 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompliantVLA-adaptor: VLM-Guided Variable Impedance Action for Safe Contact-Rich Manipulation
Jan 21, 2026We propose a CompliantVLA-adaptor that augments the state-of-the-art Vision-Language-Action (VLA) models with vision-language model (VLM)-informed context-aware variable impedance control (VIC) to improve the safety and effectiveness of contact-rich robotic manipulation tasks. Existing VLA systems (e.g., RDT, Pi0, OpenVLA-oft) typically output position, but lack force-aware adaptation, leading to unsafe or failed interactions in physical tasks involving contact, compliance, or uncertainty. In the proposed CompliantVLA-adaptor, a VLM interprets task context from images and natural language to adapt the stiffness and damping parameters of a VIC controller. These parameters are further regulated using real-time force/torque feedback to ensure interaction forces remain within safe thresholds. We demonstrate that our method outperforms the VLA baselines on a suite of complex contact-rich tasks, both in simulation and on real hardware, with improved success rates and reduced force violations. The overall success rate across all tasks increases from 9.86\% to 17.29\%, presenting a promising path towards safe contact-rich manipulation using VLAs. We release our code, prompts, and force-torque-impedance-scenario context datasets at https://sites.google.com/view/compliantvla.
Generalizable Geometric Prior and Recurrent Spiking Feature Learning for Humanoid Robot Manipulation
Jan 13, 2026Humanoid robot manipulation is a crucial research area for executing diverse human-level tasks, involving high-level semantic reasoning and low-level action generation. However, precise scene understanding and sample-efficient learning from human demonstrations remain critical challenges, severely hindering the applicability and generalizability of existing frameworks. This paper presents a novel RGMP-S, Recurrent Geometric-prior Multimodal Policy with Spiking features, facilitating both high-level skill reasoning and data-efficient motion synthesis. To ground high-level reasoning in physical reality, we leverage lightweight 2D geometric inductive biases to enable precise 3D scene understanding within the vision-language model. Specifically, we construct a Long-horizon Geometric Prior Skill Selector that effectively aligns the semantic instructions with spatial constraints, ultimately achieving robust generalization in unseen environments. For the data efficiency issue in robotic action generation, we introduce a Recursive Adaptive Spiking Network. We parameterize robot-object interactions via recursive spiking for spatiotemporal consistency, fully distilling long-horizon dynamic features while mitigating the overfitting issue in sparse demonstration scenarios. Extensive experiments are conducted across the Maniskill simulation benchmark and three heterogeneous real-world robotic systems, encompassing a custom-developed humanoid, a desktop manipulator, and a commercial robotic platform. Empirical results substantiate the superiority of our method over state-of-the-art baselines and validate the efficacy of the proposed modules in diverse generalization scenarios. To facilitate reproducibility, the source code and video demonstrations are publicly available at https://github.com/xtli12/RGMP-S.git.
InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression
Dec 18, 2025Accurate and efficient discrete video tokenization is essential for long video sequences processing. Yet, the inherent complexity and variable information density of videos present a significant bottleneck for current tokenizers, which rigidly compress all content at a fixed rate, leading to redundancy or information loss. Drawing inspiration from Shannon's information theory, this paper introduces InfoTok, a principled framework for adaptive video tokenization. We rigorously prove that existing data-agnostic training methods are suboptimal in representation length, and present a novel evidence lower bound (ELBO)-based algorithm that approaches theoretical optimality. Leveraging this framework, we develop a transformer-based adaptive compressor that enables adaptive tokenization. Empirical results demonstrate state-of-the-art compression performance, saving 20% tokens without influence on performance, and achieving 2.3x compression rates while still outperforming prior heuristic adaptive approaches. By allocating tokens according to informational richness, InfoTok enables a more compressed yet accurate tokenization for video representation, offering valuable insights for future research.
Reasoning Within the Mind: Dynamic Multimodal Interleaving in Latent Space
Dec 17, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced cross-modal understanding and reasoning by incorporating Chain-of-Thought (CoT) reasoning in the semantic space. Building upon this, recent studies extend the CoT mechanism to the visual modality, enabling models to integrate visual information during reasoning through external tools or explicit image generation. However, these methods remain dependent on explicit step-by-step reasoning, unstable perception-reasoning interaction and notable computational overhead. Inspired by human cognition, we posit that thinking unfolds not linearly but through the dynamic interleaving of reasoning and perception within the mind. Motivated by this perspective, we propose DMLR, a test-time Dynamic Multimodal Latent Reasoning framework that employs confidence-guided latent policy gradient optimization to refine latent think tokens for in-depth reasoning. Furthermore, a Dynamic Visual Injection Strategy is introduced, which retrieves the most relevant visual features at each latent think token and updates the set of best visual patches. The updated patches are then injected into latent think token to achieve dynamic visual-textual interleaving. Experiments across seven multimodal reasoning benchmarks and various model architectures demonstrate that DMLR significantly improves reasoning and perception performance while maintaining high inference efficiency.
Uni-Inter: Unifying 3D Human Motion Synthesis Across Diverse Interaction Contexts
Nov 17, 2025We present Uni-Inter, a unified framework for human motion generation that supports a wide range of interaction scenarios: including human-human, human-object, and human-scene-within a single, task-agnostic architecture. In contrast to existing methods that rely on task-specific designs and exhibit limited generalization, Uni-Inter introduces the Unified Interactive Volume (UIV), a volumetric representation that encodes heterogeneous interactive entities into a shared spatial field. This enables consistent relational reasoning and compound interaction modeling. Motion generation is formulated as joint-wise probabilistic prediction over the UIV, allowing the model to capture fine-grained spatial dependencies and produce coherent, context-aware behaviors. Experiments across three representative interaction tasks demonstrate that Uni-Inter achieves competitive performance and generalizes well to novel combinations of entities. These results suggest that unified modeling of compound interactions offers a promising direction for scalable motion synthesis in complex environments.
Free3D: 3D Human Motion Emerges from Single-View 2D Supervision
Nov 14, 2025Recent 3D human motion generation models demonstrate remarkable reconstruction accuracy yet struggle to generalize beyond training distributions. This limitation arises partly from the use of precise 3D supervision, which encourages models to fit fixed coordinate patterns instead of learning the essential 3D structure and motion semantic cues required for robust generalization.To overcome this limitation, we propose Free3D, a framework that synthesizes realistic 3D motions without any 3D motion annotations. Free3D introduces a Motion-Lifting Residual Quantized VAE (ML-RQ) that maps 2D motion sequences into 3D-consistent latent spaces, and a suite of 3D-free regularization objectives enforcing view consistency, orientation coherence, and physical plausibility. Trained entirely on 2D motion data, Free3D generates diverse, temporally coherent, and semantically aligned 3D motions, achieving performance comparable to or even surpassing fully 3D-supervised counterparts. These results suggest that relaxing explicit 3D supervision encourages stronger structural reasoning and generalization, offering a scalable and data-efficient paradigm for 3D motion generation.
Forewarned is Forearmed: Pre-Synthesizing Jailbreak-like Instructions to Enhance LLM Safety Guardrail to Potential Attacks
Aug 28, 2025Despite advances in improving large language model (LLM) to refuse to answer malicious instructions, widely used LLMs remain vulnerable to jailbreak attacks where attackers generate instructions with distributions differing from safety alignment corpora. New attacks expose LLMs' inability to recognize unseen malicious instructions, highlighting a critical distributional mismatch between training data and real-world attacks that forces developers into reactive patching cycles. To tackle this challenge, we propose IMAGINE, a synthesis framework that leverages embedding space distribution analysis to generate jailbreak-like instructions. This approach effectively fills the distributional gap between authentic jailbreak patterns and safety alignment corpora. IMAGINE follows an iterative optimization process that dynamically evolves text generation distributions across iterations, thereby augmenting the coverage of safety alignment data distributions through synthesized data examples. Based on the safety-aligned corpus enhanced through IMAGINE, our framework demonstrates significant decreases in attack success rate on Qwen2.5, Llama3.1, and Llama3.2 without compromising their utility.
Prototype-Based Information Compensation Network for Multi-Source Remote Sensing Data Classification
May 06, 2025Multi-source remote sensing data joint classification aims to provide accuracy and reliability of land cover classification by leveraging the complementary information from multiple data sources. Existing methods confront two challenges: inter-frequency multi-source feature coupling and inconsistency of complementary information exploration. To solve these issues, we present a Prototype-based Information Compensation Network (PICNet) for land cover classification based on HSI and SAR/LiDAR data. Specifically, we first design a frequency interaction module to enhance the inter-frequency coupling in multi-source feature extraction. The multi-source features are first decoupled into high- and low-frequency components. Then, these features are recoupled to achieve efficient inter-frequency communication. Afterward, we design a prototype-based information compensation module to model the global multi-source complementary information. Two sets of learnable modality prototypes are introduced to represent the global modality information of multi-source data. Subsequently, cross-modal feature integration and alignment are achieved through cross-attention computation between the modality-specific prototype vectors and the raw feature representations. Extensive experiments on three public datasets demonstrate the significant superiority of our PICNet over state-of-the-art methods. The codes are available at https://github.com/oucailab/PICNet.
Diffusion Models for Robotic Manipulation: A Survey
Apr 11, 2025Diffusion generative models have demonstrated remarkable success in visual domains such as image and video generation. They have also recently emerged as a promising approach in robotics, especially in robot manipulations. Diffusion models leverage a probabilistic framework, and they stand out with their ability to model multi-modal distributions and their robustness to high-dimensional input and output spaces. This survey provides a comprehensive review of state-of-the-art diffusion models in robotic manipulation, including grasp learning, trajectory planning, and data augmentation. Diffusion models for scene and image augmentation lie at the intersection of robotics and computer vision for vision-based tasks to enhance generalizability and data scarcity. This paper also presents the two main frameworks of diffusion models and their integration with imitation learning and reinforcement learning. In addition, it discusses the common architectures and benchmarks and points out the challenges and advantages of current state-of-the-art diffusion-based methods.
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Apr 01, 2025

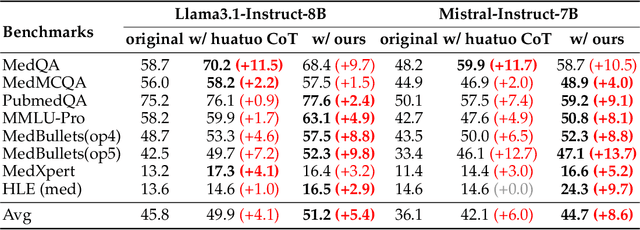
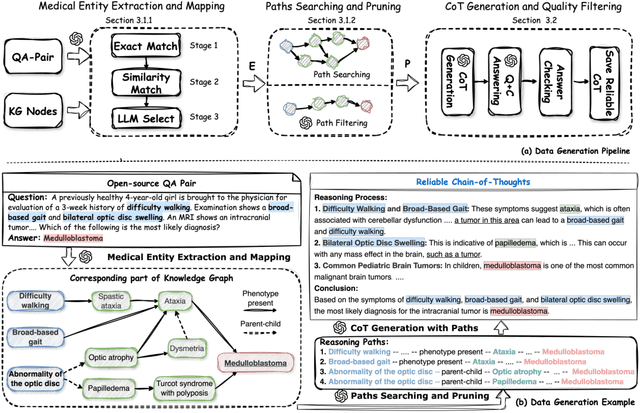
Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths'', which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset's quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.