 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.
Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable
May 20, 2025Existing detectors are often trained on biased datasets, leading to the possibility of overfitting on non-causal image attributes that are spuriously correlated with real/synthetic labels. While these biased features enhance performance on the training data, they result in substantial performance degradation when applied to unbiased datasets. One common solution is to perform dataset alignment through generative reconstruction, matching the semantic content between real and synthetic images. However, we revisit this approach and show that pixel-level alignment alone is insufficient. The reconstructed images still suffer from frequency-level misalignment, which can perpetuate spurious correlations. To illustrate, we observe that reconstruction models tend to restore the high-frequency details lost in real images (possibly due to JPEG compression), inadvertently creating a frequency-level misalignment, where synthetic images appear to have richer high-frequency content than real ones. This misalignment leads to models associating high-frequency features with synthetic labels, further reinforcing biased cues. To resolve this, we propose Dual Data Alignment (DDA), which aligns both the pixel and frequency domains. Moreover, we introduce two new test sets: DDA-COCO, containing DDA-aligned synthetic images for testing detector performance on the most aligned dataset, and EvalGEN, featuring the latest generative models for assessing detectors under new generative architectures such as visual auto-regressive generators. Finally, our extensive evaluations demonstrate that a detector trained exclusively on DDA-aligned MSCOCO could improve across 8 diverse benchmarks by a non-trivial margin, showing a +7.2% on in-the-wild benchmarks, highlighting the improved generalizability of unbiased detectors.
Antidote: A Unified Framework for Mitigating LVLM Hallucinations in Counterfactual Presupposition and Object Perception
Apr 29, 2025
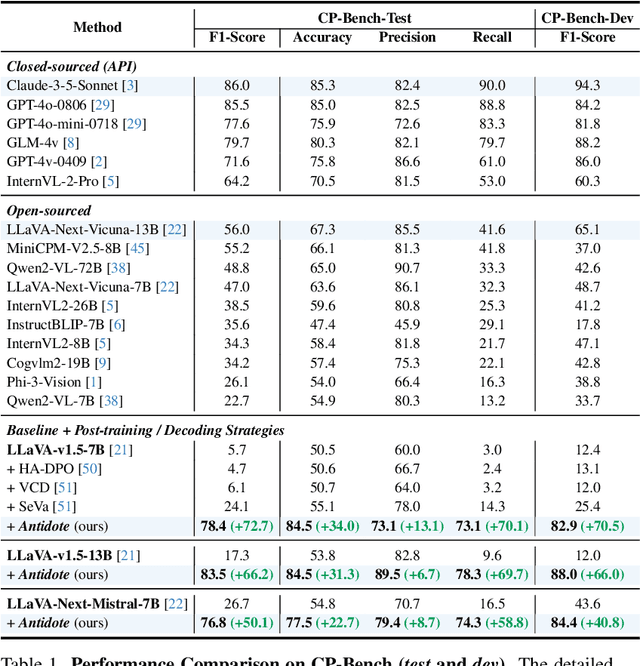

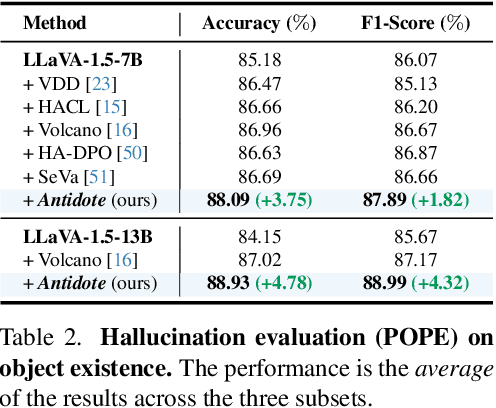
Large Vision-Language Models (LVLMs) have achieved impressive results across various cross-modal tasks. However, hallucinations, i.e., the models generating counterfactual responses, remain a challenge. Though recent studies have attempted to alleviate object perception hallucinations, they focus on the models' response generation, and overlooking the task question itself. This paper discusses the vulnerability of LVLMs in solving counterfactual presupposition questions (CPQs), where the models are prone to accept the presuppositions of counterfactual objects and produce severe hallucinatory responses. To this end, we introduce "Antidote", a unified, synthetic data-driven post-training framework for mitigating both types of hallucination above. It leverages synthetic data to incorporate factual priors into questions to achieve self-correction, and decouple the mitigation process into a preference optimization problem. Furthermore, we construct "CP-Bench", a novel benchmark to evaluate LVLMs' ability to correctly handle CPQs and produce factual responses. Applied to the LLaVA series, Antidote can simultaneously enhance performance on CP-Bench by over 50%, POPE by 1.8-3.3%, and CHAIR & SHR by 30-50%, all without relying on external supervision from stronger LVLMs or human feedback and introducing noticeable catastrophic forgetting issues.
All Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning
Apr 02, 2025The exponential growth of AI-generated images (AIGIs) underscores the urgent need for robust and generalizable detection methods. In this paper, we establish two key principles for AIGI detection through systematic analysis: \textbf{(1) All Patches Matter:} Unlike conventional image classification where discriminative features concentrate on object-centric regions, each patch in AIGIs inherently contains synthetic artifacts due to the uniform generation process, suggesting that every patch serves as an important artifact source for detection. \textbf{(2) More Patches Better}: Leveraging distributed artifacts across more patches improves detection robustness by capturing complementary forensic evidence and reducing over-reliance on specific patches, thereby enhancing robustness and generalization. However, our counterfactual analysis reveals an undesirable phenomenon: naively trained detectors often exhibit a \textbf{Few-Patch Bias}, discriminating between real and synthetic images based on minority patches. We identify \textbf{Lazy Learner} as the root cause: detectors preferentially learn conspicuous artifacts in limited patches while neglecting broader artifact distributions. To address this bias, we propose the \textbf{P}anoptic \textbf{P}atch \textbf{L}earning (PPL) framework, involving: (1) Random Patch Replacement that randomly substitutes synthetic patches with real counterparts to compel models to identify artifacts in underutilized regions, encouraging the broader use of more patches; (2) Patch-wise Contrastive Learning that enforces consistent discriminative capability across all patches, ensuring uniform utilization of all patches. Extensive experiments across two different settings on several benchmarks verify the effectiveness of our approach.
Exploring the Collaborative Advantage of Low-level Information on Generalizable AI-Generated Image Detection
Apr 01, 2025



Existing state-of-the-art AI-Generated image detection methods mostly consider extracting low-level information from RGB images to help improve the generalization of AI-Generated image detection, such as noise patterns. However, these methods often consider only a single type of low-level information, which may lead to suboptimal generalization. Through empirical analysis, we have discovered a key insight: different low-level information often exhibits generalization capabilities for different types of forgeries. Furthermore, we found that simple fusion strategies are insufficient to leverage the detection advantages of each low-level and high-level information for various forgery types. Therefore, we propose the Adaptive Low-level Experts Injection (ALEI) framework. Our approach introduces Lora Experts, enabling the backbone network, which is trained with high-level semantic RGB images, to accept and learn knowledge from different low-level information. We utilize a cross-attention method to adaptively fuse these features at intermediate layers. To prevent the backbone network from losing the modeling capabilities of different low-level features during the later stages of modeling, we developed a Low-level Information Adapter that interacts with the features extracted by the backbone network. Finally, we propose Dynamic Feature Selection, which dynamically selects the most suitable features for detecting the current image to maximize generalization detection capability. Extensive experiments demonstrate that our method, finetuned on only four categories of mainstream ProGAN data, performs excellently and achieves state-of-the-art results on multiple datasets containing unseen GAN and Diffusion methods.
Data Synthesis with Diverse Styles for Face Recognition via 3DMM-Guided Diffusion
Apr 01, 2025



Identity-preserving face synthesis aims to generate synthetic face images of virtual subjects that can substitute real-world data for training face recognition models. While prior arts strive to create images with consistent identities and diverse styles, they face a trade-off between them. Identifying their limitation of treating style variation as subject-agnostic and observing that real-world persons actually have distinct, subject-specific styles, this paper introduces MorphFace, a diffusion-based face generator. The generator learns fine-grained facial styles, e.g., shape, pose and expression, from the renderings of a 3D morphable model (3DMM). It also learns identities from an off-the-shelf recognition model. To create virtual faces, the generator is conditioned on novel identities of unlabeled synthetic faces, and novel styles that are statistically sampled from a real-world prior distribution. The sampling especially accounts for both intra-subject variation and subject distinctiveness. A context blending strategy is employed to enhance the generator's responsiveness to identity and style conditions. Extensive experiments show that MorphFace outperforms the best prior arts in face recognition efficacy.
ToVE: Efficient Vision-Language Learning via Knowledge Transfer from Vision Experts
Apr 01, 2025



Vision-language (VL) learning requires extensive visual perception capabilities, such as fine-grained object recognition and spatial perception. Recent works typically rely on training huge models on massive datasets to develop these capabilities. As a more efficient alternative, this paper proposes a new framework that Transfers the knowledge from a hub of Vision Experts (ToVE) for efficient VL learning, leveraging pre-trained vision expert models to promote visual perception capability. Specifically, building on a frozen CLIP encoder that provides vision tokens for image-conditioned language generation, ToVE introduces a hub of multiple vision experts and a token-aware gating network that dynamically routes expert knowledge to vision tokens. In the transfer phase, we propose a "residual knowledge transfer" strategy, which not only preserves the generalizability of the vision tokens but also allows detachment of low-contributing experts to improve inference efficiency. Further, we explore to merge these expert knowledge to a single CLIP encoder, creating a knowledge-merged CLIP that produces more informative vision tokens without expert inference during deployment. Experiment results across various VL tasks demonstrate that the proposed ToVE achieves competitive performance with two orders of magnitude fewer training data.
PVTree: Realistic and Controllable Palm Vein Generation for Recognition Tasks
Mar 04, 2025Palm vein recognition is an emerging biometric technology that offers enhanced security and privacy. However, acquiring sufficient palm vein data for training deep learning-based recognition models is challenging due to the high costs of data collection and privacy protection constraints. This has led to a growing interest in generating pseudo-palm vein data using generative models. Existing methods, however, often produce unrealistic palm vein patterns or struggle with controlling identity and style attributes. To address these issues, we propose a novel palm vein generation framework named PVTree. First, the palm vein identity is defined by a complex and authentic 3D palm vascular tree, created using an improved Constrained Constructive Optimization (CCO) algorithm. Second, palm vein patterns of the same identity are generated by projecting the same 3D vascular tree into 2D images from different views and converting them into realistic images using a generative model. As a result, PVTree satisfies the need for both identity consistency and intra-class diversity. Extensive experiments conducted on several publicly available datasets demonstrate that our proposed palm vein generation method surpasses existing methods and achieves a higher TAR@FAR=1e-4 under the 1:1 Open-set protocol. To the best of our knowledge, this is the first time that the performance of a recognition model trained on synthetic palm vein data exceeds that of the recognition model trained on real data, which indicates that palm vein image generation research has a promising future.
UIFace: Unleashing Inherent Model Capabilities to Enhance Intra-Class Diversity in Synthetic Face Recognition
Feb 27, 2025



Face recognition (FR) stands as one of the most crucial applications in computer vision. The accuracy of FR models has significantly improved in recent years due to the availability of large-scale human face datasets. However, directly using these datasets can inevitably lead to privacy and legal problems. Generating synthetic data to train FR models is a feasible solution to circumvent these issues. While existing synthetic-based face recognition methods have made significant progress in generating identity-preserving images, they are severely plagued by context overfitting, resulting in a lack of intra-class diversity of generated images and poor face recognition performance. In this paper, we propose a framework to Unleash Inherent capability of the model to enhance intra-class diversity for synthetic face recognition, shortened as UIFace. Our framework first trains a diffusion model that can perform sampling conditioned on either identity contexts or a learnable empty context. The former generates identity-preserving images but lacks variations, while the latter exploits the model's intrinsic ability to synthesize intra-class-diversified images but with random identities. Then we adopt a novel two-stage sampling strategy during inference to fully leverage the strengths of both types of contexts, resulting in images that are diverse as well as identitypreserving. Moreover, an attention injection module is introduced to further augment the intra-class variations by utilizing attention maps from the empty context to guide the sampling process in ID-conditioned generation. Experiments show that our method significantly surpasses previous approaches with even less training data and half the size of synthetic dataset. The proposed UIFace even achieves comparable performance with FR models trained on real datasets when we further increase the number of synthetic identities.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.