 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntidote: A Unified Framework for Mitigating LVLM Hallucinations in Counterfactual Presupposition and Object Perception
Apr 29, 2025
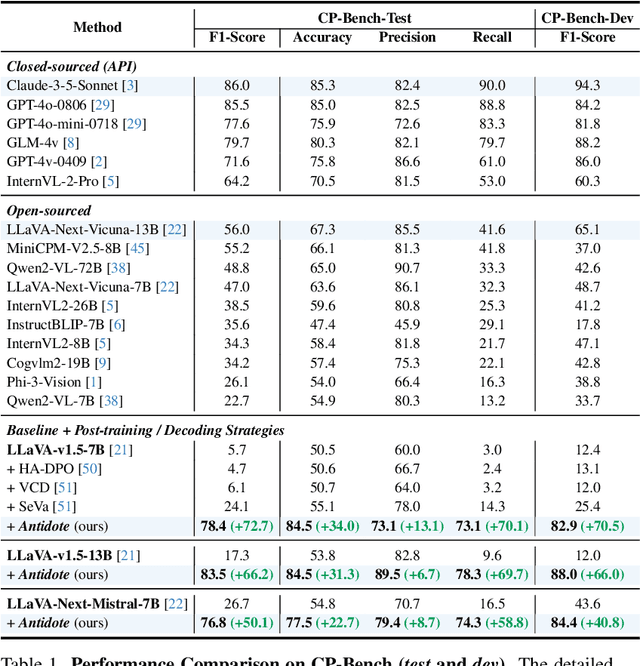

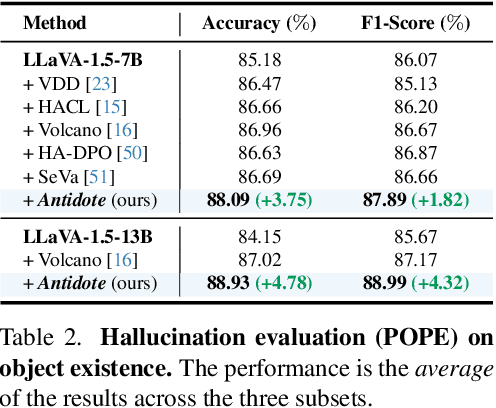
Large Vision-Language Models (LVLMs) have achieved impressive results across various cross-modal tasks. However, hallucinations, i.e., the models generating counterfactual responses, remain a challenge. Though recent studies have attempted to alleviate object perception hallucinations, they focus on the models' response generation, and overlooking the task question itself. This paper discusses the vulnerability of LVLMs in solving counterfactual presupposition questions (CPQs), where the models are prone to accept the presuppositions of counterfactual objects and produce severe hallucinatory responses. To this end, we introduce "Antidote", a unified, synthetic data-driven post-training framework for mitigating both types of hallucination above. It leverages synthetic data to incorporate factual priors into questions to achieve self-correction, and decouple the mitigation process into a preference optimization problem. Furthermore, we construct "CP-Bench", a novel benchmark to evaluate LVLMs' ability to correctly handle CPQs and produce factual responses. Applied to the LLaVA series, Antidote can simultaneously enhance performance on CP-Bench by over 50%, POPE by 1.8-3.3%, and CHAIR & SHR by 30-50%, all without relying on external supervision from stronger LVLMs or human feedback and introducing noticeable catastrophic forgetting issues.
Exploration of Class Center for Fine-Grained Visual Classification
Jul 05, 2024Different from large-scale classification tasks, fine-grained visual classification is a challenging task due to two critical problems: 1) evident intra-class variances and subtle inter-class differences, and 2) overfitting owing to fewer training samples in datasets. Most existing methods extract key features to reduce intra-class variances, but pay no attention to subtle inter-class differences in fine-grained visual classification. To address this issue, we propose a loss function named exploration of class center, which consists of a multiple class-center constraint and a class-center label generation. This loss function fully utilizes the information of the class center from the perspective of features and labels. From the feature perspective, the multiple class-center constraint pulls samples closer to the target class center, and pushes samples away from the most similar nontarget class center. Thus, the constraint reduces intra-class variances and enlarges inter-class differences. From the label perspective, the class-center label generation utilizes classcenter distributions to generate soft labels to alleviate overfitting. Our method can be easily integrated with existing fine-grained visual classification approaches as a loss function, to further boost excellent performance with only slight training costs. Extensive experiments are conducted to demonstrate consistent improvements achieved by our method on four widely-used fine-grained visual classification datasets. In particular, our method achieves state-of-the-art performance on the FGVC-Aircraft and CUB-200-2011 datasets.
GLAD: Towards Better Reconstruction with Global and Local Adaptive Diffusion Models for Unsupervised Anomaly Detection
Jun 11, 2024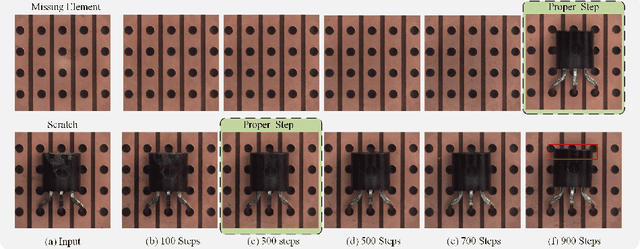
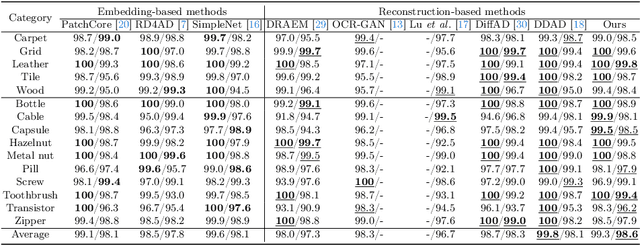

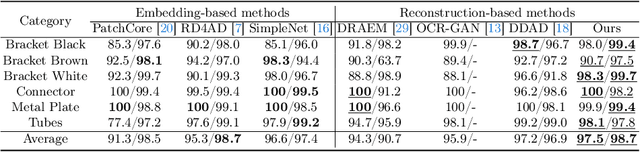
Diffusion models have shown superior performance on unsupervised anomaly detection tasks. Since trained with normal data only, diffusion models tend to reconstruct normal counterparts of test images with certain noises added. However, these methods treat all potential anomalies equally, which may cause two main problems. From the global perspective, the difficulty of reconstructing images with different anomalies is uneven. Therefore, instead of utilizing the same setting for all samples, we propose to predict a particular denoising step for each sample by evaluating the difference between image contents and the priors extracted from diffusion models. From the local perspective, reconstructing abnormal regions differs from normal areas even in the same image. Theoretically, the diffusion model predicts a noise for each step, typically following a standard Gaussian distribution. However, due to the difference between the anomaly and its potential normal counterpart, the predicted noise in abnormal regions will inevitably deviate from the standard Gaussian distribution. To this end, we propose introducing synthetic abnormal samples in training to encourage the diffusion models to break through the limitation of standard Gaussian distribution, and a spatial-adaptive feature fusion scheme is utilized during inference. With the above modifications, we propose a global and local adaptive diffusion model (abbreviated to GLAD) for unsupervised anomaly detection, which introduces appealing flexibility and achieves anomaly-free reconstruction while retaining as much normal information as possible. Extensive experiments are conducted on three commonly used anomaly detection datasets (MVTec-AD, MPDD, and VisA) and a printed circuit board dataset (PCB-Bank) we integrated, showing the effectiveness of the proposed method.