 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverAge: Reliable Pluralistic Face Aging with Cross-Age Identity Relation Guidance
Jun 02, 2026Face aging plays an important role in long-term biometric analysis, cross-age identity verification, and forensic identity analysis. Since the same subject may exhibit multiple plausible appearances at a target age due to genetic, environmental, and lifestyle factors, face aging is inherently a one-to-many generation problem. However, pluralism alone is insufficient for reliable face aging: a model should provide appearance-level candidate diversity within each age group while maintaining sequence-level ordinal reliability across ordered age groups. Existing deterministic aging methods can synthesize visually plausible age-progressed faces, but usually lack stochastic diversity. In contrast, pluralistic aging methods introduce local appearance variations, but often fail to explicitly regulate the identity evolution of the full aging sequence. In this paper, we propose \textbf{DiverAge}, a hierarchical pluralistic face aging framework based on diffusion autoencoding. DiverAge preserves appearance-level diversity through stochastic diffusion decoding and age-conditioned semantic modulation. To improve sequence-level reliability, we introduce a Cross-age Identity Relation Regulator (CARR), an inference-time guidance strategy that jointly denoises multiple target age groups. CARR is guided by a Cross-age Identity Similarity (CIS) prior estimated from real same-identity cross-age pairs, and suppresses excessive cross-age identity drift through one-sided sampling-time guidance without modifying the training objective or introducing extra trainable parameters. Experiments demonstrate that DiverAge improves sequence-level ordinal reliability while maintaining identity preservation, age accuracy, image quality, and appearance-level diversity.
MERLIN: Building Low-SNR Robust Multimodal LLMs for Electromagnetic Signals
Mar 09, 2026The paradigm of Multimodal Large Language Models (MLLMs) offers a promising blueprint for advancing the electromagnetic (EM) domain. However, prevailing approaches often deviate from the native MLLM paradigm, instead using task-specific or pipelined architectures that lead to fundamental limitations in model performance and generalization. Fully realizing the MLLM potential in EM domain requires overcoming three main challenges: (1) Data. The scarcity of high-quality datasets with paired EM signals and descriptive text annotations used for MLLMs pre-training; (2) Benchmark. The absence of comprehensive benchmarks to systematically evaluate and compare the performance of models on EM signal-to-text tasks; (3) Model. A critical fragility in low Signal-to-Noise Ratio (SNR) environments, where critical signal features can be obscured, leading to significant performance degradation. To address these challenges, we introduce a tripartite contribution to establish a foundation for MLLMs in the EM domain. First, to overcome data scarcity, we construct and release EM-100k, a large-scale dataset comprising over 100,000 EM signal-text pairs. Second, to enable rigorous and standardized evaluation, we propose EM-Bench, the most comprehensive benchmark featuring diverse downstream tasks spanning from perception to reasoning. Finally, to tackle the core modeling challenge, we present MERLIN, a novel training framework designed not only to align low-level signal representations with high-level semantic text, but also to explicitly enhance model robustness and performance in challenging low-SNR environments. Comprehensive experiments validate our method, showing that MERLIN is state-of-the-art in the EM-Bench and exhibits remarkable robustness in low-SNR settings.
AgentHallu: Benchmarking Automated Hallucination Attribution of LLM-based Agents
Jan 11, 2026As LLM-based agents operate over sequential multi-step reasoning, hallucinations arising at intermediate steps risk propagating along the trajectory, thus degrading overall reliability. Unlike hallucination detection in single-turn responses, diagnosing hallucinations in multi-step workflows requires identifying which step causes the initial divergence. To fill this gap, we propose a new research task, automated hallucination attribution of LLM-based agents, aiming to identify the step responsible for the hallucination and explain why. To support this task, we introduce AgentHallu, a comprehensive benchmark with: (1) 693 high-quality trajectories spanning 7 agent frameworks and 5 domains, (2) a hallucination taxonomy organized into 5 categories (Planning, Retrieval, Reasoning, Human-Interaction, and Tool-Use) and 14 sub-categories, and (3) multi-level annotations curated by humans, covering binary labels, hallucination-responsible steps, and causal explanations. We evaluate 13 leading models, and results show the task is challenging even for top-tier models (like GPT-5, Gemini-2.5-Pro). The best-performing model achieves only 41.1\% step localization accuracy, where tool-use hallucinations are the most challenging at just 11.6\%. We believe AgentHallu will catalyze future research into developing robust, transparent, and reliable agentic systems.
A*-Thought: Efficient Reasoning via Bidirectional Compression for Low-Resource Settings
May 30, 2025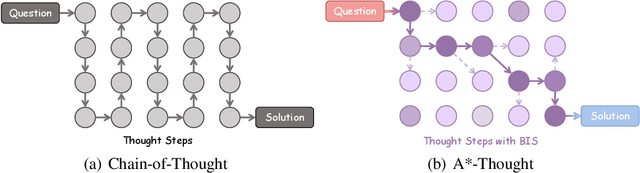
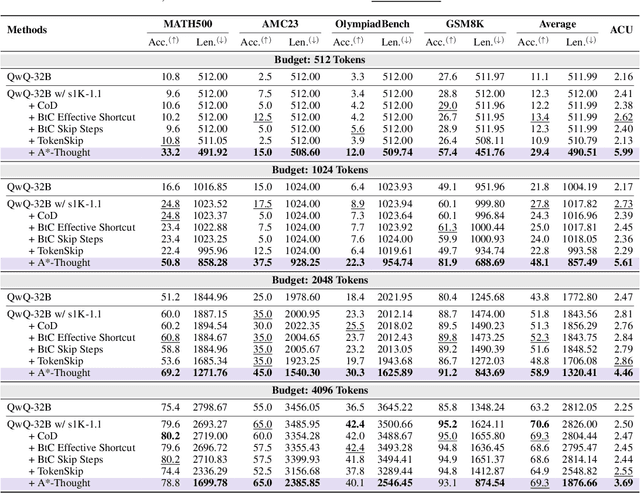
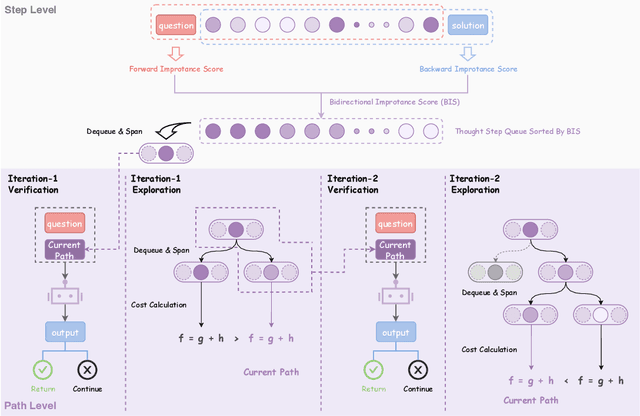

Large Reasoning Models (LRMs) achieve superior performance by extending the thought length. However, a lengthy thinking trajectory leads to reduced efficiency. Most of the existing methods are stuck in the assumption of overthinking and attempt to reason efficiently by compressing the Chain-of-Thought, but this often leads to performance degradation. To address this problem, we introduce A*-Thought, an efficient tree search-based unified framework designed to identify and isolate the most essential thoughts from the extensive reasoning chains produced by these models. It formulates the reasoning process of LRMs as a search tree, where each node represents a reasoning span in the giant reasoning space. By combining the A* search algorithm with a cost function specific to the reasoning path, it can efficiently compress the chain of thought and determine a reasoning path with high information density and low cost. In addition, we also propose a bidirectional importance estimation mechanism, which further refines this search process and enhances its efficiency beyond uniform sampling. Extensive experiments on several advanced math tasks show that A*-Thought effectively balances performance and efficiency over a huge search space. Specifically, A*-Thought can improve the performance of QwQ-32B by 2.39$\times$ with low-budget and reduce the length of the output token by nearly 50% with high-budget. The proposed method is also compatible with several other LRMs, demonstrating its generalization capability. The code can be accessed at: https://github.com/AI9Stars/AStar-Thought.
T^2Agent A Tool-augmented Multimodal Misinformation Detection Agent with Monte Carlo Tree Search
May 26, 2025Real-world multimodal misinformation often arises from mixed forgery sources, requiring dynamic reasoning and adaptive verification. However, existing methods mainly rely on static pipelines and limited tool usage, limiting their ability to handle such complexity and diversity. To address this challenge, we propose T2Agent, a novel misinformation detection agent that incorporates an extensible toolkit with Monte Carlo Tree Search (MCTS). The toolkit consists of modular tools such as web search, forgery detection, and consistency analysis. Each tool is described using standardized templates, enabling seamless integration and future expansion. To avoid inefficiency from using all tools simultaneously, a Bayesian optimization-based selector is proposed to identify a task-relevant subset. This subset then serves as the action space for MCTS to dynamically collect evidence and perform multi-source verification. To better align MCTS with the multi-source nature of misinformation detection, T2Agent extends traditional MCTS with multi-source verification, which decomposes the task into coordinated subtasks targeting different forgery sources. A dual reward mechanism containing a reasoning trajectory score and a confidence score is further proposed to encourage a balance between exploration across mixed forgery sources and exploitation for more reliable evidence. We conduct ablation studies to confirm the effectiveness of the tree search mechanism and tool usage. Extensive experiments further show that T2Agent consistently outperforms existing baselines on challenging mixed-source multimodal misinformation benchmarks, demonstrating its strong potential as a training-free approach for enhancing detection accuracy. The code will be released.
Video-SafetyBench: A Benchmark for Safety Evaluation of Video LVLMs
May 17, 2025The increasing deployment of Large Vision-Language Models (LVLMs) raises safety concerns under potential malicious inputs. However, existing multimodal safety evaluations primarily focus on model vulnerabilities exposed by static image inputs, ignoring the temporal dynamics of video that may induce distinct safety risks. To bridge this gap, we introduce Video-SafetyBench, the first comprehensive benchmark designed to evaluate the safety of LVLMs under video-text attacks. It comprises 2,264 video-text pairs spanning 48 fine-grained unsafe categories, each pairing a synthesized video with either a harmful query, which contains explicit malice, or a benign query, which appears harmless but triggers harmful behavior when interpreted alongside the video. To generate semantically accurate videos for safety evaluation, we design a controllable pipeline that decomposes video semantics into subject images (what is shown) and motion text (how it moves), which jointly guide the synthesis of query-relevant videos. To effectively evaluate uncertain or borderline harmful outputs, we propose RJScore, a novel LLM-based metric that incorporates the confidence of judge models and human-aligned decision threshold calibration. Extensive experiments show that benign-query video composition achieves average attack success rates of 67.2%, revealing consistent vulnerabilities to video-induced attacks. We believe Video-SafetyBench will catalyze future research into video-based safety evaluation and defense strategies.
ID-Cloak: Crafting Identity-Specific Cloaks Against Personalized Text-to-Image Generation
Feb 12, 2025Personalized text-to-image models allow users to generate images of new concepts from several reference photos, thereby leading to critical concerns regarding civil privacy. Although several anti-personalization techniques have been developed, these methods typically assume that defenders can afford to design a privacy cloak corresponding to each specific image. However, due to extensive personal images shared online, image-specific methods are limited by real-world practical applications. To address this issue, we are the first to investigate the creation of identity-specific cloaks (ID-Cloak) that safeguard all images belong to a specific identity. Specifically, we first model an identity subspace that preserves personal commonalities and learns diverse contexts to capture the image distribution to be protected. Then, we craft identity-specific cloaks with the proposed novel objective that encourages the cloak to guide the model away from its normal output within the subspace. Extensive experiments show that the generated universal cloak can effectively protect the images. We believe our method, along with the proposed identity-specific cloak setting, marks a notable advance in realistic privacy protection.
Survey on AI-Generated Media Detection: From Non-MLLM to MLLM
Feb 07, 2025The proliferation of AI-generated media poses significant challenges to information authenticity and social trust, making reliable detection methods highly demanded. Methods for detecting AI-generated media have evolved rapidly, paralleling the advancement of Multimodal Large Language Models (MLLMs). Current detection approaches can be categorized into two main groups: Non-MLLM-based and MLLM-based methods. The former employs high-precision, domain-specific detectors powered by deep learning techniques, while the latter utilizes general-purpose detectors based on MLLMs that integrate authenticity verification, explainability, and localization capabilities. Despite significant progress in this field, there remains a gap in literature regarding a comprehensive survey that examines the transition from domain-specific to general-purpose detection methods. This paper addresses this gap by providing a systematic review of both approaches, analyzing them from single-modal and multi-modal perspectives. We present a detailed comparative analysis of these categories, examining their methodological similarities and differences. Through this analysis, we explore potential hybrid approaches and identify key challenges in forgery detection, providing direction for future research. Additionally, as MLLMs become increasingly prevalent in detection tasks, ethical and security considerations have emerged as critical global concerns. We examine the regulatory landscape surrounding Generative AI (GenAI) across various jurisdictions, offering valuable insights for researchers and practitioners in this field.
Jailbreak Attacks and Defenses against Multimodal Generative Models: A Survey
Nov 14, 2024



The rapid evolution of multimodal foundation models has led to significant advancements in cross-modal understanding and generation across diverse modalities, including text, images, audio, and video. However, these models remain susceptible to jailbreak attacks, which can bypass built-in safety mechanisms and induce the production of potentially harmful content. Consequently, understanding the methods of jailbreak attacks and existing defense mechanisms is essential to ensure the safe deployment of multimodal generative models in real-world scenarios, particularly in security-sensitive applications. To provide comprehensive insight into this topic, this survey reviews jailbreak and defense in multimodal generative models. First, given the generalized lifecycle of multimodal jailbreak, we systematically explore attacks and corresponding defense strategies across four levels: input, encoder, generator, and output. Based on this analysis, we present a detailed taxonomy of attack methods, defense mechanisms, and evaluation frameworks specific to multimodal generative models. Additionally, we cover a wide range of input-output configurations, including modalities such as Any-to-Text, Any-to-Vision, and Any-to-Any within generative systems. Finally, we highlight current research challenges and propose potential directions for future research.The open-source repository corresponding to this work can be found at https://github.com/liuxuannan/Awesome-Multimodal-Jailbreak.
Online Multi-Label Classification under Noisy and Changing Label Distribution
Oct 03, 2024Multi-label data stream usually contains noisy labels in the real-world applications, namely occuring in both relevant and irrelevant labels. However, existing online multi-label classification methods are mostly limited in terms of label quality and fail to deal with the case of noisy labels. On the other hand, the ground-truth label distribution may vary with the time changing, which is hidden in the observed noisy label distribution and difficult to track, posing a major challenge for concept drift adaptation. Motivated by this, we propose an online multi-label classification algorithm under Noisy and Changing Label Distribution (NCLD). The convex objective is designed to simultaneously model the label scoring and the label ranking for high accuracy, whose robustness to NCLD benefits from three novel works: 1) The local feature graph is used to reconstruct the label scores jointly with the observed labels, and an unbiased ranking loss is derived and applied to learn reliable ranking information. 2) By detecting the difference between two adjacent chunks with the unbiased label cardinality, we identify the change in the ground-truth label distribution and reset the ranking or all information learned from the past to match the new distribution. 3) Efficient and accurate updating is achieved based on the updating rule derived from the closed-form optimal model solution. Finally, empirical experimental results validate the effectiveness of our method in classifying instances under NCLD.