 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Optimization for UAV-Based Medical Delivery with Temporal Logic Constraints and Convex Feasible Set Collision Avoidance
Jun 06, 2025This paper addresses the problem of trajectory optimization for unmanned aerial vehicles (UAVs) performing time-sensitive medical deliveries in urban environments. Specifically, we consider a single UAV with 3 degree-of-freedom dynamics tasked with delivering blood packages to multiple hospitals, each with a predefined time window and priority. Mission objectives are encoded using Signal Temporal Logic (STL), enabling the formal specification of spatial-temporal constraints. To ensure safety, city buildings are modeled as 3D convex obstacles, and obstacle avoidance is handled through a Convex Feasible Set (CFS) method. The entire planning problem-combining UAV dynamics, STL satisfaction, and collision avoidance-is formulated as a convex optimization problem that ensures tractability and can be solved efficiently using standard convex programming techniques. Simulation results demonstrate that the proposed method generates dynamically feasible, collision-free trajectories that satisfy temporal mission goals, providing a scalable and reliable approach for autonomous UAV-based medical logistics.
A*-Thought: Efficient Reasoning via Bidirectional Compression for Low-Resource Settings
May 30, 2025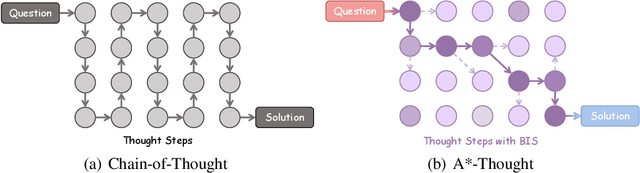
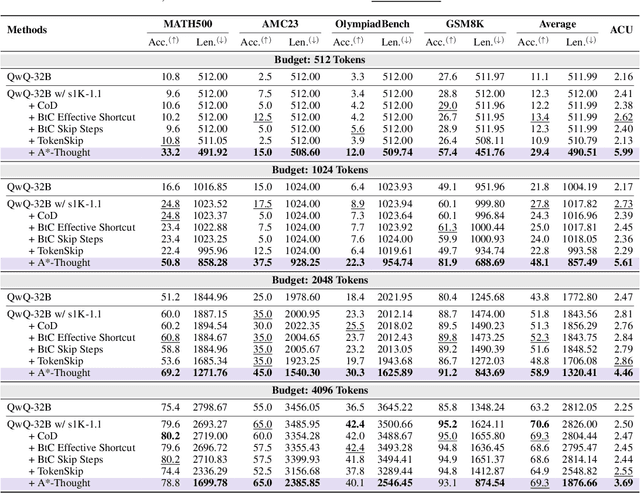
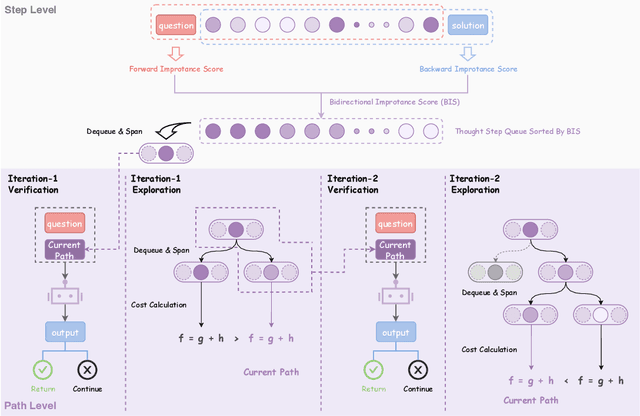

Large Reasoning Models (LRMs) achieve superior performance by extending the thought length. However, a lengthy thinking trajectory leads to reduced efficiency. Most of the existing methods are stuck in the assumption of overthinking and attempt to reason efficiently by compressing the Chain-of-Thought, but this often leads to performance degradation. To address this problem, we introduce A*-Thought, an efficient tree search-based unified framework designed to identify and isolate the most essential thoughts from the extensive reasoning chains produced by these models. It formulates the reasoning process of LRMs as a search tree, where each node represents a reasoning span in the giant reasoning space. By combining the A* search algorithm with a cost function specific to the reasoning path, it can efficiently compress the chain of thought and determine a reasoning path with high information density and low cost. In addition, we also propose a bidirectional importance estimation mechanism, which further refines this search process and enhances its efficiency beyond uniform sampling. Extensive experiments on several advanced math tasks show that A*-Thought effectively balances performance and efficiency over a huge search space. Specifically, A*-Thought can improve the performance of QwQ-32B by 2.39$\times$ with low-budget and reduce the length of the output token by nearly 50% with high-budget. The proposed method is also compatible with several other LRMs, demonstrating its generalization capability. The code can be accessed at: https://github.com/AI9Stars/AStar-Thought.
ConsRec: Denoising Sequential Recommendation through User-Consistent Preference Modeling
May 28, 2025User-item interaction histories are pivotal for sequential recommendation systems but often include noise, such as unintended clicks or actions that fail to reflect genuine user preferences. To address this issue, we propose the User-Consistent Preference-based Sequential Recommendation System (ConsRec), designed to capture stable user preferences and filter noisy items from interaction histories. Specifically, ConsRec constructs a user-interacted item graph, learns item similarities from their text representations, and then extracts the maximum connected subgraph from the user-interacted item graph for denoising items. Experimental results on the Yelp and Amazon Product datasets illustrate that ConsRec achieves a 13% improvement over baseline recommendation models, showing its effectiveness in denoising user-interacted items. Further analysis reveals that the denoised interaction histories form semantically tighter clusters of user-preferred items, leading to higher relevance scores for ground-truth targets and more accurate recommendations. All codes are available at https://github.com/NEUIR/ConsRec.
Cooperation of Experts: Fusing Heterogeneous Information with Large Margin
May 28, 2025Fusing heterogeneous information remains a persistent challenge in modern data analysis. While significant progress has been made, existing approaches often fail to account for the inherent heterogeneity of object patterns across different semantic spaces. To address this limitation, we propose the Cooperation of Experts (CoE) framework, which encodes multi-typed information into unified heterogeneous multiplex networks. By overcoming modality and connection differences, CoE provides a powerful and flexible model for capturing the intricate structures of real-world complex data. In our framework, dedicated encoders act as domain-specific experts, each specializing in learning distinct relational patterns in specific semantic spaces. To enhance robustness and extract complementary knowledge, these experts collaborate through a novel large margin mechanism supported by a tailored optimization strategy. Rigorous theoretical analyses guarantee the framework's feasibility and stability, while extensive experiments across diverse benchmarks demonstrate its superior performance and broad applicability. Our code is available at https://github.com/strangeAlan/CoE.
Learning to Route Queries Across Knowledge Bases for Step-wise Retrieval-Augmented Reasoning
May 28, 2025



Multimodal Retrieval-Augmented Generation (MRAG) has shown promise in mitigating hallucinations in Multimodal Large Language Models (MLLMs) by incorporating external knowledge during generation. Existing MRAG methods typically adopt a static retrieval pipeline that fetches relevant information from multiple Knowledge Bases (KBs), followed by a refinement step. However, these approaches overlook the reasoning and planning capabilities of MLLMs to dynamically determine how to interact with different KBs during the reasoning process. To address this limitation, we propose R1-Router, a novel MRAG framework that learns to decide when and where to retrieve knowledge based on the evolving reasoning state. Specifically, R1-Router can generate follow-up queries according to the current reasoning step, routing these intermediate queries to the most suitable KB, and integrating external knowledge into a coherent reasoning trajectory to answer the original query. Furthermore, we introduce Step-wise Group Relative Policy Optimization (Step-GRPO), a tailored reinforcement learning algorithm that assigns step-specific rewards to optimize the reasoning behavior of MLLMs. Experimental results on various open-domain QA benchmarks across multiple modalities demonstrate that R1-Router outperforms baseline models by over 7%. Further analysis shows that R1-Router can adaptively and effectively leverage diverse KBs, reducing unnecessary retrievals and improving both efficiency and accuracy.
AutoReproduce: Automatic AI Experiment Reproduction with Paper Lineage
May 27, 2025Efficient experiment reproduction is critical to accelerating progress in artificial intelligence. However, the inherent complexity of method design and training procedures presents substantial challenges for automation. Notably, reproducing experiments often requires implicit domain-specific knowledge not explicitly documented in the original papers. To address this, we introduce the paper lineage algorithm, which identifies and extracts implicit knowledge from the relevant references cited by the target paper. Building on this idea, we propose AutoReproduce, a multi-agent framework capable of automatically reproducing experiments described in research papers in an end-to-end manner. AutoReproduce enhances code executability by generating unit tests alongside the reproduction process. To evaluate the reproduction capability, we construct ReproduceBench, a benchmark annotated with verified implementations, and introduce novel evaluation metrics to assess both the reproduction and execution fidelity. Experimental results demonstrate that AutoReproduce outperforms the existing strong agent baselines on all five evaluation metrics by a peak margin of over $70\%$. In particular, compared to the official implementations, AutoReproduce achieves an average performance gap of $22.1\%$ on $89.74\%$ of the executable experiment runs. The code will be available at https://github.com/AI9Stars/AutoReproduce.
Monocle: Hybrid Local-Global In-Context Evaluation for Long-Text Generation with Uncertainty-Based Active Learning
May 27, 2025Assessing the quality of long-form, model-generated text is challenging, even with advanced LLM-as-a-Judge methods, due to performance degradation as input length increases. To address this issue, we propose a divide-and-conquer approach, which breaks down the comprehensive evaluation task into a series of localized scoring tasks, followed by a final global assessment. This strategy allows for more granular and manageable evaluations, ensuring that each segment of the text is assessed in isolation for both coherence and quality, while also accounting for the overall structure and consistency of the entire piece. Moreover, we introduce a hybrid in-context learning approach that leverages human annotations to enhance the performance of both local and global evaluations. By incorporating human-generated feedback directly into the evaluation process, this method allows the model to better align with human judgment. Finally, we develop an uncertainty-based active learning algorithm that efficiently selects data samples for human annotation, thereby reducing annotation costs in practical scenarios. Experimental results show that the proposed evaluation framework outperforms several representative baselines, highlighting the effectiveness of our approach.
PCDCNet: A Surrogate Model for Air Quality Forecasting with Physical-Chemical Dynamics and Constraints
May 26, 2025Air quality forecasting (AQF) is critical for public health and environmental management, yet remains challenging due to the complex interplay of emissions, meteorology, and chemical transformations. Traditional numerical models, such as CMAQ and WRF-Chem, provide physically grounded simulations but are computationally expensive and rely on uncertain emission inventories. Deep learning models, while computationally efficient, often struggle with generalization due to their lack of physical constraints. To bridge this gap, we propose PCDCNet, a surrogate model that integrates numerical modeling principles with deep learning. PCDCNet explicitly incorporates emissions, meteorological influences, and domain-informed constraints to model pollutant formation, transport, and dissipation. By combining graph-based spatial transport modeling, recurrent structures for temporal accumulation, and representation enhancement for local interactions, PCDCNet achieves state-of-the-art (SOTA) performance in 72-hour station-level PM2.5 and O3 forecasting while significantly reducing computational costs. Furthermore, our model is deployed in an online platform, providing free, real-time air quality forecasts, demonstrating its scalability and societal impact. By aligning deep learning with physical consistency, PCDCNet offers a practical and interpretable solution for AQF, enabling informed decision-making for both personal and regulatory applications.
A Survey of LLM $\times$ DATA
May 24, 2025The integration of large language model (LLM) and data management (DATA) is rapidly redefining both domains. In this survey, we comprehensively review the bidirectional relationships. On the one hand, DATA4LLM, spanning large-scale data processing, storage, and serving, feeds LLMs with high quality, diversity, and timeliness of data required for stages like pre-training, post-training, retrieval-augmented generation, and agentic workflows: (i) Data processing for LLMs includes scalable acquisition, deduplication, filtering, selection, domain mixing, and synthetic augmentation; (ii) Data Storage for LLMs focuses on efficient data and model formats, distributed and heterogeneous storage hierarchies, KV-cache management, and fault-tolerant checkpointing; (iii) Data serving for LLMs tackles challenges in RAG (e.g., knowledge post-processing), LLM inference (e.g., prompt compression, data provenance), and training strategies (e.g., data packing and shuffling). On the other hand, in LLM4DATA, LLMs are emerging as general-purpose engines for data management. We review recent advances in (i) data manipulation, including automatic data cleaning, integration, discovery; (ii) data analysis, covering reasoning over structured, semi-structured, and unstructured data, and (iii) system optimization (e.g., configuration tuning, query rewriting, anomaly diagnosis), powered by LLM techniques like retrieval-augmented prompting, task-specialized fine-tuning, and multi-agent collaboration.
Shadows in the Attention: Contextual Perturbation and Representation Drift in the Dynamics of Hallucination in LLMs
May 22, 2025



Hallucinations -- plausible yet erroneous outputs -- remain a critical barrier to reliable deployment of large language models (LLMs). We present the first systematic study linking hallucination incidence to internal-state drift induced by incremental context injection. Using TruthfulQA, we construct two 16-round "titration" tracks per question: one appends relevant but partially flawed snippets, the other injects deliberately misleading content. Across six open-source LLMs, we track overt hallucination rates with a tri-perspective detector and covert dynamics via cosine, entropy, JS and Spearman drifts of hidden states and attention maps. Results reveal (1) monotonic growth of hallucination frequency and representation drift that plateaus after 5--7 rounds; (2) relevant context drives deeper semantic assimilation, producing high-confidence "self-consistent" hallucinations, whereas irrelevant context induces topic-drift errors anchored by attention re-routing; and (3) convergence of JS-Drift ($\sim0.69$) and Spearman-Drift ($\sim0$) marks an "attention-locking" threshold beyond which hallucinations solidify and become resistant to correction. Correlation analyses expose a seesaw between assimilation capacity and attention diffusion, clarifying size-dependent error modes. These findings supply empirical foundations for intrinsic hallucination prediction and context-aware mitigation mechanisms.