 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNN-Guard: Certified Robustness Against Multi-frame Attacks for Recurrent Neural Networks
Apr 17, 2023It is well-known that recurrent neural networks (RNNs), although widely used, are vulnerable to adversarial attacks including one-frame attacks and multi-frame attacks. Though a few certified defenses exist to provide guaranteed robustness against one-frame attacks, we prove that defending against multi-frame attacks remains a challenging problem due to their enormous perturbation space. In this paper, we propose the first certified defense against multi-frame attacks for RNNs called RNN-Guard. To address the above challenge, we adopt the perturb-all-frame strategy to construct perturbation spaces consistent with those in multi-frame attacks. However, the perturb-all-frame strategy causes a precision issue in linear relaxations. To address this issue, we introduce a novel abstract domain called InterZono and design tighter relaxations. We prove that InterZono is more precise than Zonotope yet carries the same time complexity. Experimental evaluations across various datasets and model structures show that the certified robust accuracy calculated by RNN-Guard with InterZono is up to 2.18 times higher than that with Zonotope. In addition, we extend RNN-Guard as the first certified training method against multi-frame attacks to directly enhance RNNs' robustness. The results show that the certified robust accuracy of models trained with RNN-Guard against multi-frame attacks is 15.47 to 67.65 percentage points higher than those with other training methods.
Diff-ID: An Explainable Identity Difference Quantification Framework for DeepFake Detection
Mar 30, 2023



Despite the fact that DeepFake forgery detection algorithms have achieved impressive performance on known manipulations, they often face disastrous performance degradation when generalized to an unseen manipulation. Some recent works show improvement in generalization but rely on features fragile to image distortions such as compression. To this end, we propose Diff-ID, a concise and effective approach that explains and measures the identity loss induced by facial manipulations. When testing on an image of a specific person, Diff-ID utilizes an authentic image of that person as a reference and aligns them to the same identity-insensitive attribute feature space by applying a face-swapping generator. We then visualize the identity loss between the test and the reference image from the image differences of the aligned pairs, and design a custom metric to quantify the identity loss. The metric is then proved to be effective in distinguishing the forgery images from the real ones. Extensive experiments show that our approach achieves high detection performance on DeepFake images and state-of-the-art generalization ability to unknown forgery methods, while also being robust to image distortions.
Watch Out for the Confusing Faces: Detecting Face Swapping with the Probability Distribution of Face Identification Models
Mar 23, 2023



Recently, face swapping has been developing rapidly and achieved a surprising reality, raising concerns about fake content. As a countermeasure, various detection approaches have been proposed and achieved promising performance. However, most existing detectors struggle to maintain performance on unseen face swapping methods and low-quality images. Apart from the generalization problem, current detection approaches have been shown vulnerable to evasion attacks crafted by detection-aware manipulators. Lack of robustness under adversary scenarios leaves threats for applying face swapping detection in real world. In this paper, we propose a novel face swapping detection approach based on face identification probability distributions, coined as IdP_FSD, to improve the generalization and robustness. IdP_FSD is specially designed for detecting swapped faces whose identities belong to a finite set, which is meaningful in real-world applications. Compared with previous general detection methods, we make use of the available real faces with concerned identities and require no fake samples for training. IdP_FSD exploits face swapping's common nature that the identity of swapped face combines that of two faces involved in swapping. We reflect this nature with the confusion of a face identification model and measure the confusion with the maximum value of the output probability distribution. What's more, to defend our detector under adversary scenarios, an attention-based finetuning scheme is proposed for the face identification models used in IdP_FSD. Extensive experiments show that the proposed IdP_FSD not only achieves high detection performance on different benchmark datasets and image qualities but also raises the bar for manipulators to evade the detection.
Edge Deep Learning Model Protection via Neuron Authorization
Mar 23, 2023With the development of deep learning processors and accelerators, deep learning models have been widely deployed on edge devices as part of the Internet of Things. Edge device models are generally considered as valuable intellectual properties that are worth for careful protection. Unfortunately, these models have a great risk of being stolen or illegally copied. The existing model protections using encryption algorithms are suffered from high computation overhead which is not practical due to the limited computing capacity on edge devices. In this work, we propose a light-weight, practical, and general Edge device model Pro tection method at neuron level, denoted as EdgePro. Specifically, we select several neurons as authorization neurons and set their activation values to locking values and scale the neuron outputs as the "asswords" during training. EdgePro protects the model by ensuring it can only work correctly when the "passwords" are met, at the cost of encrypting and storing the information of the "passwords" instead of the whole model. Extensive experimental results indicate that EdgePro can work well on the task of protecting on datasets with different modes. The inference time increase of EdgePro is only 60% of state-of-the-art methods, and the accuracy loss is less than 1%. Additionally, EdgePro is robust against adaptive attacks including fine-tuning and pruning, which makes it more practical in real-world applications. EdgePro is also open sourced to facilitate future research: https://github.com/Leon022/Edg
FreeEagle: Detecting Complex Neural Trojans in Data-Free Cases
Feb 28, 2023Trojan attack on deep neural networks, also known as backdoor attack, is a typical threat to artificial intelligence. A trojaned neural network behaves normally with clean inputs. However, if the input contains a particular trigger, the trojaned model will have attacker-chosen abnormal behavior. Although many backdoor detection methods exist, most of them assume that the defender has access to a set of clean validation samples or samples with the trigger, which may not hold in some crucial real-world cases, e.g., the case where the defender is the maintainer of model-sharing platforms. Thus, in this paper, we propose FreeEagle, the first data-free backdoor detection method that can effectively detect complex backdoor attacks on deep neural networks, without relying on the access to any clean samples or samples with the trigger. The evaluation results on diverse datasets and model architectures show that FreeEagle is effective against various complex backdoor attacks, even outperforming some state-of-the-art non-data-free backdoor detection methods.
TextDefense: Adversarial Text Detection based on Word Importance Entropy
Feb 12, 2023



Currently, natural language processing (NLP) models are wildly used in various scenarios. However, NLP models, like all deep models, are vulnerable to adversarially generated text. Numerous works have been working on mitigating the vulnerability from adversarial attacks. Nevertheless, there is no comprehensive defense in existing works where each work targets a specific attack category or suffers from the limitation of computation overhead, irresistible to adaptive attack, etc. In this paper, we exhaustively investigate the adversarial attack algorithms in NLP, and our empirical studies have discovered that the attack algorithms mainly disrupt the importance distribution of words in a text. A well-trained model can distinguish subtle importance distribution differences between clean and adversarial texts. Based on this intuition, we propose TextDefense, a new adversarial example detection framework that utilizes the target model's capability to defend against adversarial attacks while requiring no prior knowledge. TextDefense differs from previous approaches, where it utilizes the target model for detection and thus is attack type agnostic. Our extensive experiments show that TextDefense can be applied to different architectures, datasets, and attack methods and outperforms existing methods. We also discover that the leading factor influencing the performance of TextDefense is the target model's generalizability. By analyzing the property of the target model and the property of the adversarial example, we provide our insights into the adversarial attacks in NLP and the principles of our defense method.
All You Need Is Hashing: Defending Against Data Reconstruction Attack in Vertical Federated Learning
Dec 01, 2022Vertical federated learning is a trending solution for multi-party collaboration in training machine learning models. Industrial frameworks adopt secure multi-party computation methods such as homomorphic encryption to guarantee data security and privacy. However, a line of work has revealed that there are still leakage risks in VFL. The leakage is caused by the correlation between the intermediate representations and the raw data. Due to the powerful approximation ability of deep neural networks, an adversary can capture the correlation precisely and reconstruct the data. To deal with the threat of the data reconstruction attack, we propose a hashing-based VFL framework, called \textit{HashVFL}, to cut off the reversibility directly. The one-way nature of hashing allows our framework to block all attempts to recover data from hash codes. However, integrating hashing also brings some challenges, e.g., the loss of information. This paper proposes and addresses three challenges to integrating hashing: learnability, bit balance, and consistency. Experimental results demonstrate \textit{HashVFL}'s efficiency in keeping the main task's performance and defending against data reconstruction attacks. Furthermore, we also analyze its potential value in detecting abnormal inputs. In addition, we conduct extensive experiments to prove \textit{HashVFL}'s generalization in various settings. In summary, \textit{HashVFL} provides a new perspective on protecting multi-party's data security and privacy in VFL. We hope our study can attract more researchers to expand the application domains of \textit{HashVFL}.
Hijack Vertical Federated Learning Models with Adversarial Embedding
Dec 01, 2022



Vertical federated learning (VFL) is an emerging paradigm that enables collaborators to build machine learning models together in a distributed fashion. In general, these parties have a group of users in common but own different features. Existing VFL frameworks use cryptographic techniques to provide data privacy and security guarantees, leading to a line of works studying computing efficiency and fast implementation. However, the security of VFL's model remains underexplored.
Demystifying Self-supervised Trojan Attacks
Oct 13, 2022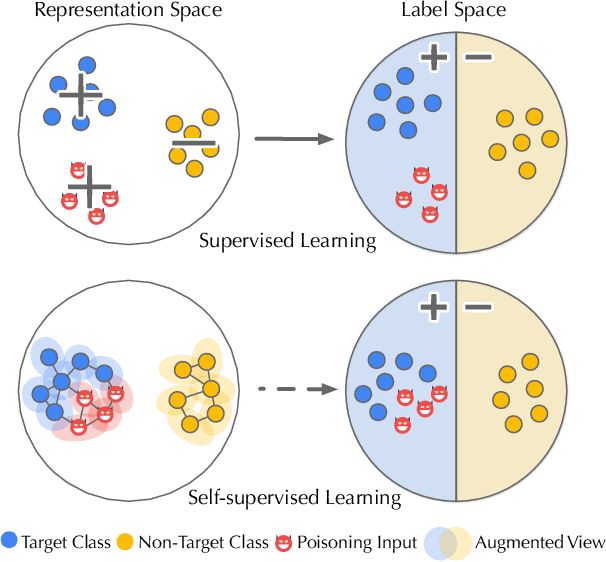
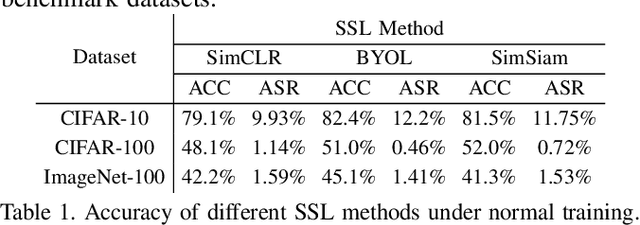
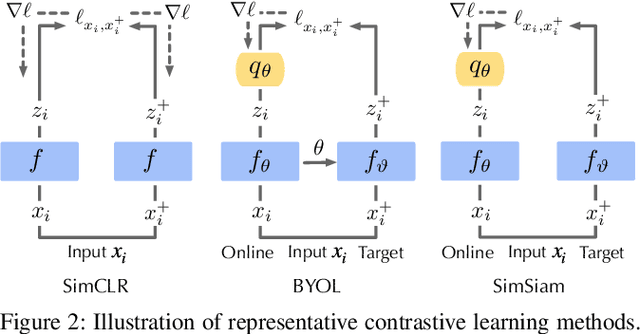
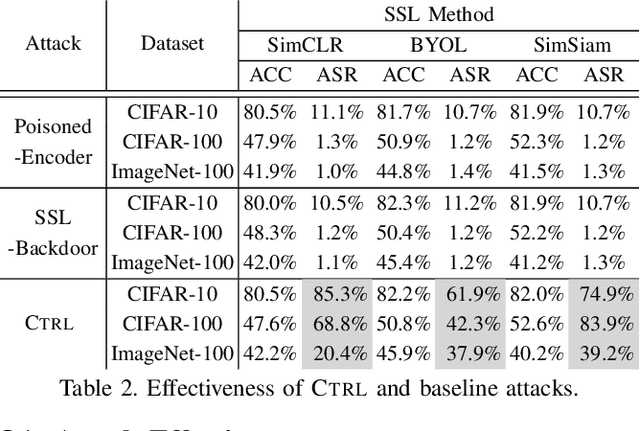
As an emerging machine learning paradigm, self-supervised learning (SSL) is able to learn high-quality representations for complex data without data labels. Prior work shows that, besides obviating the reliance on labeling, SSL also benefits adversarial robustness by making it more challenging for the adversary to manipulate model prediction. However, whether this robustness benefit generalizes to other types of attacks remains an open question. We explore this question in the context of trojan attacks by showing that SSL is comparably vulnerable as supervised learning to trojan attacks. Specifically, we design and evaluate CTRL, an extremely simple self-supervised trojan attack. By polluting a tiny fraction of training data (less than 1%) with indistinguishable poisoning samples, CTRL causes any trigger-embedded input to be misclassified to the adversary's desired class with a high probability (over 99%) at inference. More importantly, through the lens of CTRL, we study the mechanisms underlying self-supervised trojan attacks. With both empirical and analytical evidence, we reveal that the representation invariance property of SSL, which benefits adversarial robustness, may also be the very reason making SSL highly vulnerable to trojan attacks. We further discuss the fundamental challenges to defending against self-supervised trojan attacks, pointing to promising directions for future research.
Reasoning over Multi-view Knowledge Graphs
Sep 27, 2022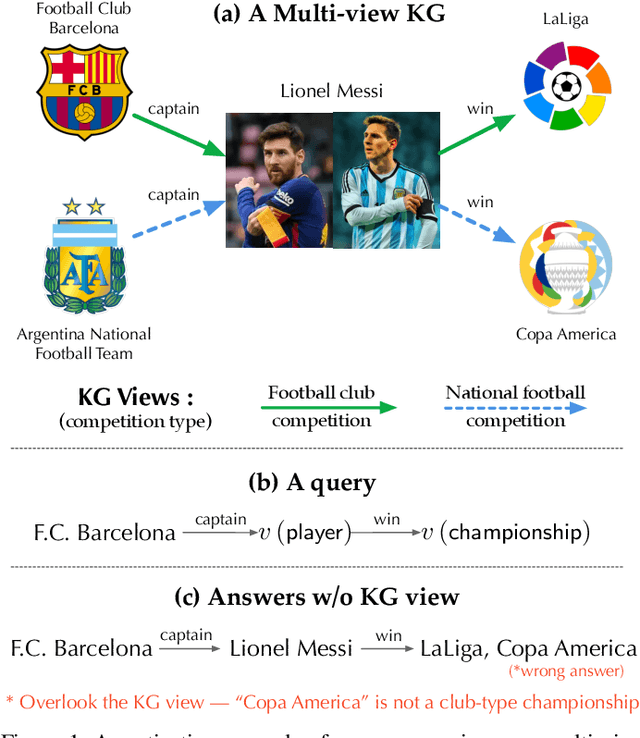
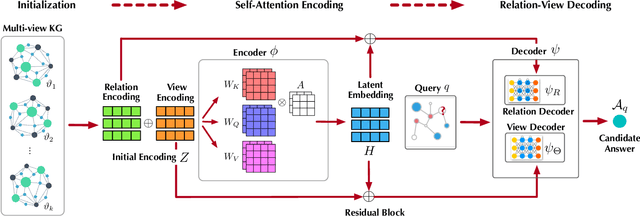
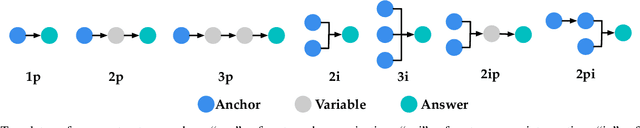
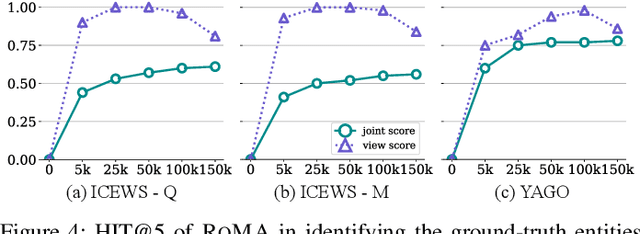
Recently, knowledge representation learning (KRL) is emerging as the state-of-the-art approach to process queries over knowledge graphs (KGs), wherein KG entities and the query are embedded into a latent space such that entities that answer the query are embedded close to the query. Yet, despite the intensive research on KRL, most existing studies either focus on homogenous KGs or assume KG completion tasks (i.e., inference of missing facts), while answering complex logical queries over KGs with multiple aspects (multi-view KGs) remains an open challenge. To bridge this gap, in this paper, we present ROMA, a novel KRL framework for answering logical queries over multi-view KGs. Compared with the prior work, ROMA departs in major aspects. (i) It models a multi-view KG as a set of overlaying sub-KGs, each corresponding to one view, which subsumes many types of KGs studied in the literature (e.g., temporal KGs). (ii) It supports complex logical queries with varying relation and view constraints (e.g., with complex topology and/or from multiple views); (iii) It scales up to KGs of large sizes (e.g., millions of facts) and fine-granular views (e.g., dozens of views); (iv) It generalizes to query structures and KG views that are unobserved during training. Extensive empirical evaluation on real-world KGs shows that \system significantly outperforms alternative methods.