 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompliantVLA-adaptor: VLM-Guided Variable Impedance Action for Safe Contact-Rich Manipulation
Jan 21, 2026We propose a CompliantVLA-adaptor that augments the state-of-the-art Vision-Language-Action (VLA) models with vision-language model (VLM)-informed context-aware variable impedance control (VIC) to improve the safety and effectiveness of contact-rich robotic manipulation tasks. Existing VLA systems (e.g., RDT, Pi0, OpenVLA-oft) typically output position, but lack force-aware adaptation, leading to unsafe or failed interactions in physical tasks involving contact, compliance, or uncertainty. In the proposed CompliantVLA-adaptor, a VLM interprets task context from images and natural language to adapt the stiffness and damping parameters of a VIC controller. These parameters are further regulated using real-time force/torque feedback to ensure interaction forces remain within safe thresholds. We demonstrate that our method outperforms the VLA baselines on a suite of complex contact-rich tasks, both in simulation and on real hardware, with improved success rates and reduced force violations. The overall success rate across all tasks increases from 9.86\% to 17.29\%, presenting a promising path towards safe contact-rich manipulation using VLAs. We release our code, prompts, and force-torque-impedance-scenario context datasets at https://sites.google.com/view/compliantvla.
MMDrive: Interactive Scene Understanding Beyond Vision with Multi-representational Fusion
Dec 16, 2025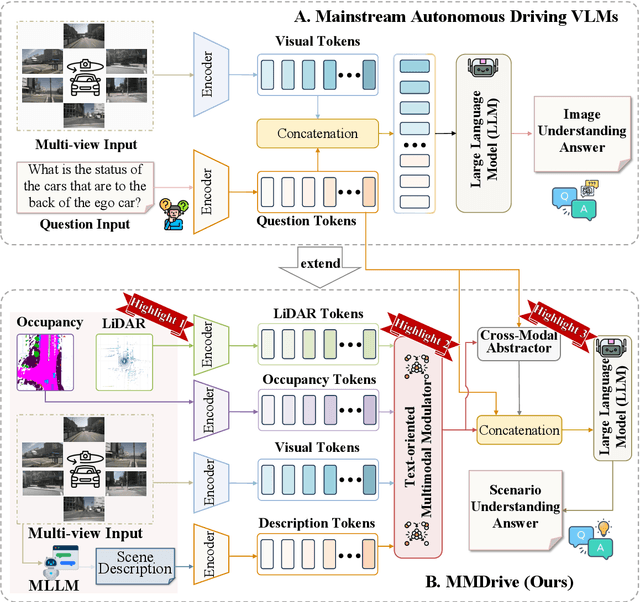
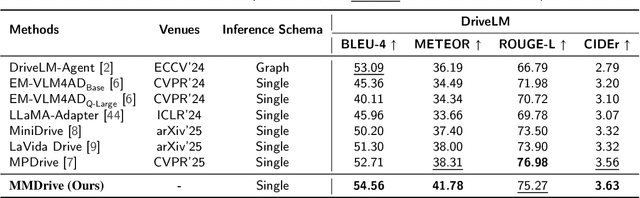


Vision-language models enable the understanding and reasoning of complex traffic scenarios through multi-source information fusion, establishing it as a core technology for autonomous driving. However, existing vision-language models are constrained by the image understanding paradigm in 2D plane, which restricts their capability to perceive 3D spatial information and perform deep semantic fusion, resulting in suboptimal performance in complex autonomous driving environments. This study proposes MMDrive, an multimodal vision-language model framework that extends traditional image understanding to a generalized 3D scene understanding framework. MMDrive incorporates three complementary modalities, including occupancy maps, LiDAR point clouds, and textual scene descriptions. To this end, it introduces two novel components for adaptive cross-modal fusion and key information extraction. Specifically, the Text-oriented Multimodal Modulator dynamically weights the contributions of each modality based on the semantic cues in the question, guiding context-aware feature integration. The Cross-Modal Abstractor employs learnable abstract tokens to generate compact, cross-modal summaries that highlight key regions and essential semantics. Comprehensive evaluations on the DriveLM and NuScenes-QA benchmarks demonstrate that MMDrive achieves significant performance gains over existing vision-language models for autonomous driving, with a BLEU-4 score of 54.56 and METEOR of 41.78 on DriveLM, and an accuracy score of 62.7% on NuScenes-QA. MMDrive effectively breaks the traditional image-only understanding barrier, enabling robust multimodal reasoning in complex driving environments and providing a new foundation for interpretable autonomous driving scene understanding.
NeuroSim V1.5: Improved Software Backbone for Benchmarking Compute-in-Memory Accelerators with Device and Circuit-level Non-idealities
May 05, 2025



The exponential growth of artificial intelligence (AI) applications has exposed the inefficiency of conventional von Neumann architectures, where frequent data transfers between compute units and memory create significant energy and latency bottlenecks. Analog Computing-in-Memory (ACIM) addresses this challenge by performing multiply-accumulate (MAC) operations directly in the memory arrays, substantially reducing data movement. However, designing robust ACIM accelerators requires accurate modeling of device- and circuit-level non-idealities. In this work, we present NeuroSim V1.5, introducing several key advances: (1) seamless integration with TensorRT's post-training quantization flow enabling support for more neural networks including transformers, (2) a flexible noise injection methodology built on pre-characterized statistical models, making it straightforward to incorporate data from SPICE simulations or silicon measurements, (3) expanded device support including emerging non-volatile capacitive memories, and (4) up to 6.5x faster runtime than NeuroSim V1.4 through optimized behavioral simulation. The combination of these capabilities uniquely enables systematic design space exploration across both accuracy and hardware efficiency metrics. Through multiple case studies, we demonstrate optimization of critical design parameters while maintaining network accuracy. By bridging high-fidelity noise modeling with efficient simulation, NeuroSim V1.5 advances the design and validation of next-generation ACIM accelerators. All NeuroSim versions are available open-source at https://github.com/neurosim/NeuroSim.