 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniPlan: An Adaptive Framework for Timely and Near-Optimal Network Planning Optimization
Jun 17, 2026Network planning optimization is a fundamental problem across diverse domains, including transportation systems, communication networks, and power grids. It requires simultaneous optimization of multiple competing objectives under complex constraints. Existing network planning optimization frameworks rely on mixed integer programming (MIP) solvers, heuristics, and deep reinforcement learning (DRL) models to compute planning decisions. However, they lack effective adaptability to diverse and dynamic user intents, thus leading to the trade-off between execution time and optimality. In this paper, we propose OmniPlan, an adaptive framework that achieves both timeliness and near-optimality in network planning optimization. To achieve the adaptability lacking in existing solutions, OmniPlan employs a large language model (LLM)-based interpreter to convert heterogeneous natural-language intents into a unified and quantifiable user-preference vector. Then it employs a mixture-of-experts architecture that integrates MIP solvers, heuristics, and DRL models as specialized experts, where OmniPlan adapts to diverse intents by dynamically selecting timely and near-optimal experts. Finally, it incorporates a DRL-based expert configuration module that fine-tunes optimization objective weights to align planning decisions with user-specific preferences. We evaluate OmniPlan with a representative real-world workload, i.e., distributed machine learning (ML), where we leverage OmniPlan to offload a wide spectrum of ML inference tasks, e.g., decision trees, SVM, naive Bayes, XGBoost, and random forests, onto a network of hardware devices. Our experiments on a real-world testbed indicate that OmniPlan achieves near-optimal and low-execution-time offloading for real-world ML inference tasks, reducing latency by up to 97.8\% and network device resource consumption by up to 11.5\%.
ICON: Intent-Context Coupling for Efficient Multi-Turn Jailbreak Attack
Jan 28, 2026Multi-turn jailbreak attacks have emerged as a critical threat to Large Language Models (LLMs), bypassing safety mechanisms by progressively constructing adversarial contexts from scratch and incrementally refining prompts. However, existing methods suffer from the inefficiency of incremental context construction that requires step-by-step LLM interaction, and often stagnate in suboptimal regions due to surface-level optimization. In this paper, we characterize the Intent-Context Coupling phenomenon, revealing that LLM safety constraints are significantly relaxed when a malicious intent is coupled with a semantically congruent context pattern. Driven by this insight, we propose ICON, an automated multi-turn jailbreak framework that efficiently constructs an authoritative-style context via prior-guided semantic routing. Specifically, ICON first routes the malicious intent to a congruent context pattern (e.g., Scientific Research) and instantiates it into an attack prompt sequence. This sequence progressively builds the authoritative-style context and ultimately elicits prohibited content. In addition, ICON incorporates a Hierarchical Optimization Strategy that combines local prompt refinement with global context switching, preventing the attack from stagnating in ineffective contexts. Experimental results across eight SOTA LLMs demonstrate the effectiveness of ICON, achieving a state-of-the-art average Attack Success Rate (ASR) of 97.1\%. Code is available at https://github.com/xwlin-roy/ICON.
LargeMvC-Net: Anchor-based Deep Unfolding Network for Large-scale Multi-view Clustering
Jul 28, 2025Deep anchor-based multi-view clustering methods enhance the scalability of neural networks by utilizing representative anchors to reduce the computational complexity of large-scale clustering. Despite their scalability advantages, existing approaches often incorporate anchor structures in a heuristic or task-agnostic manner, either through post-hoc graph construction or as auxiliary components for message passing. Such designs overlook the core structural demands of anchor-based clustering, neglecting key optimization principles. To bridge this gap, we revisit the underlying optimization problem of large-scale anchor-based multi-view clustering and unfold its iterative solution into a novel deep network architecture, termed LargeMvC-Net. The proposed model decomposes the anchor-based clustering process into three modules: RepresentModule, NoiseModule, and AnchorModule, corresponding to representation learning, noise suppression, and anchor indicator estimation. Each module is derived by unfolding a step of the original optimization procedure into a dedicated network component, providing structural clarity and optimization traceability. In addition, an unsupervised reconstruction loss aligns each view with the anchor-induced latent space, encouraging consistent clustering structures across views. Extensive experiments on several large-scale multi-view benchmarks show that LargeMvC-Net consistently outperforms state-of-the-art methods in terms of both effectiveness and scalability.
An Attention-Based Deep Generative Model for Anomaly Detection in Industrial Control Systems
May 03, 2024



Anomaly detection is critical for the secure and reliable operation of industrial control systems. As our reliance on such complex cyber-physical systems grows, it becomes paramount to have automated methods for detecting anomalies, preventing attacks, and responding intelligently. {This paper presents a novel deep generative model to meet this need. The proposed model follows a variational autoencoder architecture with a convolutional encoder and decoder to extract features from both spatial and temporal dimensions. Additionally, we incorporate an attention mechanism that directs focus towards specific regions, enhancing the representation of relevant features and improving anomaly detection accuracy. We also employ a dynamic threshold approach leveraging the reconstruction probability and make our source code publicly available to promote reproducibility and facilitate further research. Comprehensive experimental analysis is conducted on data from all six stages of the Secure Water Treatment (SWaT) testbed, and the experimental results demonstrate the superior performance of our approach compared to several state-of-the-art baseline techniques.
Self-Supervised Interest Transfer Network via Prototypical Contrastive Learning for Recommendation
Feb 28, 2023



Cross-domain recommendation has attracted increasing attention from industry and academia recently. However, most existing methods do not exploit the interest invariance between domains, which would yield sub-optimal solutions. In this paper, we propose a cross-domain recommendation method: Self-supervised Interest Transfer Network (SITN), which can effectively transfer invariant knowledge between domains via prototypical contrastive learning. Specifically, we perform two levels of cross-domain contrastive learning: 1) instance-to-instance contrastive learning, 2) instance-to-cluster contrastive learning. Not only that, we also take into account users' multi-granularity and multi-view interests. With this paradigm, SITN can explicitly learn the invariant knowledge of interest clusters between domains and accurately capture users' intents and preferences. We conducted extensive experiments on a public dataset and a large-scale industrial dataset collected from one of the world's leading e-commerce corporations. The experimental results indicate that SITN achieves significant improvements over state-of-the-art recommendation methods. Additionally, SITN has been deployed on a micro-video recommendation platform, and the online A/B testing results further demonstrate its practical value. Supplement is available at: https://github.com/fanqieCoffee/SITN-Supplement.
Towards the Desirable Decision Boundary by Moderate-Margin Adversarial Training
Jul 16, 2022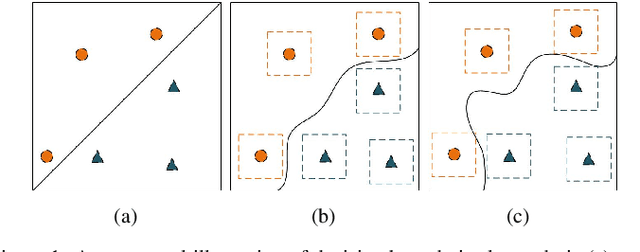
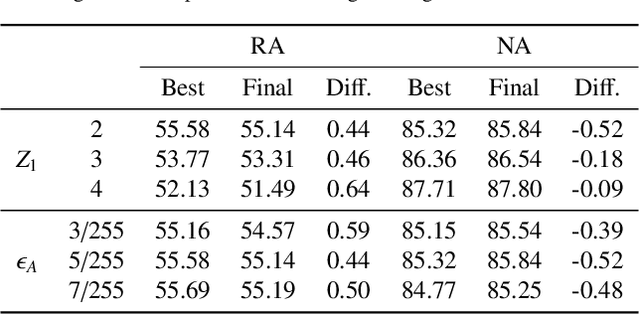

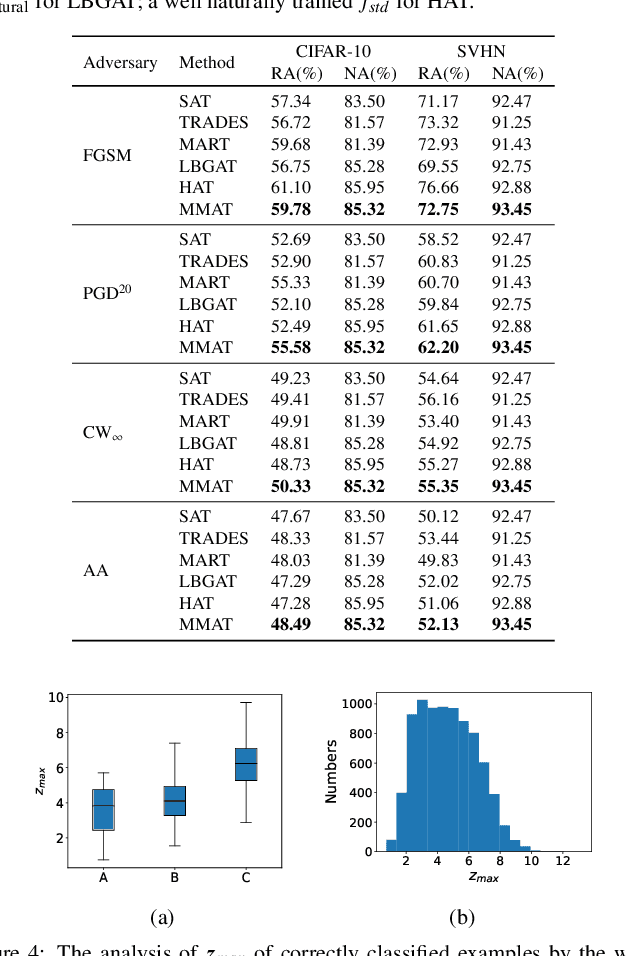
Adversarial training, as one of the most effective defense methods against adversarial attacks, tends to learn an inclusive decision boundary to increase the robustness of deep learning models. However, due to the large and unnecessary increase in the margin along adversarial directions, adversarial training causes heavy cross-over between natural examples and adversarial examples, which is not conducive to balancing the trade-off between robustness and natural accuracy. In this paper, we propose a novel adversarial training scheme to achieve a better trade-off between robustness and natural accuracy. It aims to learn a moderate-inclusive decision boundary, which means that the margins of natural examples under the decision boundary are moderate. We call this scheme Moderate-Margin Adversarial Training (MMAT), which generates finer-grained adversarial examples to mitigate the cross-over problem. We also take advantage of logits from a teacher model that has been well-trained to guide the learning of our model. Finally, MMAT achieves high natural accuracy and robustness under both black-box and white-box attacks. On SVHN, for example, state-of-the-art robustness and natural accuracy are achieved.
Treating Crowdsourcing as Examination: How to Score Tasks and Online Workers?
Apr 26, 2022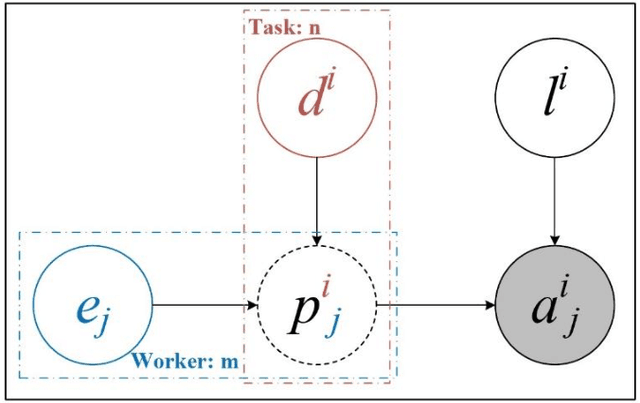

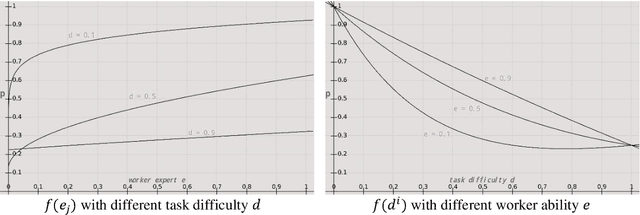
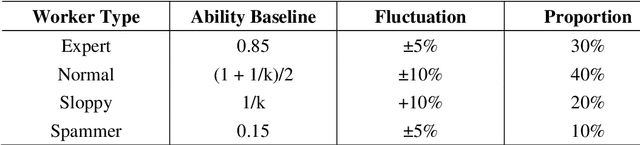
Crowdsourcing is an online outsourcing mode which can solve the current machine learning algorithm's urge need for massive labeled data. Requester posts tasks on crowdsourcing platforms, which employ online workers over the Internet to complete tasks, then aggregate and return results to requester. How to model the interaction between different types of workers and tasks is a hot spot. In this paper, we try to model workers as four types based on their ability: expert, normal worker, sloppy worker and spammer, and divide tasks into hard, medium and easy task according to their difficulty. We believe that even experts struggle with difficult tasks while sloppy workers can get easy tasks right, and spammers always give out wrong answers deliberately. So, good examination tasks should have moderate degree of difficulty and discriminability to score workers more objectively. Thus, we first score workers' ability mainly on the medium difficult tasks, then reducing the weight of answers from sloppy workers and modifying the answers from spammers when inferring the tasks' ground truth. A probability graph model is adopted to simulate the task execution process, and an iterative method is adopted to calculate and update the ground truth, the ability of workers and the difficulty of the task successively. We verify the rightness and effectiveness of our algorithm both in simulated and real crowdsourcing scenes.
Adversarial Attacks against Windows PE Malware Detection: A Survey of the State-of-the-Art
Dec 23, 2021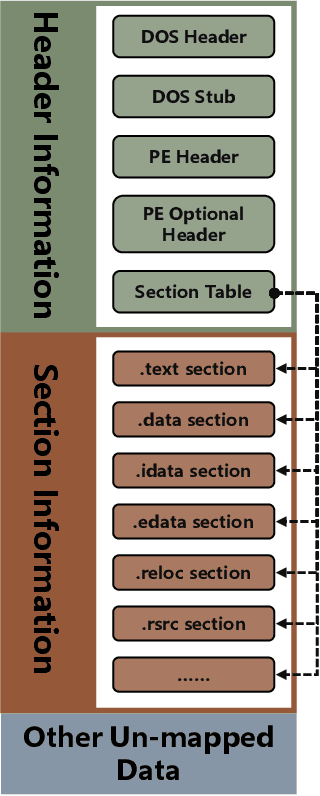
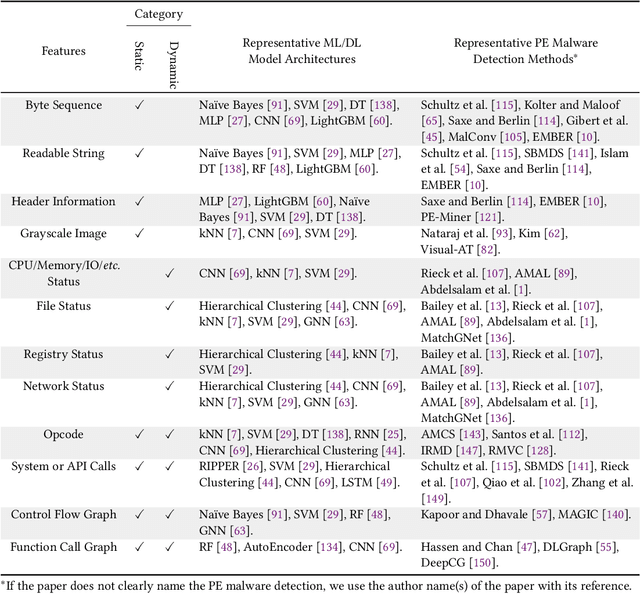
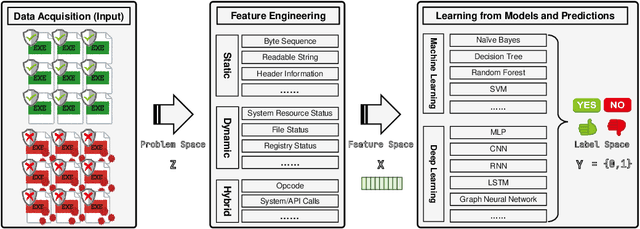
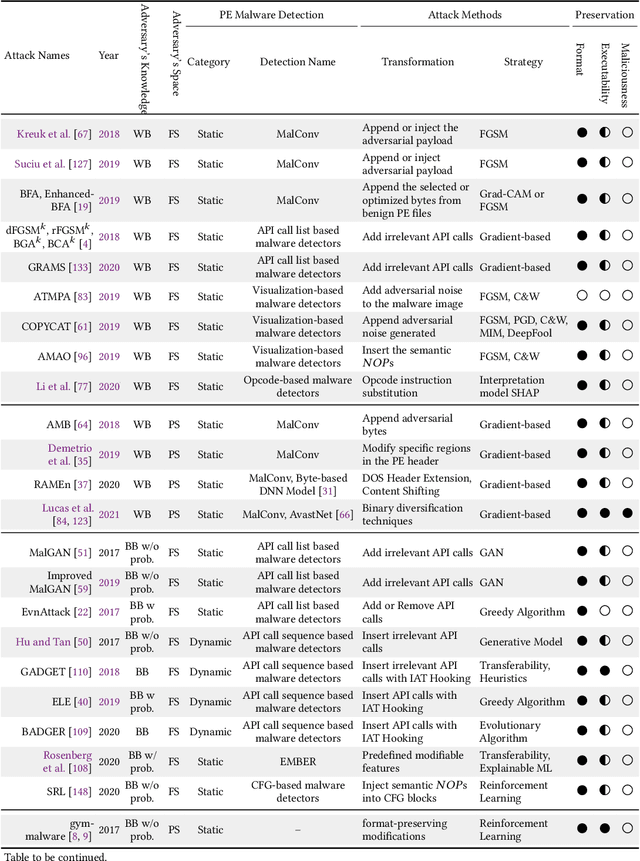
The malware has been being one of the most damaging threats to computers that span across multiple operating systems and various file formats. To defend against the ever-increasing and ever-evolving threats of malware, tremendous efforts have been made to propose a variety of malware detection methods that attempt to effectively and efficiently detect malware. Recent studies have shown that, on the one hand, existing ML and DL enable the superior detection of newly emerging and previously unseen malware. However, on the other hand, ML and DL models are inherently vulnerable to adversarial attacks in the form of adversarial examples, which are maliciously generated by slightly and carefully perturbing the legitimate inputs to confuse the targeted models. Basically, adversarial attacks are initially extensively studied in the domain of computer vision, and some quickly expanded to other domains, including NLP, speech recognition and even malware detection. In this paper, we focus on malware with the file format of portable executable (PE) in the family of Windows operating systems, namely Windows PE malware, as a representative case to study the adversarial attack methods in such adversarial settings. To be specific, we start by first outlining the general learning framework of Windows PE malware detection based on ML/DL and subsequently highlighting three unique challenges of performing adversarial attacks in the context of PE malware. We then conduct a comprehensive and systematic review to categorize the state-of-the-art adversarial attacks against PE malware detection, as well as corresponding defenses to increase the robustness of PE malware detection. We conclude the paper by first presenting other related attacks against Windows PE malware detection beyond the adversarial attacks and then shedding light on future research directions and opportunities.
Towards Imperceptible Adversarial Image Patches Based on Network Explanations
Dec 10, 2020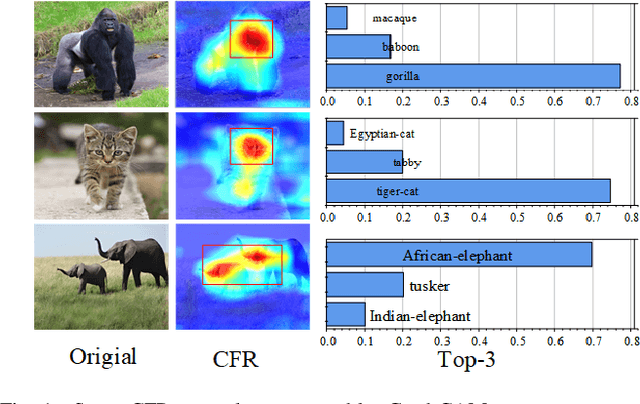
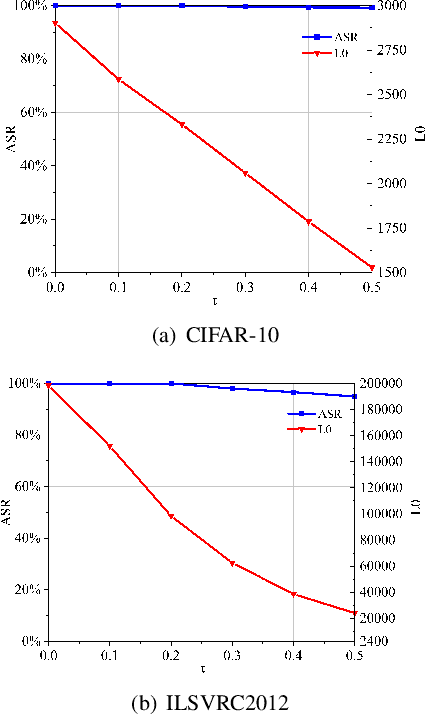

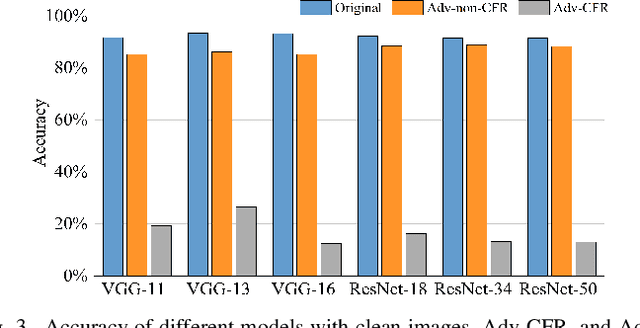
The vulnerability of deep neural networks (DNNs) for adversarial examples have attracted more attention. Many algorithms are proposed to craft powerful adversarial examples. However, these algorithms modifying the global or local region of pixels without taking into account network explanations. Hence, the perturbations are redundancy and easily detected by human eyes. In this paper, we propose a novel method to generate local region perturbations. The main idea is to find the contributing feature regions (CFRs) of images based on network explanations for perturbations. Due to the network explanations, the perturbations added to the CFRs are more effective than other regions. In our method, a soft mask matrix is designed to represent the CFRs for finely characterizing the contributions of each pixel. Based on this soft mask, we develop a new objective function with inverse temperature to search for optimal perturbations in CFRs. Extensive experiments are conducted on CIFAR-10 and ILSVRC2012, which demonstrate the effectiveness, including attack success rate, imperceptibility,and transferability.
Review: Deep Learning Methods for Cybersecurity and Intrusion Detection Systems
Dec 04, 2020
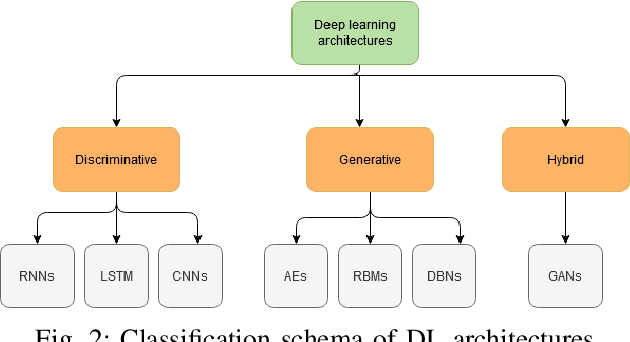
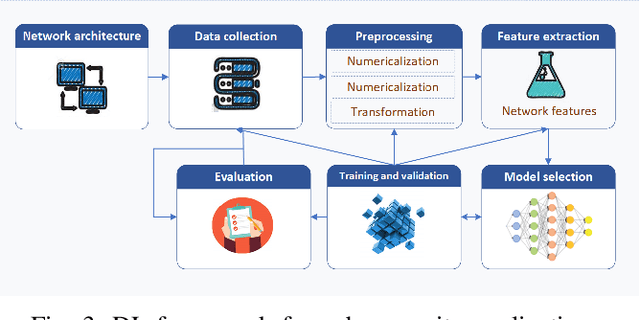
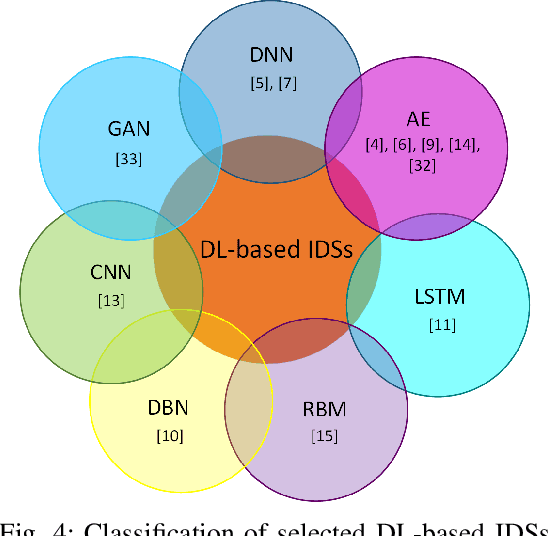
As the number of cyber-attacks is increasing, cybersecurity is evolving to a key concern for any business. Artificial Intelligence (AI) and Machine Learning (ML) (in particular Deep Learning - DL) can be leveraged as key enabling technologies for cyber-defense, since they can contribute in threat detection and can even provide recommended actions to cyber analysts. A partnership of industry, academia, and government on a global scale is necessary in order to advance the adoption of AI/ML to cybersecurity and create efficient cyber defense systems. In this paper, we are concerned with the investigation of the various deep learning techniques employed for network intrusion detection and we introduce a DL framework for cybersecurity applications.