 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Robotic Policy Learning via Human-assisted Action Preference Optimization
Jun 08, 2025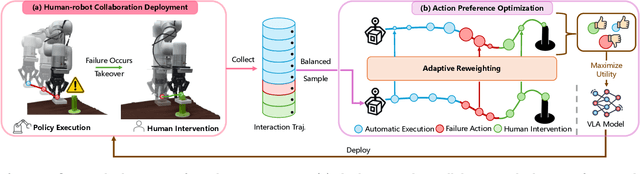



Establishing a reliable and iteratively refined robotic system is essential for deploying real-world applications. While Vision-Language-Action (VLA) models are widely recognized as the foundation model for such robotic deployment, their dependence on expert demonstrations hinders the crucial capabilities of correction and learning from failures. To mitigate this limitation, we introduce a Human-assisted Action Preference Optimization method named HAPO, designed to correct deployment failures and foster effective adaptation through preference alignment for VLA models. This method begins with a human-robot collaboration framework for reliable failure correction and interaction trajectory collection through human intervention. These human-intervention trajectories are further employed within the action preference optimization process, facilitating VLA models to mitigate failure action occurrences while enhancing corrective action adaptation. Specifically, we propose an adaptive reweighting algorithm to address the issues of irreversible interactions and token probability mismatch when introducing preference optimization into VLA models, facilitating model learning from binary desirability signals derived from interactions. Through combining these modules, our human-assisted action preference optimization method ensures reliable deployment and effective learning from failure for VLA models. The experiments conducted in simulation and real-world scenarios prove superior generalization and robustness of our framework across a variety of manipulation tasks.
State Estimation Transformers for Agile Legged Locomotion
Oct 17, 2024



We propose a state estimation method that can accurately predict the robot's privileged states to push the limits of quadruped robots in executing advanced skills such as jumping in the wild. In particular, we present the State Estimation Transformers (SET), an architecture that casts the state estimation problem as conditional sequence modeling. SET outputs the robot states that are hard to obtain directly in the real world, such as the body height and velocities, by leveraging a causally masked Transformer. By conditioning an autoregressive model on the robot's past states, our SET model can predict these privileged observations accurately even in highly dynamic locomotions. We evaluate our methods on three tasks -- running jumping, running backflipping, and running sideslipping -- on a low-cost quadruped robot, Cyberdog2. Results show that SET can outperform other methods in estimation accuracy and transferability in the simulation as well as success rates of jumping and triggering a recovery controller in the real world, suggesting the superiority of such a Transformer-based explicit state estimator in highly dynamic locomotion tasks.
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Oct 08, 2024



We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.