 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyMerge: Compressing 3D Gaussian Splats with Polytope Coverings for Provably Safe Resource-Constrained Navigation
Jun 15, 2026Obstacle avoidance is essential for safe navigation and motion planning. Recent radiance field reconstruction methods enable object detection and modeling with high fidelity, but remain too memory- and compute-intensive for on-board perception-based path planning. To address these limitations, we propose PolyMerge to convert a large, photorealistic 3D Gaussian Splatting (3DGS) model of a scene into a lightweight representation of convex polytopes whose union provably over-approximates all obstacles in the original 3DGS model. PolyMerge tunes the polytope count to trade off conservativeness and compute cost, and integrates with control barrier functions (CBFs) to plan collision-free paths. We showcase PolyMerge in simulation and hardware experiments on a Crazyflie drone, which uses PolyMerge to compute and follow safe trajectories in real time under severe onboard compute constraints, outperforming baselines in speed while guaranteeing safety. For our code and videos, visit https://athlon76.github.io/PolyMerge-website/.
Activation Steering of Video Generation Models via Reduced-Order Linear Optimal Control
Jun 03, 2026Text-to-video (T2V) models trained on large-scale web data can generate undesired content, motivating interventions that reduce harmful outputs without sacrificing visual quality. Activation steering offers an attractive mechanistic alternative to finetuning and prompt filtering, but existing T2V steering methods remain limited, typically applying coarse, non-anticipative interventions that can lead to oversteering and content degradation. To close this gap, we propose Latent Activation Linear-Quadratic Regulator (LA-LQR), a reduced-order optimal control framework for minimally invasive T2V steering. LA-LQR formulates T2V inference as a dynamical system and computes closed-loop feedback interventions that steer activations toward desired feature setpoints while penalizing unnecessary perturbations. To make optimal control feasible for high-dimensional video activations, we project activations onto a low-dimensional, task-relevant subspace derived from contrastive prompt pairs, estimate local linear dynamics in this latent space, and solve a latent LQR problem to obtain timestep- and layer-specific steering signals. We provide theoretical bounds relating latent setpoint tracking to raw activation-space feature control, and empirically validate the fidelity of the reduced latent dynamics. On concept steering and video safety benchmarks, LA-LQR reduces unsafe generations relative to baselines, while preserving prompt fidelity and visual quality.
KLIP: localized distribution shift detection via KL-divergence with diffusion priors in Inverse Problems
May 29, 2026Diffusion models have shown promising performance as data-driven priors for computational imaging, as well as some capacity to detect out-of-distribution (OOD) images. However, existing approaches to OOD detection often require some knowledge of the shifted distribution, fail to detect subtle or localized distribution shifts, and operate on full images, rather than the indirect measurements available in inverse problems. We propose an OOD detection metric based on the Kullback-Leibler divergence between the diffusion prior and the posterior distribution, that (i) does not require any calibration data or knowledge of the shifted distribution, and (ii) can detect whole images as OOD as well as localize OOD patches within an image. Experimentally, we show that this metric can detect subtle yet semantically meaningful distribution shifts, such as the shift from healthy liver CT scans to those with tumors, and generalizes across different types of diffusion models, datasets, and inverse problems. Our code can be found at https://github.com/voilalab/KLIP.
LongMamba: Enhancing Mamba's Long Context Capabilities via Training-Free Receptive Field Enlargement
Apr 22, 2025State space models (SSMs) have emerged as an efficient alternative to Transformer models for language modeling, offering linear computational complexity and constant memory usage as context length increases. However, despite their efficiency in handling long contexts, recent studies have shown that SSMs, such as Mamba models, generally underperform compared to Transformers in long-context understanding tasks. To address this significant shortfall and achieve both efficient and accurate long-context understanding, we propose LongMamba, a training-free technique that significantly enhances the long-context capabilities of Mamba models. LongMamba builds on our discovery that the hidden channels in Mamba can be categorized into local and global channels based on their receptive field lengths, with global channels primarily responsible for long-context capability. These global channels can become the key bottleneck as the input context lengthens. Specifically, when input lengths largely exceed the training sequence length, global channels exhibit limitations in adaptively extend their receptive fields, leading to Mamba's poor long-context performance. The key idea of LongMamba is to mitigate the hidden state memory decay in these global channels by preventing the accumulation of unimportant tokens in their memory. This is achieved by first identifying critical tokens in the global channels and then applying token filtering to accumulate only those critical tokens. Through extensive benchmarking across synthetic and real-world long-context scenarios, LongMamba sets a new standard for Mamba's long-context performance, significantly extending its operational range without requiring additional training. Our code is available at https://github.com/GATECH-EIC/LongMamba.
Towards Fully-Automated Materials Discovery via Large-Scale Synthesis Dataset and Expert-Level LLM-as-a-Judge
Feb 23, 2025Materials synthesis is vital for innovations such as energy storage, catalysis, electronics, and biomedical devices. Yet, the process relies heavily on empirical, trial-and-error methods guided by expert intuition. Our work aims to support the materials science community by providing a practical, data-driven resource. We have curated a comprehensive dataset of 17K expert-verified synthesis recipes from open-access literature, which forms the basis of our newly developed benchmark, AlchemyBench. AlchemyBench offers an end-to-end framework that supports research in large language models applied to synthesis prediction. It encompasses key tasks, including raw materials and equipment prediction, synthesis procedure generation, and characterization outcome forecasting. We propose an LLM-as-a-Judge framework that leverages large language models for automated evaluation, demonstrating strong statistical agreement with expert assessments. Overall, our contributions offer a supportive foundation for exploring the capabilities of LLMs in predicting and guiding materials synthesis, ultimately paving the way for more efficient experimental design and accelerated innovation in materials science.
A Multi-State Diagnosis and Prognosis Framework with Feature Learning for Tool Condition Monitoring
Apr 30, 2018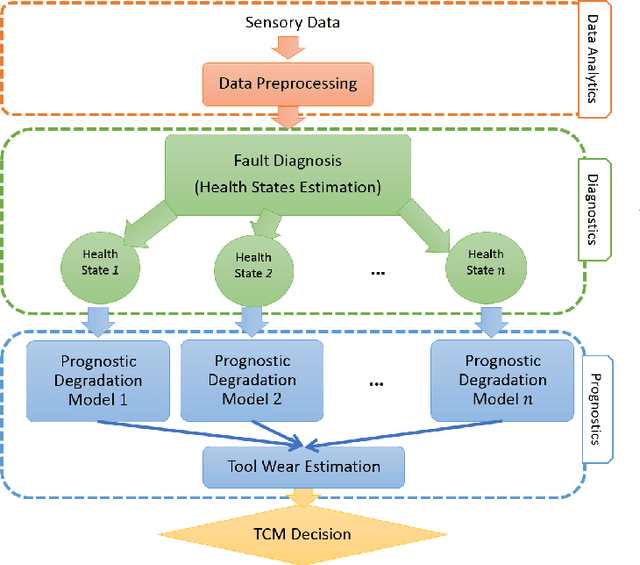
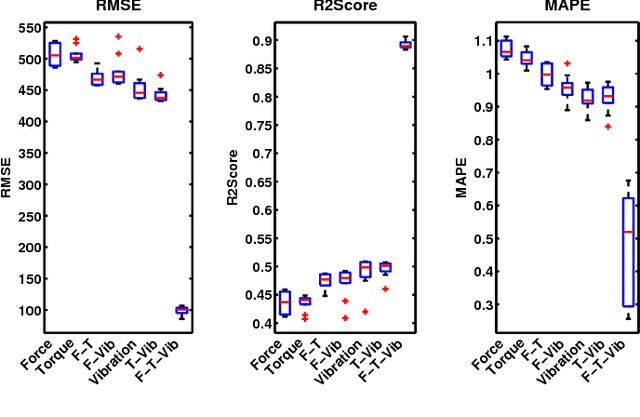
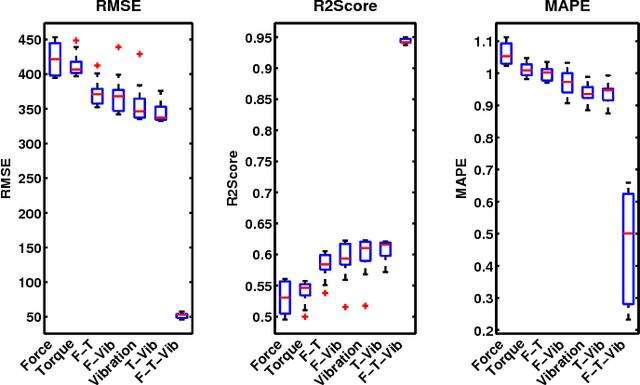
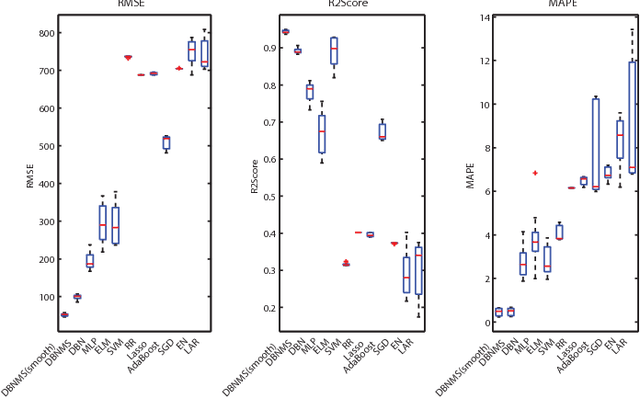
In this paper, a multi-state diagnosis and prognosis (MDP) framework is proposed for tool condition monitoring via a deep belief network based multi-state approach (DBNMS). For fault diagnosis, a cost-sensitive deep belief network (namely ECS-DBN) is applied to deal with the imbalanced data problem for tool state estimation. An appropriate prognostic degradation model is then applied for tool wear estimation based on the different tool states. The proposed framework has the advantage of automatic feature representation learning and shows better performance in accuracy and robustness. The effectiveness of the proposed DBNMS is validated using a real-world dataset obtained from the gun drilling process. This dataset contains a large amount of measured signals involving different tool geometries under various operating conditions. The DBNMS is examined for both the tool state estimation and tool wear estimation tasks. In the experimental studies, the prediction results are evaluated and compared with popular machine learning approaches, which show the superior performance of the proposed DBNMS approach.