanism, which enables computationally efficient imitation learning. Our method achieves superior performance over prior works on diverse continuous control tasks. In particular, on challenging high-dimensional locomotion tasks, BMPC significantly improves data efficiency while also enhancing asymptotic performance and training stability, with comparable training time and smaller network sizes. Code is available at https://github.com/wertyuilife2/bmpc.
Enhancing Decision Transformer with Diffusion-Based Trajectory Branch Generation
Nov 18, 2024



Decision Transformer (DT) can learn effective policy from offline datasets by converting the offline reinforcement learning (RL) into a supervised sequence modeling task, where the trajectory elements are generated auto-regressively conditioned on the return-to-go (RTG).However, the sequence modeling learning approach tends to learn policies that converge on the sub-optimal trajectories within the dataset, for lack of bridging data to move to better trajectories, even if the condition is set to the highest RTG.To address this issue, we introduce Diffusion-Based Trajectory Branch Generation (BG), which expands the trajectories of the dataset with branches generated by a diffusion model.The trajectory branch is generated based on the segment of the trajectory within the dataset, and leads to trajectories with higher returns.We concatenate the generated branch with the trajectory segment as an expansion of the trajectory.After expanding, DT has more opportunities to learn policies to move to better trajectories, preventing it from converging to the sub-optimal trajectories.Empirically, after processing with BG, DT outperforms state-of-the-art sequence modeling methods on D4RL benchmark, demonstrating the effectiveness of adding branches to the dataset without further modifications.