 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRROR: Manifold Ideal Reference ReconstructOR for Generalizable AI-Generated Image Detection
Feb 02, 2026High-fidelity generative models have narrowed the perceptual gap between synthetic and real images, posing serious threats to media security. Most existing AI-generated image (AIGI) detectors rely on artifact-based classification and struggle to generalize to evolving generative traces. In contrast, human judgment relies on stable real-world regularities, with deviations from the human cognitive manifold serving as a more generalizable signal of forgery. Motivated by this insight, we reformulate AIGI detection as a Reference-Comparison problem that verifies consistency with the real-image manifold rather than fitting specific forgery cues. We propose MIRROR (Manifold Ideal Reference ReconstructOR), a framework that explicitly encodes reality priors using a learnable discrete memory bank. MIRROR projects an input into a manifold-consistent ideal reference via sparse linear combination, and uses the resulting residuals as robust detection signals. To evaluate whether detectors reach the "superhuman crossover" required to replace human experts, we introduce the Human-AIGI benchmark, featuring a psychophysically curated human-imperceptible subset. Across 14 benchmarks, MIRROR consistently outperforms prior methods, achieving gains of 2.1% on six standard benchmarks and 8.1% on seven in-the-wild benchmarks. On Human-AIGI, MIRROR reaches 89.6% accuracy across 27 generators, surpassing both lay users and visual experts, and further approaching the human perceptual limit as pretrained backbones scale. The code is publicly available at: https://github.com/349793927/MIRROR
Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable
May 20, 2025Existing detectors are often trained on biased datasets, leading to the possibility of overfitting on non-causal image attributes that are spuriously correlated with real/synthetic labels. While these biased features enhance performance on the training data, they result in substantial performance degradation when applied to unbiased datasets. One common solution is to perform dataset alignment through generative reconstruction, matching the semantic content between real and synthetic images. However, we revisit this approach and show that pixel-level alignment alone is insufficient. The reconstructed images still suffer from frequency-level misalignment, which can perpetuate spurious correlations. To illustrate, we observe that reconstruction models tend to restore the high-frequency details lost in real images (possibly due to JPEG compression), inadvertently creating a frequency-level misalignment, where synthetic images appear to have richer high-frequency content than real ones. This misalignment leads to models associating high-frequency features with synthetic labels, further reinforcing biased cues. To resolve this, we propose Dual Data Alignment (DDA), which aligns both the pixel and frequency domains. Moreover, we introduce two new test sets: DDA-COCO, containing DDA-aligned synthetic images for testing detector performance on the most aligned dataset, and EvalGEN, featuring the latest generative models for assessing detectors under new generative architectures such as visual auto-regressive generators. Finally, our extensive evaluations demonstrate that a detector trained exclusively on DDA-aligned MSCOCO could improve across 8 diverse benchmarks by a non-trivial margin, showing a +7.2% on in-the-wild benchmarks, highlighting the improved generalizability of unbiased detectors.
All Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning
Apr 02, 2025The exponential growth of AI-generated images (AIGIs) underscores the urgent need for robust and generalizable detection methods. In this paper, we establish two key principles for AIGI detection through systematic analysis: \textbf{(1) All Patches Matter:} Unlike conventional image classification where discriminative features concentrate on object-centric regions, each patch in AIGIs inherently contains synthetic artifacts due to the uniform generation process, suggesting that every patch serves as an important artifact source for detection. \textbf{(2) More Patches Better}: Leveraging distributed artifacts across more patches improves detection robustness by capturing complementary forensic evidence and reducing over-reliance on specific patches, thereby enhancing robustness and generalization. However, our counterfactual analysis reveals an undesirable phenomenon: naively trained detectors often exhibit a \textbf{Few-Patch Bias}, discriminating between real and synthetic images based on minority patches. We identify \textbf{Lazy Learner} as the root cause: detectors preferentially learn conspicuous artifacts in limited patches while neglecting broader artifact distributions. To address this bias, we propose the \textbf{P}anoptic \textbf{P}atch \textbf{L}earning (PPL) framework, involving: (1) Random Patch Replacement that randomly substitutes synthetic patches with real counterparts to compel models to identify artifacts in underutilized regions, encouraging the broader use of more patches; (2) Patch-wise Contrastive Learning that enforces consistent discriminative capability across all patches, ensuring uniform utilization of all patches. Extensive experiments across two different settings on several benchmarks verify the effectiveness of our approach.
Decoupled Data Augmentation for Improving Image Classification
Oct 29, 2024



Recent advancements in image mixing and generative data augmentation have shown promise in enhancing image classification. However, these techniques face the challenge of balancing semantic fidelity with diversity. Specifically, image mixing involves interpolating two images to create a new one, but this pixel-level interpolation can compromise fidelity. Generative augmentation uses text-to-image generative models to synthesize or modify images, often limiting diversity to avoid generating out-of-distribution data that potentially affects accuracy. We propose that this fidelity-diversity dilemma partially stems from the whole-image paradigm of existing methods. Since an image comprises the class-dependent part (CDP) and the class-independent part (CIP), where each part has fundamentally different impacts on the image's fidelity, treating different parts uniformly can therefore be misleading. To address this fidelity-diversity dilemma, we introduce Decoupled Data Augmentation (De-DA), which resolves the dilemma by separating images into CDPs and CIPs and handling them adaptively. To maintain fidelity, we use generative models to modify real CDPs under controlled conditions, preserving semantic consistency. To enhance diversity, we replace the image's CIP with inter-class variants, creating diverse CDP-CIP combinations. Additionally, we implement an online randomized combination strategy during training to generate numerous distinct CDP-CIP combinations cost-effectively. Comprehensive empirical evaluations validate the effectiveness of our method.
Temporal Gradient Inversion Attacks with Robust Optimization
Jun 13, 2023



Federated Learning (FL) has emerged as a promising approach for collaborative model training without sharing private data. However, privacy concerns regarding information exchanged during FL have received significant research attention. Gradient Inversion Attacks (GIAs) have been proposed to reconstruct the private data retained by local clients from the exchanged gradients. While recovering private data, the data dimensions and the model complexity increase, which thwart data reconstruction by GIAs. Existing methods adopt prior knowledge about private data to overcome those challenges. In this paper, we first observe that GIAs with gradients from a single iteration fail to reconstruct private data due to insufficient dimensions of leaked gradients, complex model architectures, and invalid gradient information. We investigate a Temporal Gradient Inversion Attack with a Robust Optimization framework, called TGIAs-RO, which recovers private data without any prior knowledge by leveraging multiple temporal gradients. To eliminate the negative impacts of outliers, e.g., invalid gradients for collaborative optimization, robust statistics are proposed. Theoretical guarantees on the recovery performance and robustness of TGIAs-RO against invalid gradients are also provided. Extensive empirical results on MNIST, CIFAR10, ImageNet and Reuters 21578 datasets show that the proposed TGIAs-RO with 10 temporal gradients improves reconstruction performance compared to state-of-the-art methods, even for large batch sizes (up to 128), complex models like ResNet18, and large datasets like ImageNet (224*224 pixels). Furthermore, the proposed attack method inspires further exploration of privacy-preserving methods in the context of FL.
GraphCoCo: Graph Complementary Contrastive Learning
Mar 24, 2022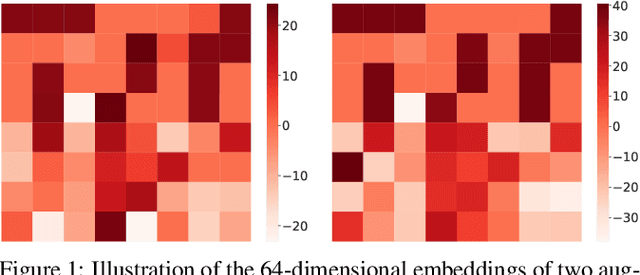
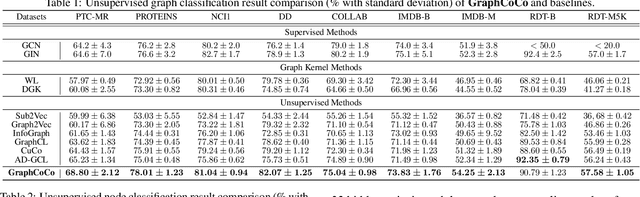
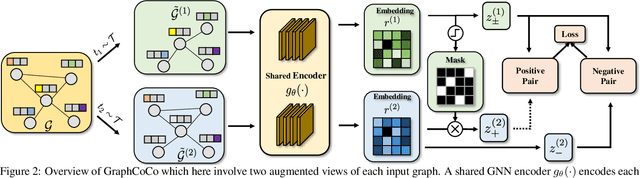
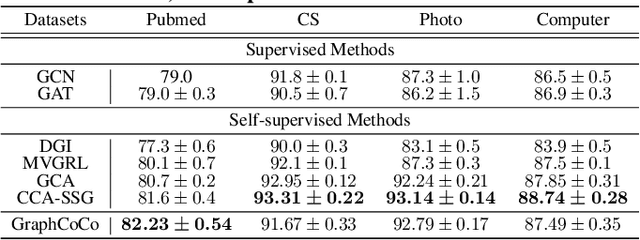
Graph Contrastive Learning (GCL) has shown promising performance in graph representation learning (GRL) without the supervision of manual annotations. GCL can generate graph-level embeddings by maximizing the Mutual Information (MI) between different augmented views of the same graph (positive pairs). However, we identify an obstacle that the optimization of InfoNCE loss only concentrates on a few embeddings dimensions, limiting the distinguishability of embeddings in downstream graph classification tasks. This paper proposes an effective graph complementary contrastive learning approach named GraphCoCo to tackle the above issue. Specifically, we set the embedding of the first augmented view as the anchor embedding to localize "highlighted" dimensions (i.e., the dimensions contribute most in similarity measurement). Then remove these dimensions in the embeddings of the second augmented view to discover neglected complementary representations. Therefore, the combination of anchor and complementary embeddings significantly improves the performance in downstream tasks. Comprehensive experiments on various benchmark datasets are conducted to demonstrate the effectiveness of GraphCoCo, and the results show that our model outperforms the state-of-the-art methods. Source code will be made publicly available.
Input-Specific Robustness Certification for Randomized Smoothing
Dec 21, 2021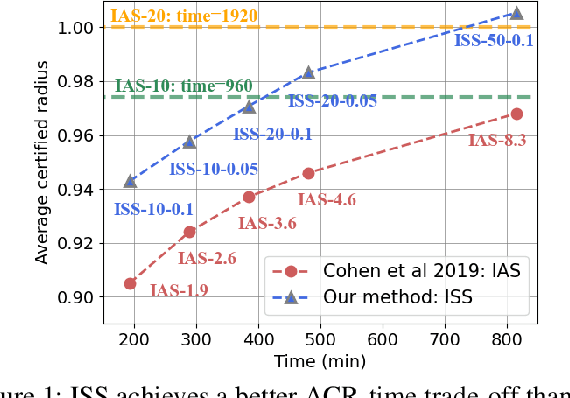
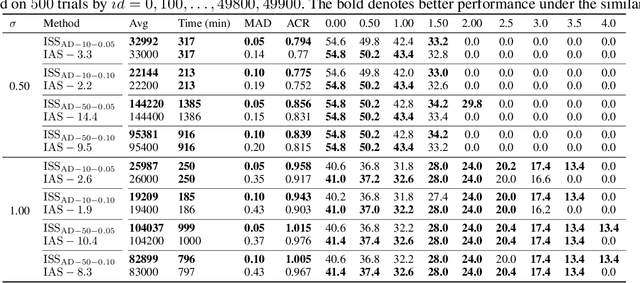
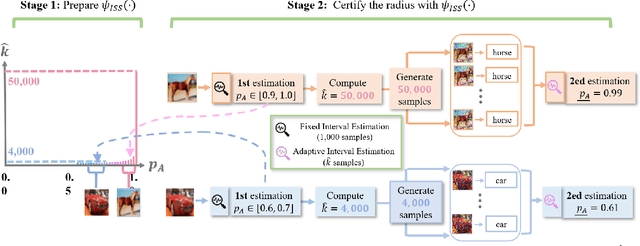
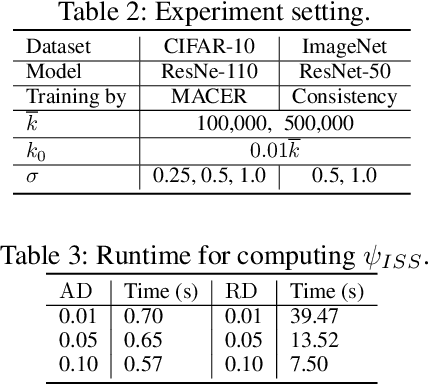
Although randomized smoothing has demonstrated high certified robustness and superior scalability to other certified defenses, the high computational overhead of the robustness certification bottlenecks the practical applicability, as it depends heavily on the large sample approximation for estimating the confidence interval. In existing works, the sample size for the confidence interval is universally set and agnostic to the input for prediction. This Input-Agnostic Sampling (IAS) scheme may yield a poor Average Certified Radius (ACR)-runtime trade-off which calls for improvement. In this paper, we propose Input-Specific Sampling (ISS) acceleration to achieve the cost-effectiveness for robustness certification, in an adaptive way of reducing the sampling size based on the input characteristic. Furthermore, our method universally controls the certified radius decline from the ISS sample size reduction. The empirical results on CIFAR-10 and ImageNet show that ISS can speed up the certification by more than three times at a limited cost of 0.05 certified radius. Meanwhile, ISS surpasses IAS on the average certified radius across the extensive hyperparameter settings. Specifically, ISS achieves ACR=0.958 on ImageNet ($\sigma=1.0$) in 250 minutes, compared to ACR=0.917 by IAS under the same condition. We release our code in \url{https://github.com/roy-ch/Input-Specific-Certification}.
Association: Remind Your GAN not to Forget
Nov 27, 2020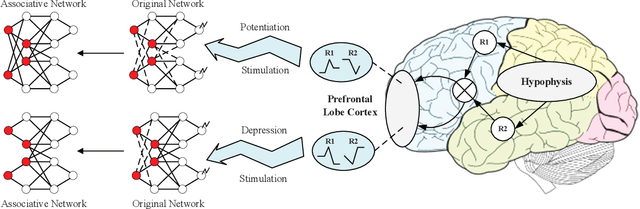
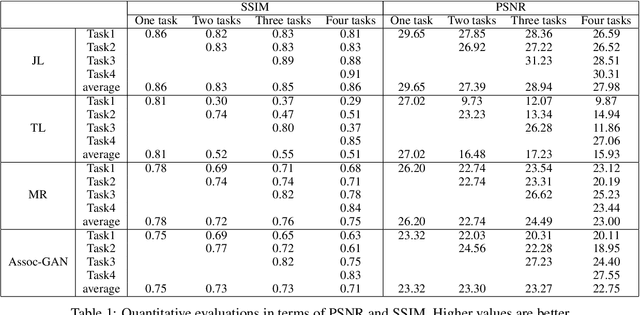
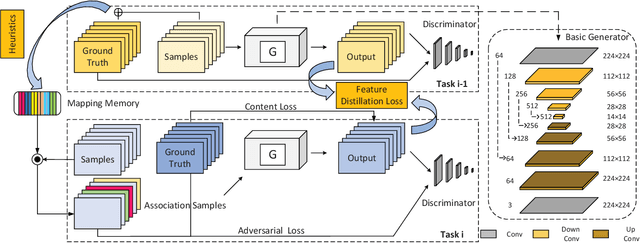

Neural networks are susceptible to catastrophic forgetting. They fail to preserve previously acquired knowledge when adapting to new tasks. Inspired by human associative memory system, we propose a brain-like approach that imitates the associative learning process to achieve continual learning. We design a heuristics mechanism to potentiatively stimulates the model, which guides the model to recall the historical episodes based on the current circumstance and obtained association experience. Besides, a distillation measure is added to depressively alter the efficacy of synaptic transmission, which dampens the feature reconstruction learning for new task. The framework is mediated by potentiation and depression stimulation that play opposing roles in directing synaptic and behavioral plasticity. It requires no access to the original data and is more similar to human cognitive process. Experiments demonstrate the effectiveness of our method in alleviating catastrophic forgetting on continual image reconstruction problems.
A Framework of Randomized Selection Based Certified Defenses Against Data Poisoning Attacks
Oct 13, 2020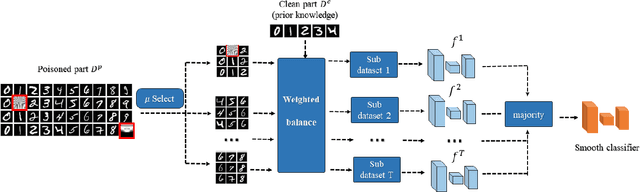
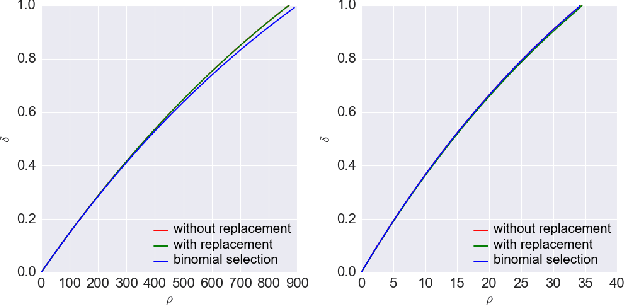
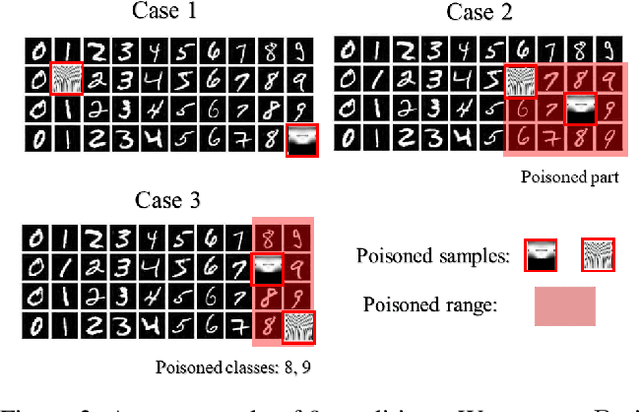
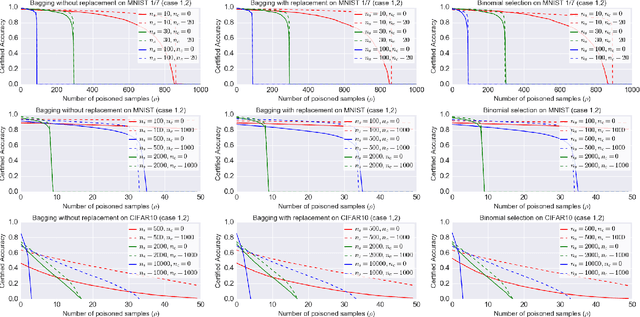
Neural network classifiers are vulnerable to data poisoning attacks, as attackers can degrade or even manipulate their predictions thorough poisoning only a few training samples. However, the robustness of heuristic defenses is hard to measure. Random selection based defenses can achieve certified robustness by averaging the classifiers' predictions on the sub-datasets sampled from the training set. This paper proposes a framework of random selection based certified defenses against data poisoning attacks. Specifically, we prove that the random selection schemes that satisfy certain conditions are robust against data poisoning attacks. We also derive the analytical form of the certified radius for the qualified random selection schemes. The certified radius of bagging derived by our framework is tighter than the previous work. Our framework allows users to improve robustness by leveraging prior knowledge about the training set and the poisoning model. Given higher level of prior knowledge, we can achieve higher certified accuracy both theoretically and practically. According to the experiments on three benchmark datasets: MNIST 1/7, MNIST, and CIFAR-10, our method outperforms the state-of-the-art.