 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Parameter Count: Implicit Bias in Soft Mixture of Experts
Sep 02, 2024



The traditional viewpoint on Sparse Mixture of Experts (MoE) models is that instead of training a single large expert, which is computationally expensive, we can train many small experts. The hope is that if the total parameter count of the small experts equals that of the singular large expert, then we retain the representation power of the large expert while gaining computational tractability and promoting expert specialization. The recently introduced Soft MoE replaces the Sparse MoE's discrete routing mechanism with a differentiable gating function that smoothly mixes tokens. While this smooth gating function successfully mitigates the various training instabilities associated with Sparse MoE, it is unclear whether it induces implicit biases that affect Soft MoE's representation power or potential for expert specialization. We prove that Soft MoE with a single arbitrarily powerful expert cannot represent simple convex functions. This justifies that Soft MoE's success cannot be explained by the traditional viewpoint of many small experts collectively mimicking the representation power of a single large expert, and that multiple experts are actually necessary to achieve good representation power (even for a fixed total parameter count). Continuing along this line of investigation, we introduce a notion of expert specialization for Soft MoE, and while varying the number of experts yet fixing the total parameter count, we consider the following (computationally intractable) task. Given any input, how can we discover the expert subset that is specialized to predict this input's label? We empirically show that when there are many small experts, the architecture is implicitly biased in a fashion that allows us to efficiently approximate the specialized expert subset. Our method can be easily implemented to potentially reduce computation during inference.
What is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
May 22, 2024



Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Full Shot Predictions for the DIII-D Tokamak via Deep Recurrent Networks
Apr 18, 2024



Although tokamaks are one of the most promising devices for realizing nuclear fusion as an energy source, there are still key obstacles when it comes to understanding the dynamics of the plasma and controlling it. As such, it is crucial that high quality models are developed to assist in overcoming these obstacles. In this work, we take an entirely data driven approach to learn such a model. In particular, we use historical data from the DIII-D tokamak to train a deep recurrent network that is able to predict the full time evolution of plasma discharges (or "shots"). Following this, we investigate how different training and inference procedures affect the quality and calibration of the shot predictions.
Beyond the Mud: Datasets and Benchmarks for Computer Vision in Off-Road Racing
Feb 12, 2024



Despite significant progress in optical character recognition (OCR) and computer vision systems, robustly recognizing text and identifying people in images taken in unconstrained \emph{in-the-wild} environments remain an ongoing challenge. However, such obstacles must be overcome in practical applications of vision systems, such as identifying racers in photos taken during off-road racing events. To this end, we introduce two new challenging real-world datasets - the off-road motorcycle Racer Number Dataset (RND) and the Muddy Racer re-iDentification Dataset (MUDD) - to highlight the shortcomings of current methods and drive advances in OCR and person re-identification (ReID) under extreme conditions. These two datasets feature over 6,300 images taken during off-road competitions which exhibit a variety of factors that undermine even modern vision systems, namely mud, complex poses, and motion blur. We establish benchmark performance on both datasets using state-of-the-art models. Off-the-shelf models transfer poorly, reaching only 15% end-to-end (E2E) F1 score on text spotting, and 33% rank-1 accuracy on ReID. Fine-tuning yields major improvements, bringing model performance to 53% F1 score for E2E text spotting and 79% rank-1 accuracy on ReID, but still falls short of good performance. Our analysis exposes open problems in real-world OCR and ReID that necessitate domain-targeted techniques. With these datasets and analysis of model limitations, we aim to foster innovations in handling real-world conditions like mud and complex poses to drive progress in robust computer vision. All data was sourced from PerformancePhoto.co, a website used by professional motorsports photographers, racers, and fans. The top-performing text spotting and ReID models are deployed on this platform to power real-time race photo search.
MUDD: A New Re-Identification Dataset with Efficient Annotation for Off-Road Racers in Extreme Conditions
Nov 14, 2023



Re-identifying individuals in unconstrained environments remains an open challenge in computer vision. We introduce the Muddy Racer re-IDentification Dataset (MUDD), the first large-scale benchmark for matching identities of motorcycle racers during off-road competitions. MUDD exhibits heavy mud occlusion, motion blurring, complex poses, and extreme lighting conditions previously unseen in existing re-id datasets. We present an annotation methodology incorporating auxiliary information that reduced labeling time by over 65%. We establish benchmark performance using state-of-the-art re-id models including OSNet and ResNet-50. Without fine-tuning, the best models achieve only 33% Rank-1 accuracy. Fine-tuning on MUDD boosts results to 79% Rank-1, but significant room for improvement remains. We analyze the impact of real-world factors including mud, pose, lighting, and more. Our work exposes open problems in re-identifying individuals under extreme conditions. We hope MUDD serves as a diverse and challenging benchmark to spur progress in robust re-id, especially for computer vision applications in emerging sports analytics. All code and data can be found at https://github.com/JacobTyo/MUDD.
Reading Between the Mud: A Challenging Motorcycle Racer Number Dataset
Nov 14, 2023



This paper introduces the off-road motorcycle Racer number Dataset (RnD), a new challenging dataset for optical character recognition (OCR) research. RnD contains 2,411 images from professional motorsports photographers that depict motorcycle racers in off-road competitions. The images exhibit a wide variety of factors that make OCR difficult, including mud occlusions, motion blur, non-standard fonts, glare, complex backgrounds, etc. The dataset has 5,578 manually annotated bounding boxes around visible motorcycle numbers, along with transcribed digits and letters. Our experiments benchmark leading OCR algorithms and reveal an end-to-end F1 score of only 0.527 on RnD, even after fine-tuning. Analysis of performance on different occlusion types shows mud as the primary challenge, degrading accuracy substantially compared to normal conditions. But the models struggle with other factors including glare, blur, shadows, and dust. Analysis exposes substantial room for improvement and highlights failure cases of existing models. RnD represents a valuable new benchmark to drive innovation in real-world OCR capabilities. The authors hope the community will build upon this dataset and baseline experiments to make progress on the open problem of robustly recognizing text in unconstrained natural environments. The dataset is available at https://github.com/JacobTyo/SwinTextSpotter.
Parity Calibration
Jun 07, 2023In a sequential regression setting, a decision-maker may be primarily concerned with whether the future observation will increase or decrease compared to the current one, rather than the actual value of the future observation. In this context, we introduce the notion of parity calibration, which captures the goal of calibrated forecasting for the increase-decrease (or "parity") event in a timeseries. Parity probabilities can be extracted from a forecasted distribution for the output, but we show that such a strategy leads to theoretical unpredictability and poor practical performance. We then observe that although the original task was regression, parity calibration can be expressed as binary calibration. Drawing on this connection, we use an online binary calibration method to achieve parity calibration. We demonstrate the effectiveness of our approach on real-world case studies in epidemiology, weather forecasting, and model-based control in nuclear fusion.
Bi-Manual Block Assembly via Sim-to-Real Reinforcement Learning
Mar 27, 2023



Most successes in robotic manipulation have been restricted to single-arm gripper robots, whose low dexterity limits the range of solvable tasks to pick-and-place, inser-tion, and object rearrangement. More complex tasks such as assembly require dual and multi-arm platforms, but entail a suite of unique challenges such as bi-arm coordination and collision avoidance, robust grasping, and long-horizon planning. In this work we investigate the feasibility of training deep reinforcement learning (RL) policies in simulation and transferring them to the real world (Sim2Real) as a generic methodology for obtaining performant controllers for real-world bi-manual robotic manipulation tasks. As a testbed for bi-manual manipulation, we develop the U-Shape Magnetic BlockAssembly Task, wherein two robots with parallel grippers must connect 3 magnetic blocks to form a U-shape. Without manually-designed controller nor human demonstrations, we demonstrate that with careful Sim2Real considerations, our policies trained with RL in simulation enable two xArm6 robots to solve the U-shape assembly task with a success rate of above90% in simulation, and 50% on real hardware without any additional real-world fine-tuning. Through careful ablations,we highlight how each component of the system is critical for such simple and successful policy learning and transfer,including task specification, learning algorithm, direct joint-space control, behavior constraints, perception and actuation noises, action delays and action interpolation. Our results present a significant step forward for bi-arm capability on real hardware, and we hope our system can inspire future research on deep RL and Sim2Real transfer of bi-manualpolicies, drastically scaling up the capability of real-world robot manipulators.
How Useful are Gradients for OOD Detection Really?
May 20, 2022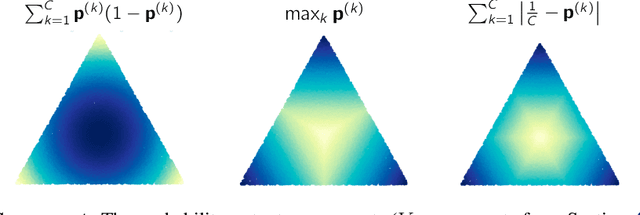
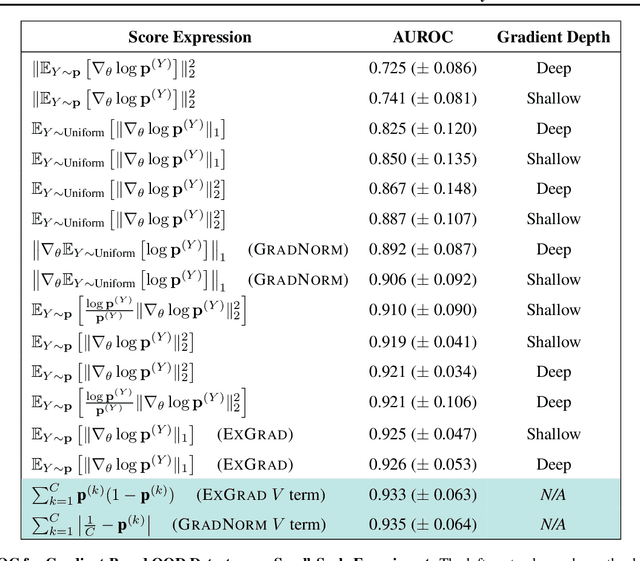
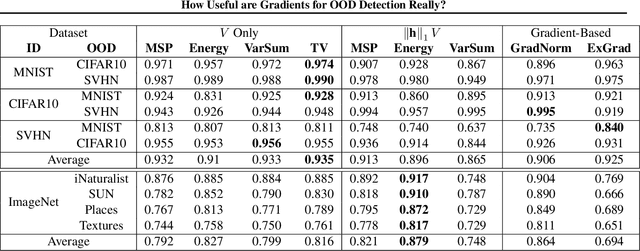
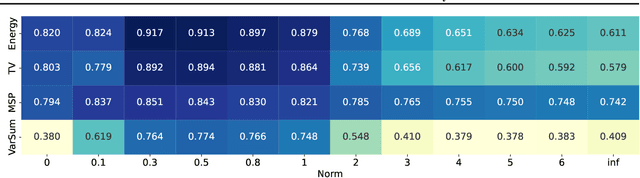
One critical challenge in deploying highly performant machine learning models in real-life applications is out of distribution (OOD) detection. Given a predictive model which is accurate on in distribution (ID) data, an OOD detection system will further equip the model with the option to defer prediction when the input is novel and the model has little confidence in prediction. There has been some recent interest in utilizing the gradient information in pre-trained models for OOD detection. While these methods have shown competitive performance, there are misconceptions about the true mechanism underlying them, which conflate their performance with the necessity of gradients. In this work, we provide an in-depth analysis and comparison of gradient based methods and elucidate the key components that warrant their OOD detection performance. We further propose a general, non-gradient based method of OOD detection which improves over previous baselines in both performance and computational efficiency.
Uncertainty Toolbox: an Open-Source Library for Assessing, Visualizing, and Improving Uncertainty Quantification
Sep 21, 2021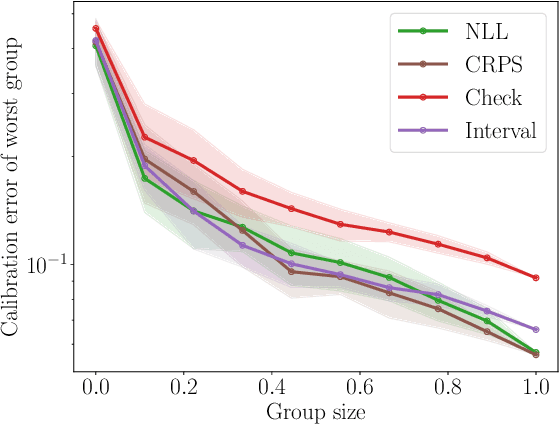
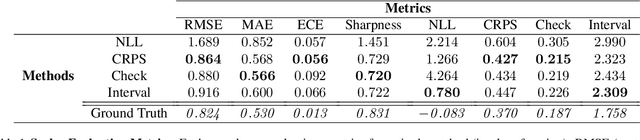
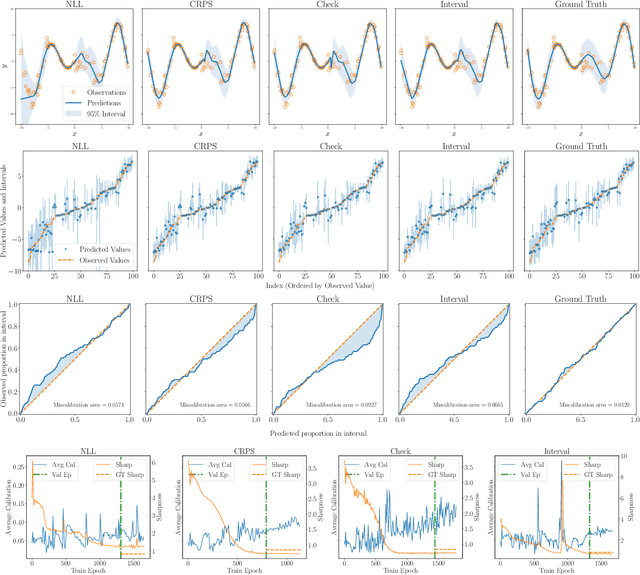
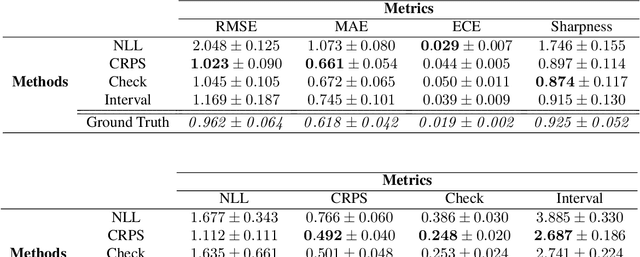
With increasing deployment of machine learning systems in various real-world tasks, there is a greater need for accurate quantification of predictive uncertainty. While the common goal in uncertainty quantification (UQ) in machine learning is to approximate the true distribution of the target data, many works in UQ tend to be disjoint in the evaluation metrics utilized, and disparate implementations for each metric lead to numerical results that are not directly comparable across different works. To address this, we introduce Uncertainty Toolbox, an open-source python library that helps to assess, visualize, and improve UQ. Uncertainty Toolbox additionally provides pedagogical resources, such as a glossary of key terms and an organized collection of key paper references. We hope that this toolbox is useful for accelerating and uniting research efforts in uncertainty in machine learning.