 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving Embodied Foundation Models
Sep 18, 2025Foundation models trained on web-scale data have revolutionized robotics, but their application to low-level control remains largely limited to behavioral cloning. Drawing inspiration from the success of the reinforcement learning stage in fine-tuning large language models, we propose a two-stage post-training approach for robotics. The first stage, Supervised Fine-Tuning (SFT), fine-tunes pretrained foundation models using both: a) behavioral cloning, and b) steps-to-go prediction objectives. In the second stage, Self-Improvement, steps-to-go prediction enables the extraction of a well-shaped reward function and a robust success detector, enabling a fleet of robots to autonomously practice downstream tasks with minimal human supervision. Through extensive experiments on real-world and simulated robot embodiments, our novel post-training recipe unveils significant results on Embodied Foundation Models. First, we demonstrate that the combination of SFT and Self-Improvement is significantly more sample-efficient than scaling imitation data collection for supervised learning, and that it leads to policies with significantly higher success rates. Further ablations highlight that the combination of web-scale pretraining and Self-Improvement is the key to this sample-efficiency. Next, we demonstrate that our proposed combination uniquely unlocks a capability that current methods cannot achieve: autonomously practicing and acquiring novel skills that generalize far beyond the behaviors observed in the imitation learning datasets used during training. These findings highlight the transformative potential of combining pretrained foundation models with online Self-Improvement to enable autonomous skill acquisition in robotics. Our project website can be found at https://self-improving-efms.github.io .
Bi-Manual Block Assembly via Sim-to-Real Reinforcement Learning
Mar 27, 2023



Most successes in robotic manipulation have been restricted to single-arm gripper robots, whose low dexterity limits the range of solvable tasks to pick-and-place, inser-tion, and object rearrangement. More complex tasks such as assembly require dual and multi-arm platforms, but entail a suite of unique challenges such as bi-arm coordination and collision avoidance, robust grasping, and long-horizon planning. In this work we investigate the feasibility of training deep reinforcement learning (RL) policies in simulation and transferring them to the real world (Sim2Real) as a generic methodology for obtaining performant controllers for real-world bi-manual robotic manipulation tasks. As a testbed for bi-manual manipulation, we develop the U-Shape Magnetic BlockAssembly Task, wherein two robots with parallel grippers must connect 3 magnetic blocks to form a U-shape. Without manually-designed controller nor human demonstrations, we demonstrate that with careful Sim2Real considerations, our policies trained with RL in simulation enable two xArm6 robots to solve the U-shape assembly task with a success rate of above90% in simulation, and 50% on real hardware without any additional real-world fine-tuning. Through careful ablations,we highlight how each component of the system is critical for such simple and successful policy learning and transfer,including task specification, learning algorithm, direct joint-space control, behavior constraints, perception and actuation noises, action delays and action interpolation. Our results present a significant step forward for bi-arm capability on real hardware, and we hope our system can inspire future research on deep RL and Sim2Real transfer of bi-manualpolicies, drastically scaling up the capability of real-world robot manipulators.
Why So Pessimistic? Estimating Uncertainties for Offline RL through Ensembles, and Why Their Independence Matters
May 27, 2022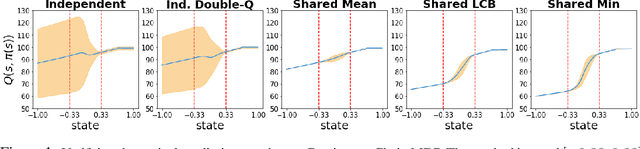
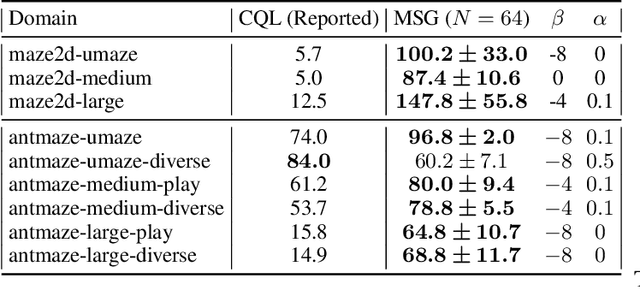


Motivated by the success of ensembles for uncertainty estimation in supervised learning, we take a renewed look at how ensembles of $Q$-functions can be leveraged as the primary source of pessimism for offline reinforcement learning (RL). We begin by identifying a critical flaw in a popular algorithmic choice used by many ensemble-based RL algorithms, namely the use of shared pessimistic target values when computing each ensemble member's Bellman error. Through theoretical analyses and construction of examples in toy MDPs, we demonstrate that shared pessimistic targets can paradoxically lead to value estimates that are effectively optimistic. Given this result, we propose MSG, a practical offline RL algorithm that trains an ensemble of $Q$-functions with independently computed targets based on completely separate networks, and optimizes a policy with respect to the lower confidence bound of predicted action values. Our experiments on the popular D4RL and RL Unplugged offline RL benchmarks demonstrate that on challenging domains such as antmazes, MSG with deep ensembles surpasses highly well-tuned state-of-the-art methods by a wide margin. Additionally, through ablations on benchmarks domains, we verify the critical significance of using independently trained $Q$-functions, and study the role of ensemble size. Finally, as using separate networks per ensemble member can become computationally costly with larger neural network architectures, we investigate whether efficient ensemble approximations developed for supervised learning can be similarly effective, and demonstrate that they do not match the performance and robustness of MSG with separate networks, highlighting the need for new efforts into efficient uncertainty estimation directed at RL.
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
May 23, 2022

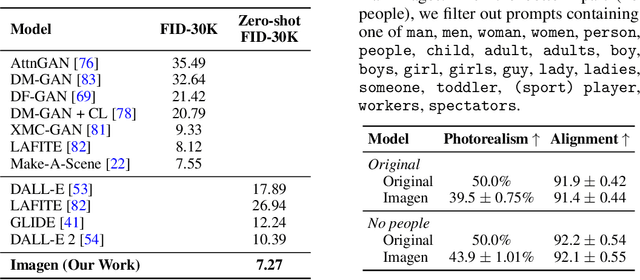
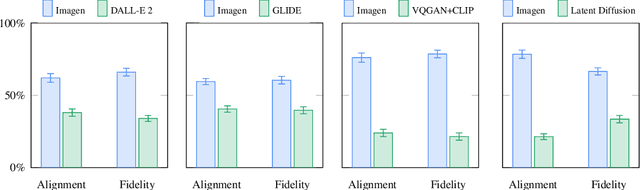
We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment. To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment. See https://imagen.research.google/ for an overview of the results.
Blocks Assemble! Learning to Assemble with Large-Scale Structured Reinforcement Learning
Apr 12, 2022

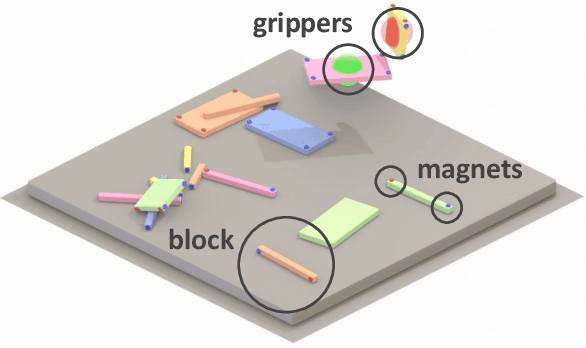

Assembly of multi-part physical structures is both a valuable end product for autonomous robotics, as well as a valuable diagnostic task for open-ended training of embodied intelligent agents. We introduce a naturalistic physics-based environment with a set of connectable magnet blocks inspired by children's toy kits. The objective is to assemble blocks into a succession of target blueprints. Despite the simplicity of this objective, the compositional nature of building diverse blueprints from a set of blocks leads to an explosion of complexity in structures that agents encounter. Furthermore, assembly stresses agents' multi-step planning, physical reasoning, and bimanual coordination. We find that the combination of large-scale reinforcement learning and graph-based policies -- surprisingly without any additional complexity -- is an effective recipe for training agents that not only generalize to complex unseen blueprints in a zero-shot manner, but even operate in a reset-free setting without being trained to do so. Through extensive experiments, we highlight the importance of large-scale training, structured representations, contributions of multi-task vs. single-task learning, as well as the effects of curriculums, and discuss qualitative behaviors of trained agents.
Bi-Manual Manipulation and Attachment via Sim-to-Real Reinforcement Learning
Mar 15, 2022
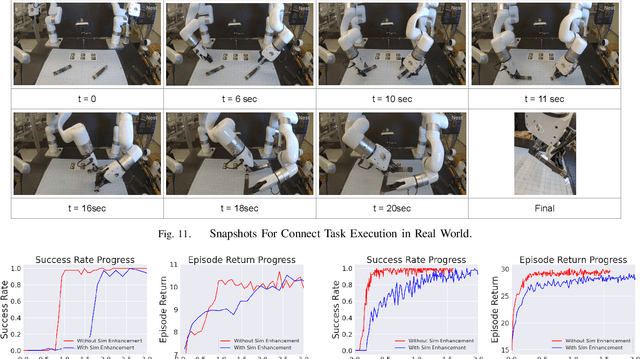
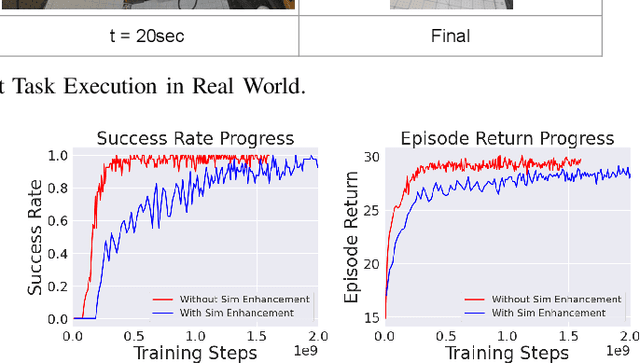
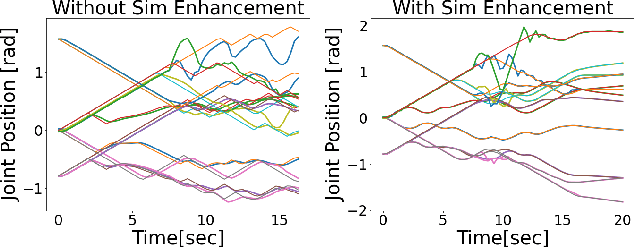
Most successes in robotic manipulation have been restricted to single-arm robots, which limits the range of solvable tasks to pick-and-place, insertion, and objects rearrangement. In contrast, dual and multi arm robot platforms unlock a rich diversity of problems that can be tackled, such as laundry folding and executing cooking skills. However, developing controllers for multi-arm robots is complexified by a number of unique challenges, such as the need for coordinated bimanual behaviors, and collision avoidance amongst robots. Given these challenges, in this work we study how to solve bi-manual tasks using reinforcement learning (RL) trained in simulation, such that the resulting policies can be executed on real robotic platforms. Our RL approach results in significant simplifications due to using real-time (4Hz) joint-space control and directly passing unfiltered observations to neural networks policies. We also extensively discuss modifications to our simulated environment which lead to effective training of RL policies. In addition to designing control algorithms, a key challenge is how to design fair evaluation tasks for bi-manual robots that stress bimanual coordination, while removing orthogonal complicating factors such as high-level perception. In this work, we design a Connect Task, where the aim is for two robot arms to pick up and attach two blocks with magnetic connection points. We validate our approach with two xArm6 robots and 3D printed blocks with magnetic attachments, and find that our system has 100% success rate at picking up blocks, and 65% success rate at the Connect Task.
Braxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineering beyond Reward Maximization
Oct 10, 2021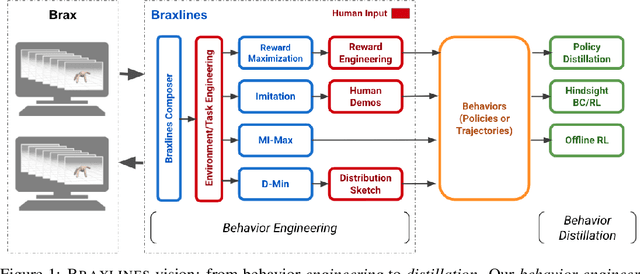



The goal of continuous control is to synthesize desired behaviors. In reinforcement learning (RL)-driven approaches, this is often accomplished through careful task reward engineering for efficient exploration and running an off-the-shelf RL algorithm. While reward maximization is at the core of RL, reward engineering is not the only -- sometimes nor the easiest -- way for specifying complex behaviors. In this paper, we introduce \braxlines, a toolkit for fast and interactive RL-driven behavior generation beyond simple reward maximization that includes Composer, a programmatic API for generating continuous control environments, and set of stable and well-tested baselines for two families of algorithms -- mutual information maximization (MiMax) and divergence minimization (DMin) -- supporting unsupervised skill learning and distribution sketching as other modes of behavior specification. In addition, we discuss how to standardize metrics for evaluating these algorithms, which can no longer rely on simple reward maximization. Our implementations build on a hardware-accelerated Brax simulator in Jax with minimal modifications, enabling behavior synthesis within minutes of training. We hope Braxlines can serve as an interactive toolkit for rapid creation and testing of environments and behaviors, empowering explosions of future benchmark designs and new modes of RL-driven behavior generation and their algorithmic research.
EMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL
Jul 21, 2020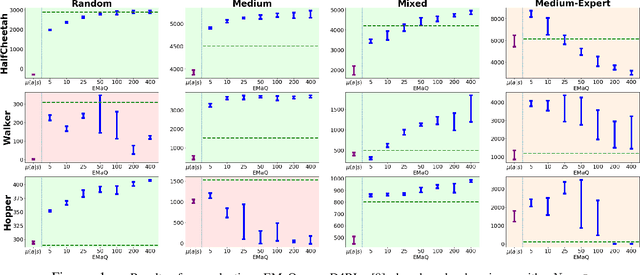
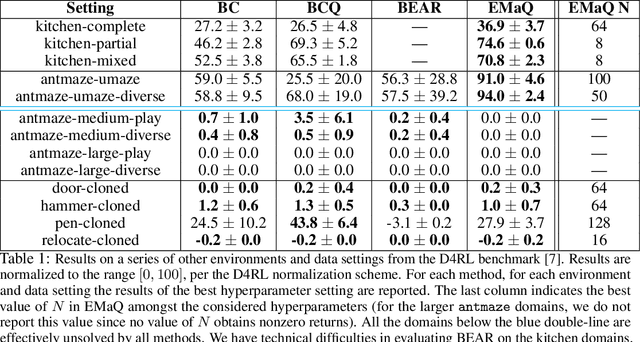
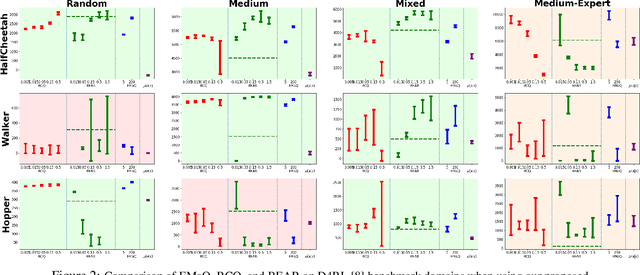
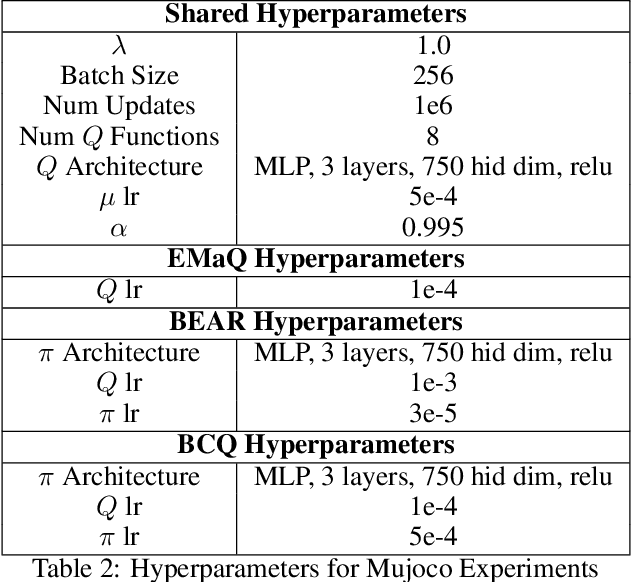
Off-policy reinforcement learning (RL) holds the promise of sample-efficient learning of decision-making policies by leveraging past experience. However, in the offline RL setting -- where a fixed collection of interactions are provided and no further interactions are allowed -- it has been shown that standard off-policy RL methods can significantly underperform. Recently proposed methods aim to address this shortcoming by regularizing learned policies to remain close to the given dataset of interactions. However, these methods involve several configurable components such as learning a separate policy network on top of a behavior cloning actor, and explicitly constraining action spaces through clipping or reward penalties. Striving for simultaneous simplicity and performance, in this work we present a novel backup operator, Expected-Max Q-Learning (EMaQ), which naturally restricts learned policies to remain within the support of the offline dataset \emph{without any explicit regularization}, while retaining desirable theoretical properties such as contraction. We demonstrate that EMaQ is competitive with Soft Actor Critic (SAC) in online RL, and surpasses SAC in the deployment-efficient setting. In the offline RL setting -- the main focus of this work -- through EMaQ we are able to make important observations regarding key components of offline RL, and the nature of standard benchmark tasks. Lastly but importantly, we observe that EMaQ achieves state-of-the-art performance with fewer moving parts such as one less function approximation, making it a strong, yet easy to implement baseline for future work.
A Divergence Minimization Perspective on Imitation Learning Methods
Nov 06, 2019
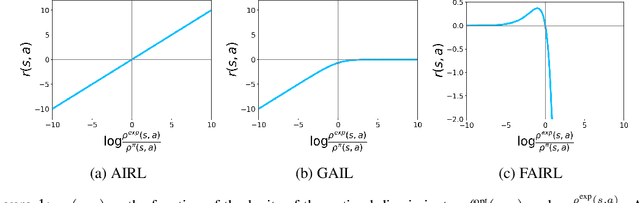
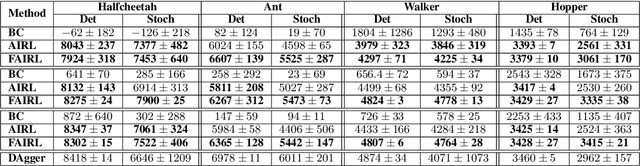
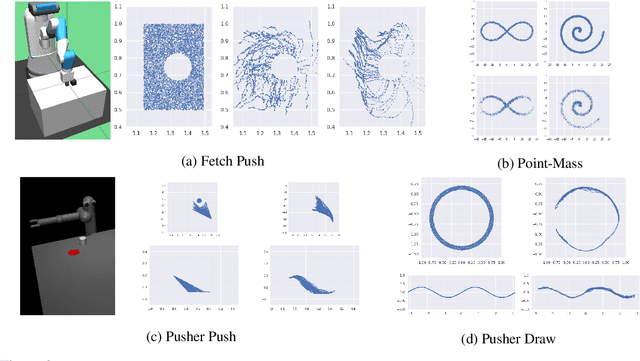
In many settings, it is desirable to learn decision-making and control policies through learning or bootstrapping from expert demonstrations. The most common approaches under this Imitation Learning (IL) framework are Behavioural Cloning (BC), and Inverse Reinforcement Learning (IRL). Recent methods for IRL have demonstrated the capacity to learn effective policies with access to a very limited set of demonstrations, a scenario in which BC methods often fail. Unfortunately, due to multiple factors of variation, directly comparing these methods does not provide adequate intuition for understanding this difference in performance. In this work, we present a unified probabilistic perspective on IL algorithms based on divergence minimization. We present $f$-MAX, an $f$-divergence generalization of AIRL [Fu et al., 2018], a state-of-the-art IRL method. $f$-MAX enables us to relate prior IRL methods such as GAIL [Ho & Ermon, 2016] and AIRL [Fu et al., 2018], and understand their algorithmic properties. Through the lens of divergence minimization we tease apart the differences between BC and successful IRL approaches, and empirically evaluate these nuances on simulated high-dimensional continuous control domains. Our findings conclusively identify that IRL's state-marginal matching objective contributes most to its superior performance. Lastly, we apply our new understanding of IL methods to the problem of state-marginal matching, where we demonstrate that in simulated arm pushing environments we can teach agents a diverse range of behaviours using simply hand-specified state distributions and no reward functions or expert demonstrations. For datasets and reproducing results please refer to https://github.com/KamyarGh/rl_swiss/blob/master/reproducing/fmax_paper.md .