 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Parameters to Feature Space: Task Arithmetic for Backdoor Mitigation in Model Merging
Jun 10, 2026Model merging (MM) has gained significant attention as a cost-effective approach to integrate multiple task-specific models into a unified model. However, recent work reveals that MM is highly susceptible to backdoor attacks. Existing defenses based on task arithmetic often fail to eliminate backdoors without substantially degrading clean-task performance, owing to their reliance on direct parameter-space editing. To address this gap, we propose Linear Feature Path Minimization (LFPM), a backdoor mitigation framework for model merging, which introduces an anti-backdoor task vector into the backdoored merged model. Unlike prior approaches, LFPM formulates the backdoor robustness of the merged model from a unified feature-space perspective under the Cross-Task Linearity (CTL) framework, which leverages the approximate linearity of features across tasks. This perspective guides the optimization of the anti-backdoor task to suppress backdoors while preserving clean-task performance. Furthermore, we introduce an effective optimization mechanism based on gradient accumulation and loss path-integral, ensuring robust backdoor suppression along the interpolation path. Extensive experiments demonstrate that LFPM consistently exhibits strong robustness against backdoor attacks in both full fine-tuning and Parameter-Efficient Fine-Tuning (PEFT) settings.
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025



Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.
Standing on the Shoulders of Giants: Reprogramming Visual-Language Model for General Deepfake Detection
Sep 04, 2024



The proliferation of deepfake faces poses huge potential negative impacts on our daily lives. Despite substantial advancements in deepfake detection over these years, the generalizability of existing methods against forgeries from unseen datasets or created by emerging generative models remains constrained. In this paper, inspired by the zero-shot advantages of Vision-Language Models (VLMs), we propose a novel approach that repurposes a well-trained VLM for general deepfake detection. Motivated by the model reprogramming paradigm that manipulates the model prediction via data perturbations, our method can reprogram a pretrained VLM model (e.g., CLIP) solely based on manipulating its input without tuning the inner parameters. Furthermore, we insert a pseudo-word guided by facial identity into the text prompt. Extensive experiments on several popular benchmarks demonstrate that (1) the cross-dataset and cross-manipulation performances of deepfake detection can be significantly and consistently improved (e.g., over 88% AUC in cross-dataset setting from FF++ to WildDeepfake) using a pre-trained CLIP model with our proposed reprogramming method; (2) our superior performances are at less cost of trainable parameters, making it a promising approach for real-world applications.
Single Image Dehazing Algorithm Based on Sky Region Segmentation
Jul 10, 2020
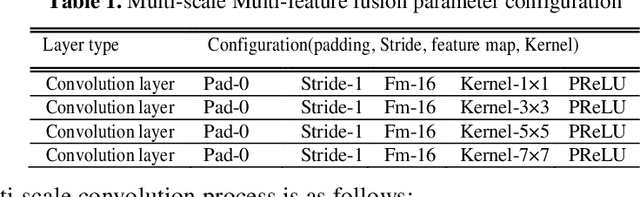
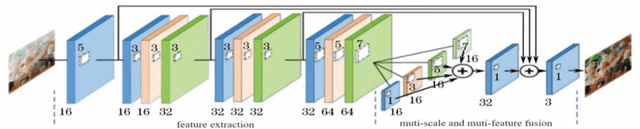
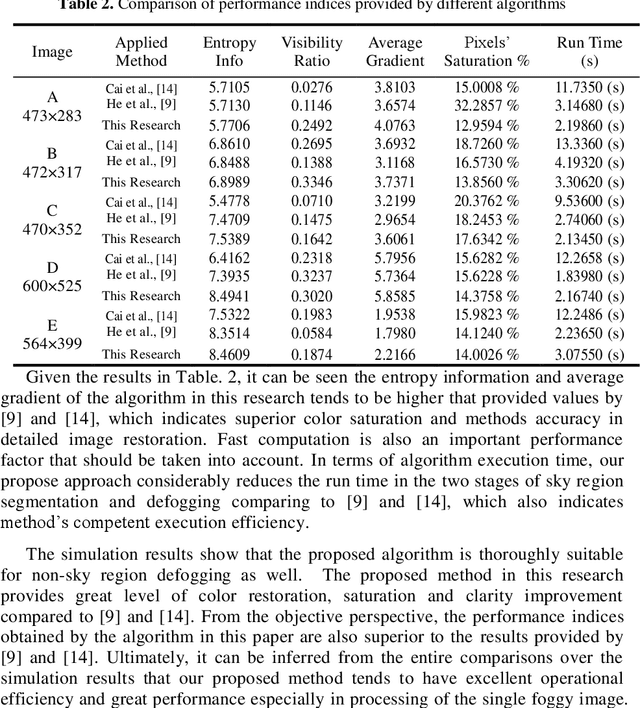
In this paper a hybrid image defogging approach based on region segmentation is proposed to address the dark channel priori algorithm's shortcomings in de-fogging the sky regions. The preliminary stage of the proposed approach focuses on the segmentation of sky and non-sky regions in a foggy image taking the advantageous of Meanshift and edge detection with embedded confidence. In the second stage, an improved dark channel priori algorithm is employed to defog the non-sky region. Ultimately, the sky area is processed by DehazeNet algorithm, which relies on deep learning Convolutional Neural Networks. The simulation results show that the proposed hybrid approach in this research addresses the problem of color distortion associated with sky regions in foggy images. The approach greatly improves the image quality indices including entropy information, visibility ratio of the edges, average gradient, and the saturation percentage with a very fast computation time, which is a good indication of the excellent performance of this model.