 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU-Popo: Universal Post-Processing Model for Structured Document Parsing
May 24, 2026VLM-based OCR models have become the de facto choice for document parsing, as they can accurately extract page-level elements (e.g., paragraphs within individual pages) together with their bounding boxes and textual content. However, downstream applications such as RAG require coherent document-level information, whereas these models often break cross-page continuity and fail to recover disrupted structures, such as paragraphs and tables truncated by page boundaries. Such relationships are not confined to a single page; instead, they require joint analysis of titles, paragraphs, tables, and images spanning multiple pages. A natural solution is therefore to reuse existing OCR outputs and reconstruct document-level logical structures through post-processing. To this end, we propose MinerU-Popo, a lightweight and universal framework for POst-Processing OCR outputs, which converts page-level results from diverse parsers into coherent document-level structures. MinerU-Popo decomposes the problem into four focused subtasks: text truncation recovery, table truncation recovery, title hierarchy reconstruction, and image-text association. To address these effectively, we build a task-oriented data engine with task-specific input filtering, and use the generated data (30K) to fine-tune a lightweight post-processing model (Qwen3-VL-4B). To support long documents, we introduce dynamic chunking with overlap-based synchronization, which aligns chunk-level outputs from the fine-tuned model and preserves global consistency. Finally, we assemble the aligned outputs into a tree-structured document representation, further enriched with node chunking and summaries for downstream retrieval and analysis. Empirical results show MinerU-Popo improves title-hierarchy TEDS by at least 20% across all five tested OCR models, improves RAG accuracy and reduces per-query latency.
Workspace-Bench 1.0: Benchmarking AI Agents on Workspace Tasks with Large-Scale File Dependencies
May 05, 2026Workspace learning requires AI agents to identify, reason over, exploit, and update explicit and implicit dependencies among heterogeneous files in a worker's workspace, enabling them to complete both routine and advanced tasks effectively. Despite its importance, existing relevant benchmarks largely evaluate agents on pre-specified or synthesized files with limited real-world dependencies, leaving workspace-level evaluation underexplored. To this end, we introduce Workspace-Bench, a benchmark for evaluating AI agents on Workspace Learning invOlving Large-Scale File Dependencies. We construct realistic workspaces with 5 worker profiles, 74 file types, 20,476 files (up to 20GB) and curate 388 tasks, each with its own file dependency graph, evaluated across 7,399 total rubrics that require cross-file retrieval, contextual reasoning, and adaptive decision-making. We further provide Workspace-Bench-Lite, a 100-task subset that preserves the benchmark distribution while reducing evaluation costs by about 70%. We evaluate 4 popular agent harnesses and 7 foundation models. Experimental results show that current agents remain far from reliable workspace learning, where the best reaches only 68.7%, substantially below the human result of 80.7%, and the average performance across agents is only 47.4%.
MoDora: Tree-Based Semi-Structured Document Analysis System
Feb 26, 2026Semi-structured documents integrate diverse interleaved data elements (e.g., tables, charts, hierarchical paragraphs) arranged in various and often irregular layouts. These documents are widely observed across domains and account for a large portion of real-world data. However, existing methods struggle to support natural language question answering over these documents due to three main technical challenges: (1) The elements extracted by techniques like OCR are often fragmented and stripped of their original semantic context, making them inadequate for analysis. (2) Existing approaches lack effective representations to capture hierarchical structures within documents (e.g., associating tables with nested chapter titles) and to preserve layout-specific distinctions (e.g., differentiating sidebars from main content). (3) Answering questions often requires retrieving and aligning relevant information scattered across multiple regions or pages, such as linking a descriptive paragraph to table cells located elsewhere in the document. To address these issues, we propose MoDora, an LLM-powered system for semi-structured document analysis. First, we adopt a local-alignment aggregation strategy to convert OCR-parsed elements into layout-aware components, and conduct type-specific information extraction for components with hierarchical titles or non-text elements. Second, we design the Component-Correlation Tree (CCTree) to hierarchically organize components, explicitly modeling inter-component relations and layout distinctions through a bottom-up cascade summarization process. Finally, we propose a question-type-aware retrieval strategy that supports (1) layout-based grid partitioning for location-based retrieval and (2) LLM-guided pruning for semantic-based retrieval. Experiments show MoDora outperforms baselines by 5.97%-61.07% in accuracy. The code is at https://github.com/weAIDB/MoDora.
ST-Raptor: An Agentic System for Semi-Structured Table QA
Feb 03, 2026Semi-structured table question answering (QA) is a challenging task that requires (1) precise extraction of cell contents and positions and (2) accurate recovery of key implicit logical structures, hierarchical relationships, and semantic associations encoded in table layouts. In practice, such tables are often interpreted manually by human experts, which is labor-intensive and time-consuming. However, automating this process remains difficult. Existing Text-to-SQL methods typically require converting semi-structured tables into structured formats, inevitably leading to information loss, while approaches like Text-to-Code and multimodal LLM-based QA struggle with complex layouts and often yield inaccurate answers. To address these limitations, we present ST-Raptor, an agentic system for semi-structured table QA. ST-Raptor offers an interactive analysis environment that combines visual editing, tree-based structural modeling, and agent-driven query resolution to support accurate and user-friendly table understanding. Experimental results on both benchmark and real-world datasets demonstrate that ST-Raptor outperforms existing methods in both accuracy and usability. The code is available at https://github.com/weAIDB/ST-Raptor, and a demonstration video is available at https://youtu.be/9GDR-94Cau4.
Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs
Jan 22, 2026Data preparation aims to denoise raw datasets, uncover cross-dataset relationships, and extract valuable insights from them, which is essential for a wide range of data-centric applications. Driven by (i) rising demands for application-ready data (e.g., for analytics, visualization, decision-making), (ii) increasingly powerful LLM techniques, and (iii) the emergence of infrastructures that facilitate flexible agent construction (e.g., using Databricks Unity Catalog), LLM-enhanced methods are rapidly becoming a transformative and potentially dominant paradigm for data preparation. By investigating hundreds of recent literature works, this paper presents a systematic review of this evolving landscape, focusing on the use of LLM techniques to prepare data for diverse downstream tasks. First, we characterize the fundamental paradigm shift, from rule-based, model-specific pipelines to prompt-driven, context-aware, and agentic preparation workflows. Next, we introduce a task-centric taxonomy that organizes the field into three major tasks: data cleaning (e.g., standardization, error processing, imputation), data integration (e.g., entity matching, schema matching), and data enrichment (e.g., data annotation, profiling). For each task, we survey representative techniques, and highlight their respective strengths (e.g., improved generalization, semantic understanding) and limitations (e.g., the prohibitive cost of scaling LLMs, persistent hallucinations even in advanced agents, the mismatch between advanced methods and weak evaluation). Moreover, we analyze commonly used datasets and evaluation metrics (the empirical part). Finally, we discuss open research challenges and outline a forward-looking roadmap that emphasizes scalable LLM-data systems, principled designs for reliable agentic workflows, and robust evaluation protocols.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
ST-Raptor: LLM-Powered Semi-Structured Table Question Answering
Aug 25, 2025



Semi-structured tables, widely used in real-world applications (e.g., financial reports, medical records, transactional orders), often involve flexible and complex layouts (e.g., hierarchical headers and merged cells). These tables generally rely on human analysts to interpret table layouts and answer relevant natural language questions, which is costly and inefficient. To automate the procedure, existing methods face significant challenges. First, methods like NL2SQL require converting semi-structured tables into structured ones, which often causes substantial information loss. Second, methods like NL2Code and multi-modal LLM QA struggle to understand the complex layouts of semi-structured tables and cannot accurately answer corresponding questions. To this end, we propose ST-Raptor, a tree-based framework for semi-structured table question answering using large language models. First, we introduce the Hierarchical Orthogonal Tree (HO-Tree), a structural model that captures complex semi-structured table layouts, along with an effective algorithm for constructing the tree. Second, we define a set of basic tree operations to guide LLMs in executing common QA tasks. Given a user question, ST-Raptor decomposes it into simpler sub-questions, generates corresponding tree operation pipelines, and conducts operation-table alignment for accurate pipeline execution. Third, we incorporate a two-stage verification mechanism: forward validation checks the correctness of execution steps, while backward validation evaluates answer reliability by reconstructing queries from predicted answers. To benchmark the performance, we present SSTQA, a dataset of 764 questions over 102 real-world semi-structured tables. Experiments show that ST-Raptor outperforms nine baselines by up to 20% in answer accuracy. The code is available at https://github.com/weAIDB/ST-Raptor.
A Survey of LLM $\times$ DATA
May 24, 2025The integration of large language model (LLM) and data management (DATA) is rapidly redefining both domains. In this survey, we comprehensively review the bidirectional relationships. On the one hand, DATA4LLM, spanning large-scale data processing, storage, and serving, feeds LLMs with high quality, diversity, and timeliness of data required for stages like pre-training, post-training, retrieval-augmented generation, and agentic workflows: (i) Data processing for LLMs includes scalable acquisition, deduplication, filtering, selection, domain mixing, and synthetic augmentation; (ii) Data Storage for LLMs focuses on efficient data and model formats, distributed and heterogeneous storage hierarchies, KV-cache management, and fault-tolerant checkpointing; (iii) Data serving for LLMs tackles challenges in RAG (e.g., knowledge post-processing), LLM inference (e.g., prompt compression, data provenance), and training strategies (e.g., data packing and shuffling). On the other hand, in LLM4DATA, LLMs are emerging as general-purpose engines for data management. We review recent advances in (i) data manipulation, including automatic data cleaning, integration, discovery; (ii) data analysis, covering reasoning over structured, semi-structured, and unstructured data, and (iii) system optimization (e.g., configuration tuning, query rewriting, anomaly diagnosis), powered by LLM techniques like retrieval-augmented prompting, task-specialized fine-tuning, and multi-agent collaboration.
FeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform
Apr 01, 2025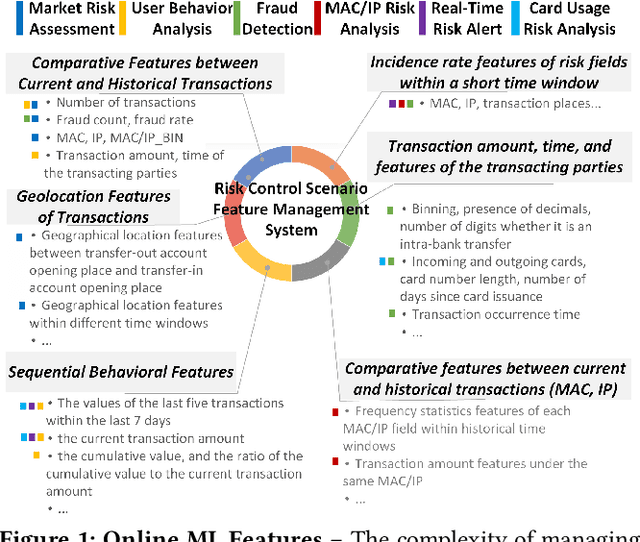
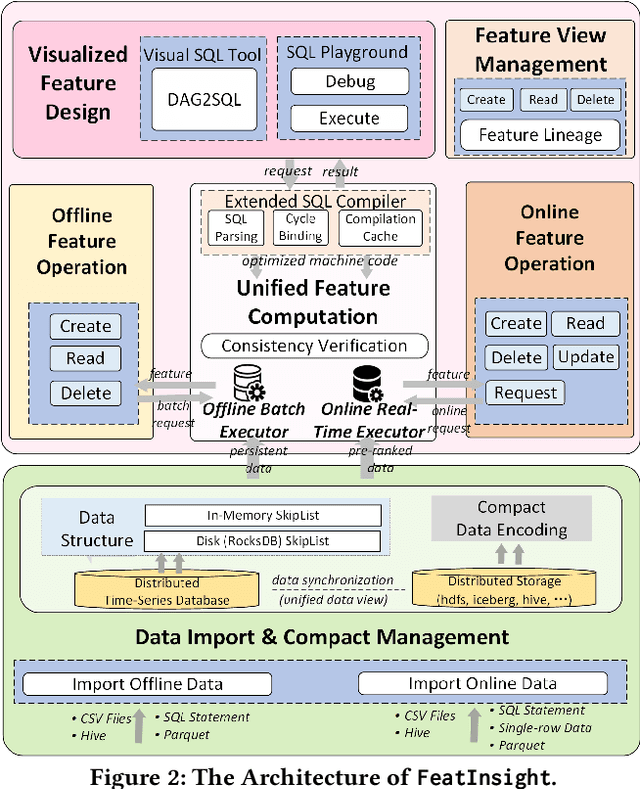
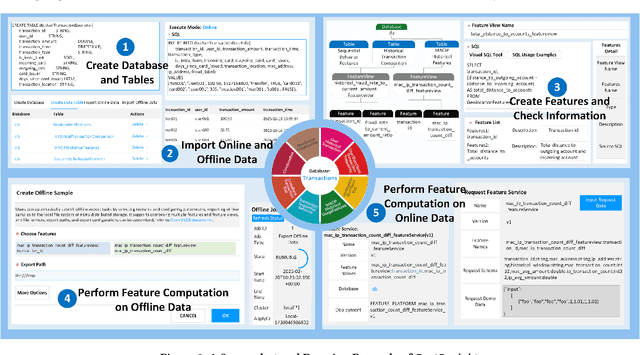
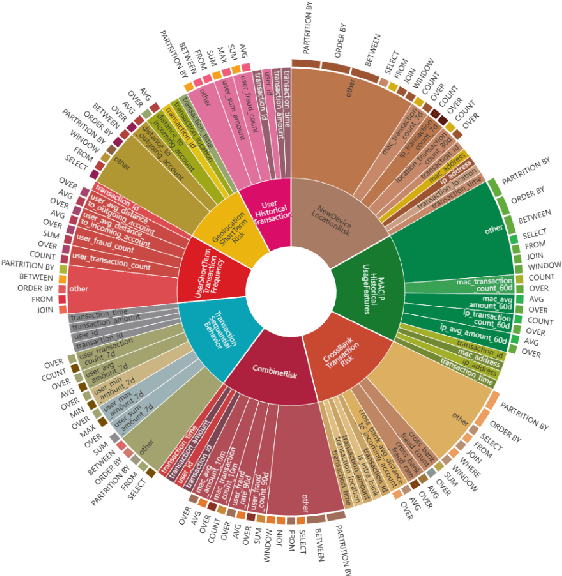
Feature management is essential for many online machine learning applications and can often become the performance bottleneck (e.g., taking up to 70% of the overall latency in sales prediction service). Improper feature configurations (e.g., introducing too many irrelevant features) can severely undermine the model's generalization capabilities. However, managing online ML features is challenging due to (1) large-scale, complex raw data (e.g., the 2018 PHM dataset contains 17 tables and dozens to hundreds of columns), (2) the need for high-performance, consistent computation of interdependent features with complex patterns, and (3) the requirement for rapid updates and deployments to accommodate real-time data changes. In this demo, we present FeatInsight, a system that supports the entire feature lifecycle, including feature design, storage, visualization, computation, verification, and lineage management. FeatInsight (with OpenMLDB as the execution engine) has been deployed in over 100 real-world scenarios on 4Paradigm's Sage Studio platform, handling up to a trillion-dimensional feature space and enabling millisecond-level feature updates. We demonstrate how FeatInsight enhances feature design efficiency (e.g., for online product recommendation) and improve feature computation performance (e.g., for online fraud detection). The code is available at https://github.com/4paradigm/FeatInsight.