 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Geometry-aware Transformer for accurate 3D Atomic System modeling
Feb 02, 2023



Molecular dynamic simulations are important in computational physics, chemistry, material, and biology. Machine learning-based methods have shown strong abilities in predicting molecular energy and properties and are much faster than DFT calculations. Molecular energy is at least related to atoms, bonds, bond angles, torsion angles, and nonbonding atom pairs. Previous Transformer models only use atoms as inputs which lack explicit modeling of the aforementioned factors. To alleviate this limitation, we propose Moleformer, a novel Transformer architecture that takes nodes (atoms) and edges (bonds and nonbonding atom pairs) as inputs and models the interactions among them using rotational and translational invariant geometry-aware spatial encoding. Proposed spatial encoding calculates relative position information including distances and angles among nodes and edges. We benchmark Moleformer on OC20 and QM9 datasets, and our model achieves state-of-the-art on the initial state to relaxed energy prediction of OC20 and is very competitive in QM9 on predicting quantum chemical properties compared to other Transformer and Graph Neural Network (GNN) methods which proves the effectiveness of the proposed geometry-aware spatial encoding in Moleformer.
mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
Feb 01, 2023



Recent years have witnessed a big convergence of language, vision, and multi-modal pretraining. In this work, we present mPLUG-2, a new unified paradigm with modularized design for multi-modal pretraining, which can benefit from modality collaboration while addressing the problem of modality entanglement. In contrast to predominant paradigms of solely relying on sequence-to-sequence generation or encoder-based instance discrimination, mPLUG-2 introduces a multi-module composition network by sharing common universal modules for modality collaboration and disentangling different modality modules to deal with modality entanglement. It is flexible to select different modules for different understanding and generation tasks across all modalities including text, image, and video. Empirical study shows that mPLUG-2 achieves state-of-the-art or competitive results on a broad range of over 30 downstream tasks, spanning multi-modal tasks of image-text and video-text understanding and generation, and uni-modal tasks of text-only, image-only, and video-only understanding. Notably, mPLUG-2 shows new state-of-the-art results of 48.0 top-1 accuracy and 80.3 CIDEr on the challenging MSRVTT video QA and video caption tasks with a far smaller model size and data scale. It also demonstrates strong zero-shot transferability on vision-language and video-language tasks. Code and models will be released in https://github.com/alibaba/AliceMind.
Learning Trajectory-Word Alignments for Video-Language Tasks
Jan 06, 2023



Aligning objects with words plays a critical role in Image-Language BERT (IL-BERT) and Video-Language BERT (VDL-BERT). Different from the image case where an object covers some spatial patches, an object in a video usually appears as an object trajectory, i.e., it spans over a few spatial but longer temporal patches and thus contains abundant spatiotemporal contexts. However, modern VDL-BERTs neglect this trajectory characteristic that they usually follow IL-BERTs to deploy the patch-to-word (P2W) attention while such attention may over-exploit trivial spatial contexts and neglect significant temporal contexts. To amend this, we propose a novel TW-BERT to learn Trajectory-Word alignment for solving video-language tasks. Such alignment is learned by a newly designed trajectory-to-word (T2W) attention. Besides T2W attention, we also follow previous VDL-BERTs to set a word-to-patch (W2P) attention in the cross-modal encoder. Since T2W and W2P attentions have diverse structures, our cross-modal encoder is asymmetric. To further help this asymmetric cross-modal encoder build robust vision-language associations, we propose a fine-grained ``align-before-fuse'' strategy to pull close the embedding spaces calculated by the video and text encoders. By the proposed strategy and T2W attention, our TW-BERT achieves SOTA performances on text-to-video retrieval tasks, and comparable performances on video question answering tasks with some VDL-BERTs trained on much more data. The code will be available in the supplementary material.
Adaptively Clustering Neighbor Elements for Image Captioning
Jan 05, 2023We design a novel global-local Transformer named \textbf{Ada-ClustFormer} (\textbf{ACF}) to generate captions. We use this name since each layer of ACF can adaptively cluster input elements to carry self-attention (Self-ATT) for learning local context. Compared with other global-local Transformers which carry Self-ATT in fixed-size windows, ACF can capture varying graininess, \eg, an object may cover different numbers of grids or a phrase may contain diverse numbers of words. To build ACF, we insert a probabilistic matrix C into the Self-ATT layer. For an input sequence {{s}_1,...,{s}_N , C_{i,j} softly determines whether the sub-sequence {s_i,...,s_j} should be clustered for carrying Self-ATT. For implementation, {C}_{i,j} is calculated from the contexts of {{s}_i,...,{s}_j}, thus ACF can exploit the input itself to decide which local contexts should be learned. By using ACF to build the vision encoder and language decoder, the captioning model can automatically discover the hidden structures in both vision and language, which encourages the model to learn a unified structural space for transferring more structural commonalities. The experiment results demonstrate the effectiveness of ACF that we achieve CIDEr of 137.8, which outperforms most SOTA captioning models and achieve comparable scores compared with some BERT-based models. The code will be available in the supplementary material.
SeqDiffuSeq: Text Diffusion with Encoder-Decoder Transformers
Dec 20, 2022



Diffusion model, a new generative modelling paradigm, has achieved great success in image, audio, and video generation. However, considering the discrete categorical nature of text, it is not trivial to extend continuous diffusion models to natural language, and text diffusion models are less studied. Sequence-to-sequence text generation is one of the essential natural language processing topics. In this work, we apply diffusion models to approach sequence-to-sequence text generation, and explore whether the superiority generation performance of diffusion model can transfer to natural language domain. We propose SeqDiffuSeq, a text diffusion model for sequence-to-sequence generation. SeqDiffuSeq uses an encoder-decoder Transformers architecture to model denoising function. In order to improve generation quality, SeqDiffuSeq combines the self-conditioning technique and a newly proposed adaptive noise schedule technique. The adaptive noise schedule has the difficulty of denoising evenly distributed across time steps, and considers exclusive noise schedules for tokens at different positional order. Experiment results illustrate the good performance on sequence-to-sequence generation in terms of text quality and inference time.
HyPe: Better Pre-trained Language Model Fine-tuning with Hidden Representation Perturbation
Dec 17, 2022Language models with the Transformers structure have shown great performance in natural language processing. However, there still poses problems when fine-tuning pre-trained language models on downstream tasks, such as over-fitting or representation collapse. In this work, we propose HyPe, a simple yet effective fine-tuning technique to alleviate such problems by perturbing hidden representations of Transformers layers. Unlike previous works that only add noise to inputs or parameters, we argue that the hidden representations of Transformers layers convey more diverse and meaningful language information. Therefore, making the Transformers layers more robust to hidden representation perturbations can further benefit the fine-tuning of PLMs en bloc. We conduct extensive experiments and analyses on GLUE and other natural language inference datasets. Results demonstrate that HyPe outperforms vanilla fine-tuning and enhances generalization of hidden representations from different layers. In addition, HyPe acquires negligible computational overheads, and is better than and compatible with previous state-of-the-art fine-tuning techniques.
SpanProto: A Two-stage Span-based Prototypical Network for Few-shot Named Entity Recognition
Oct 17, 2022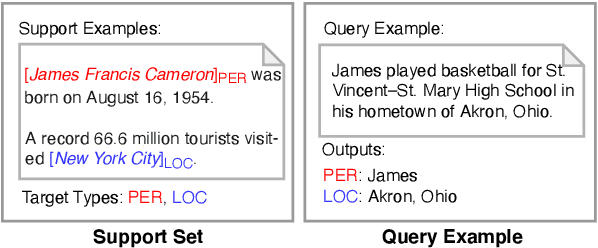
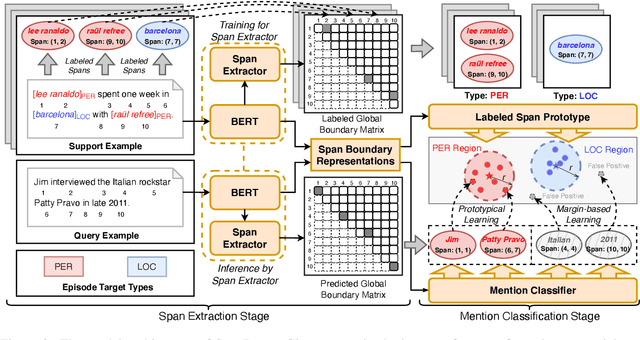
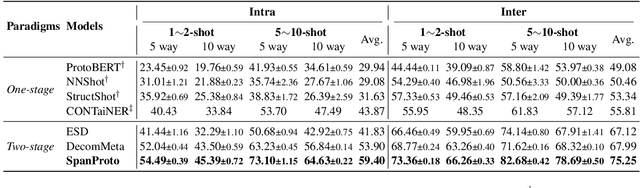
Few-shot Named Entity Recognition (NER) aims to identify named entities with very little annotated data. Previous methods solve this problem based on token-wise classification, which ignores the information of entity boundaries, and inevitably the performance is affected by the massive non-entity tokens. To this end, we propose a seminal span-based prototypical network (SpanProto) that tackles few-shot NER via a two-stage approach, including span extraction and mention classification. In the span extraction stage, we transform the sequential tags into a global boundary matrix, enabling the model to focus on the explicit boundary information. For mention classification, we leverage prototypical learning to capture the semantic representations for each labeled span and make the model better adapt to novel-class entities. To further improve the model performance, we split out the false positives generated by the span extractor but not labeled in the current episode set, and then present a margin-based loss to separate them from each prototype region. Experiments over multiple benchmarks demonstrate that our model outperforms strong baselines by a large margin.
Open Information Extraction from 2007 to 2022 -- A Survey
Aug 18, 2022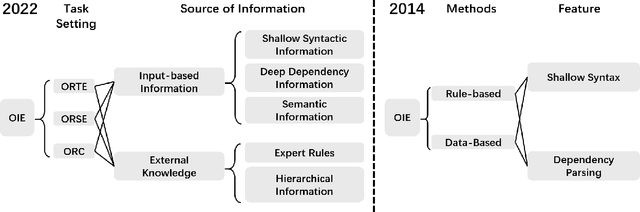
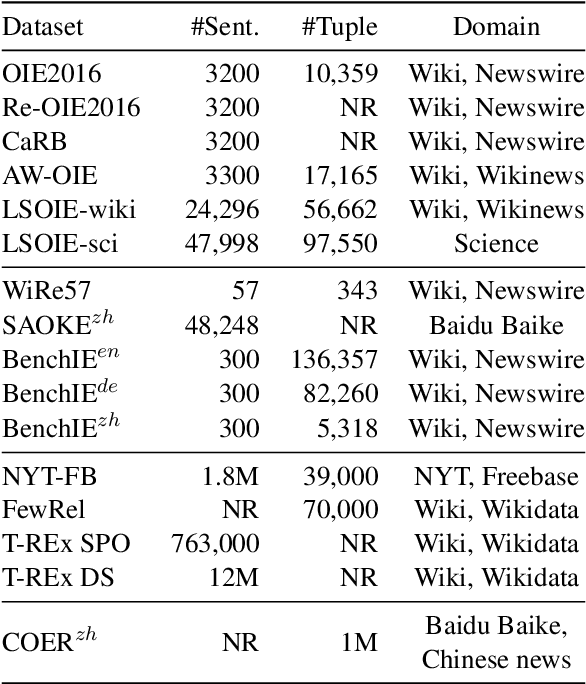
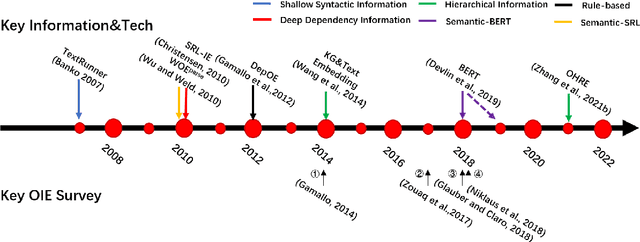
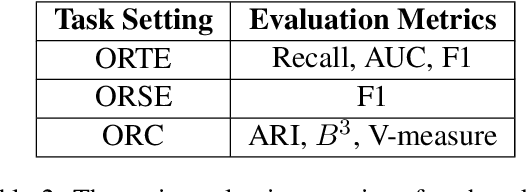
Open information extraction is an important NLP task that targets extracting structured information from unstructured text without limitations on the relation type or the domain of the text. This survey paper covers open information extraction technologies from 2007 to 2022 with a focus on new models not covered by previous surveys. We propose a new categorization method from the source of information perspective to accommodate the development of recent OIE technologies. In addition, we summarize three major approaches based on task settings as well as current popular datasets and model evaluation metrics. Given the comprehensive review, several future directions are shown from datasets, source of information, output form, method, and evaluation metric aspects.
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 25, 2022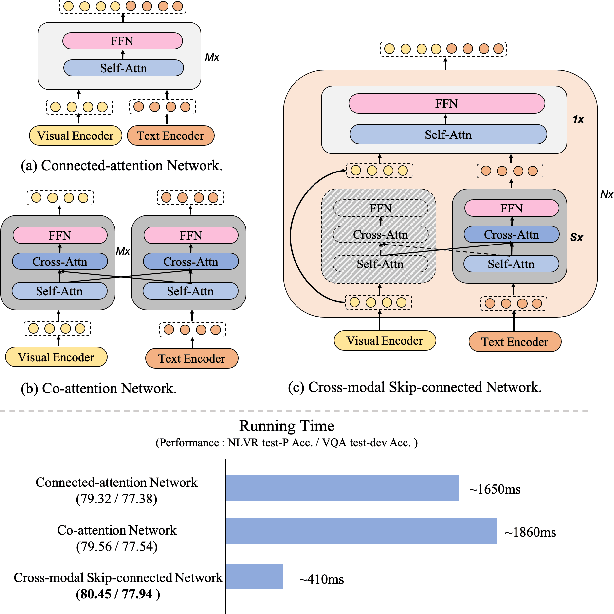
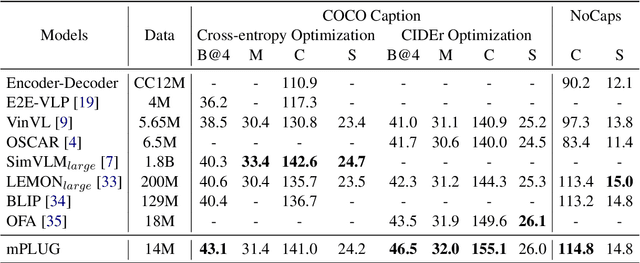
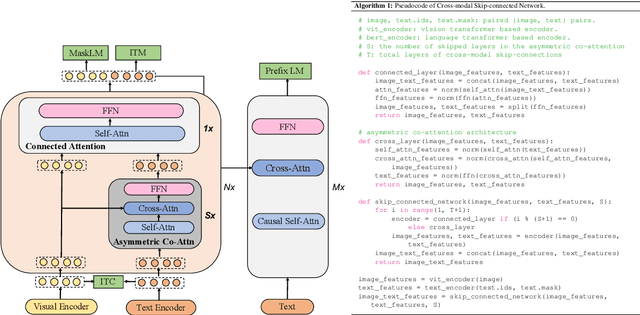
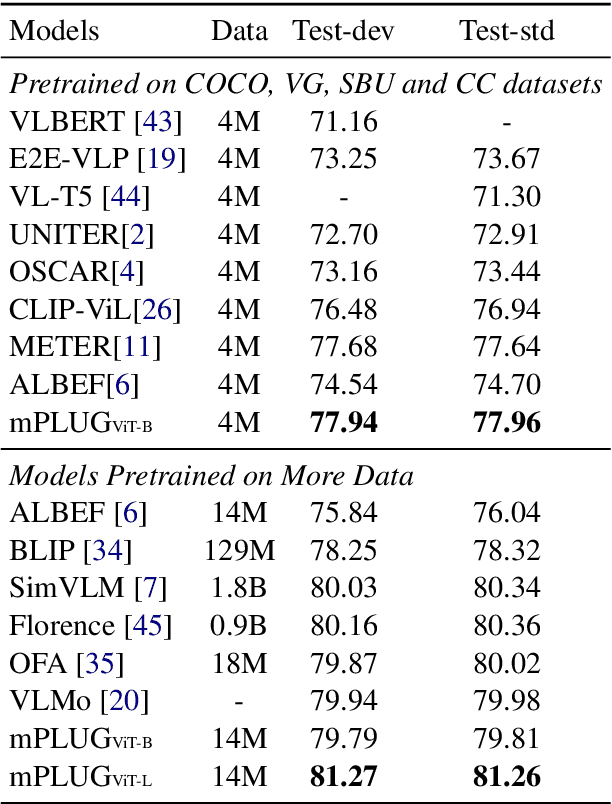
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
Parameter-Efficient Sparsity for Large Language Models Fine-Tuning
May 23, 2022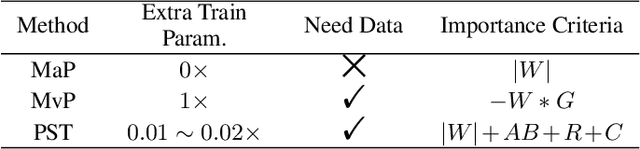
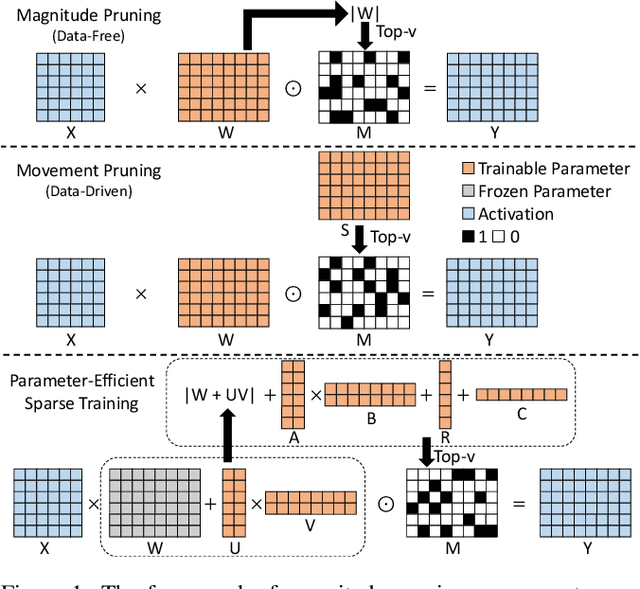
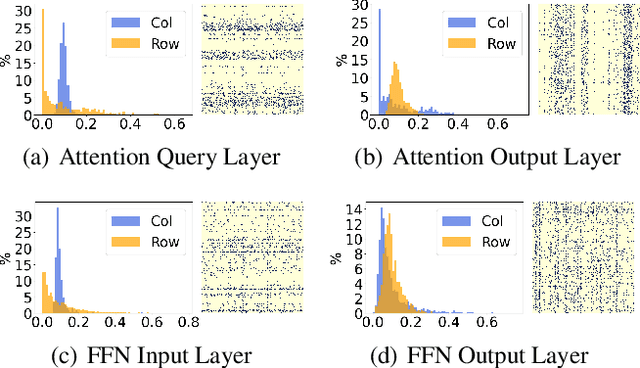
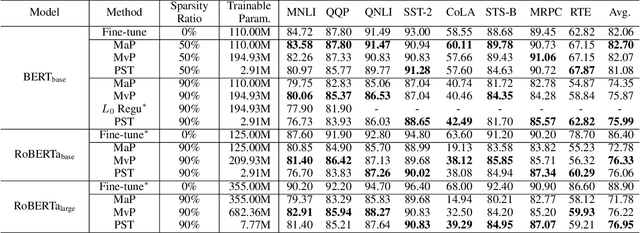
With the dramatically increased number of parameters in language models, sparsity methods have received ever-increasing research focus to compress and accelerate the models. While most research focuses on how to accurately retain appropriate weights while maintaining the performance of the compressed model, there are challenges in the computational overhead and memory footprint of sparse training when compressing large-scale language models. To address this problem, we propose a Parameter-efficient Sparse Training (PST) method to reduce the number of trainable parameters during sparse-aware training in downstream tasks. Specifically, we first combine the data-free and data-driven criteria to efficiently and accurately measure the importance of weights. Then we investigate the intrinsic redundancy of data-driven weight importance and derive two obvious characteristics i.e., low-rankness and structuredness. Based on that, two groups of small matrices are introduced to compute the data-driven importance of weights, instead of using the original large importance score matrix, which therefore makes the sparse training resource-efficient and parameter-efficient. Experiments with diverse networks (i.e., BERT, RoBERTa and GPT-2) on dozens of datasets demonstrate PST performs on par or better than previous sparsity methods, despite only training a small number of parameters. For instance, compared with previous sparsity methods, our PST only requires 1.5% trainable parameters to achieve comparable performance on BERT.