 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAWS: Preference Learning with Advantage-Weighted Segments
Jun 10, 2026Preference-based reinforcement learning (PbRL) learns policies from human trajectory-level comparisons, avoiding explicit reward design and expert demonstrations. Existing methods typically train utility functions on trajectory or segment-level preferences while relying on per-step utility estimates during policy optimization. This training and inference mismatch induces a distribution shift that severely degrades temporal credit assignment and limits policy learning. We analyze this issue and propose PAWS, a segment-based preference learning method that performs policy updates directly using segment-level advantage functions. By aligning utility training with policy optimization, PAWS preserves trajectory-level preference information and avoids unreliable per-step learning signals. Experiments on simulated robotic manipulation and locomotion tasks demonstrate that PAWS consistently outperforms existing PbRL approaches, highlighting the importance of distribution-consistent preference learning.
Hand-centric Human-to-Robot Trajectory Transfer from Video Demonstrations via Open-World Contact Localization
Jun 09, 2026Learning from human video demonstrations remains challenging due to noisy hand-object interactions, unseen objects with partial observation, and cross-embodiment discrepancy. To address these challenges, we present \textit{HOWTransfer} (\emph{H}and-\emph{O}bject \emph{O}pen-\emph{W}orld Transfer), a hand-centric framework that distills human demonstrations into contact-aware, taxonomy-informed, and diverse robotic trajectories. Instead of relying on object-specific descriptions, vision-language queries, or explicit object-state tracking, \emph{HOWTransfer} recovers temporally consistent 3D hand motion and localizes temporal contact intervals by reasoning over observed hand-object interaction cues. The localized contact onsets are then used to retarget human grasp intent into multi-modal parallel-jaw grasp hypotheses, which are propagated along the recovered wrist trajectory to generate robot-executable motions. Finally, a trajectory editing stage refines contact alignment and produces diverse executable variants from a single demonstration. Experiments across diverse manipulation tasks show that \emph{HOWTransfer} enables accurate contact localization and high-quality robot motion retargeting with $86\%$ success, which is preferred over teleoperated trajectories in a blinded preference study.
Tracing Back Error Sources to Explain and Mitigate Pose Estimation Failures
Mar 03, 2026Robust estimation of object poses in robotic manipulation is often addressed using foundational general estimators, that aim to handle diverse error sources naively within a single model. Still, they struggle due to environmental uncertainties, while requiring long inference times and heavy computation. In contrast, we propose a modular, uncertainty-aware framework that attributes pose estimation errors to specific error sources and applies targeted mitigation strategies only when necessary. Instantiated with Iterative Closest Point (ICP) as a simple and lightweight pose estimator, we leverage our framework for real-world robotic grasping tasks. By decomposing pose estimation into failure detection, error attribution, and targeted recovery, we significantly improve the robustness of ICP and achieve competitive performance compared to foundation models, while relying on a substantially simpler and faster pose estimator.
FlowCorrect: Efficient Interactive Correction of Generative Flow Policies for Robotic Manipulation
Feb 25, 2026Generative manipulation policies can fail catastrophically under deployment-time distribution shift, yet many failures are near-misses: the robot reaches almost-correct poses and would succeed with a small corrective motion. We present FlowCorrect, a deployment-time correction framework that converts near-miss failures into successes using sparse human nudges, without full policy retraining. During execution, a human provides brief corrective pose nudges via a lightweight VR interface. FlowCorrect uses these sparse corrections to locally adapt the policy, improving actions without retraining the backbone while preserving the model performance on previously learned scenarios. We evaluate on a real-world robot across three tabletop tasks: pick-and-place, pouring, and cup uprighting. With a low correction budget, FlowCorrect improves success on hard cases by 85\% while preserving performance on previously solved scenarios. The results demonstrate clearly that FlowCorrect learns only with very few demonstrations and enables fast and sample-efficient incremental, human-in-the-loop corrections of generative visuomotor policies at deployment time in real-world robotics.
Diffusion Models for Robotic Manipulation: A Survey
Apr 11, 2025Diffusion generative models have demonstrated remarkable success in visual domains such as image and video generation. They have also recently emerged as a promising approach in robotics, especially in robot manipulations. Diffusion models leverage a probabilistic framework, and they stand out with their ability to model multi-modal distributions and their robustness to high-dimensional input and output spaces. This survey provides a comprehensive review of state-of-the-art diffusion models in robotic manipulation, including grasp learning, trajectory planning, and data augmentation. Diffusion models for scene and image augmentation lie at the intersection of robotics and computer vision for vision-based tasks to enhance generalizability and data scarcity. This paper also presents the two main frameworks of diffusion models and their integration with imitation learning and reinforcement learning. In addition, it discusses the common architectures and benchmarks and points out the challenges and advantages of current state-of-the-art diffusion-based methods.
VISO-Grasp: Vision-Language Informed Spatial Object-centric 6-DoF Active View Planning and Grasping in Clutter and Invisibility
Mar 16, 2025We propose VISO-Grasp, a novel vision-language-informed system designed to systematically address visibility constraints for grasping in severely occluded environments. By leveraging Foundation Models (FMs) for spatial reasoning and active view planning, our framework constructs and updates an instance-centric representation of spatial relationships, enhancing grasp success under challenging occlusions. Furthermore, this representation facilitates active Next-Best-View (NBV) planning and optimizes sequential grasping strategies when direct grasping is infeasible. Additionally, we introduce a multi-view uncertainty-driven grasp fusion mechanism that refines grasp confidence and directional uncertainty in real-time, ensuring robust and stable grasp execution. Extensive real-world experiments demonstrate that VISO-Grasp achieves a success rate of $87.5\%$ in target-oriented grasping with the fewest grasp attempts outperforming baselines. To the best of our knowledge, VISO-Grasp is the first unified framework integrating FMs into target-aware active view planning and 6-DoF grasping in environments with severe occlusions and entire invisibility constraints.
AI-based Framework for Robust Model-Based Connector Mating in Robotic Wire Harness Installation
Mar 12, 2025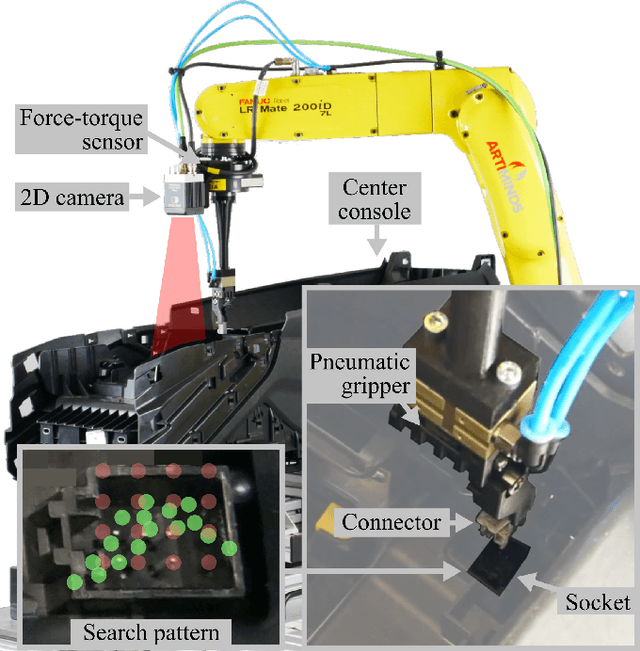
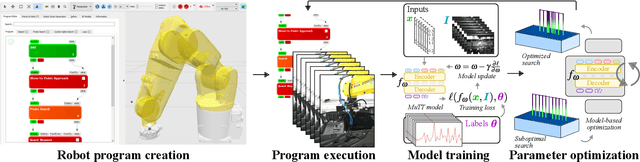
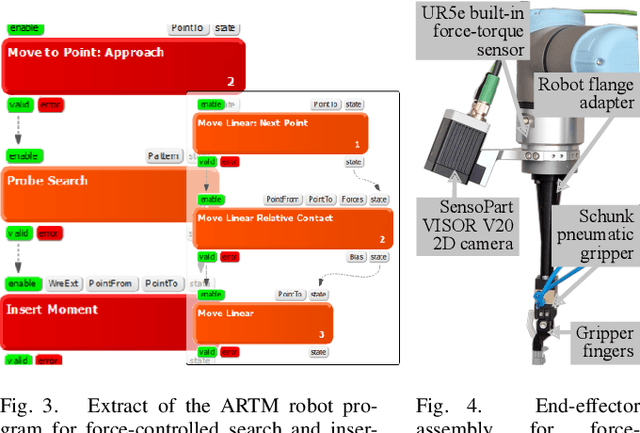
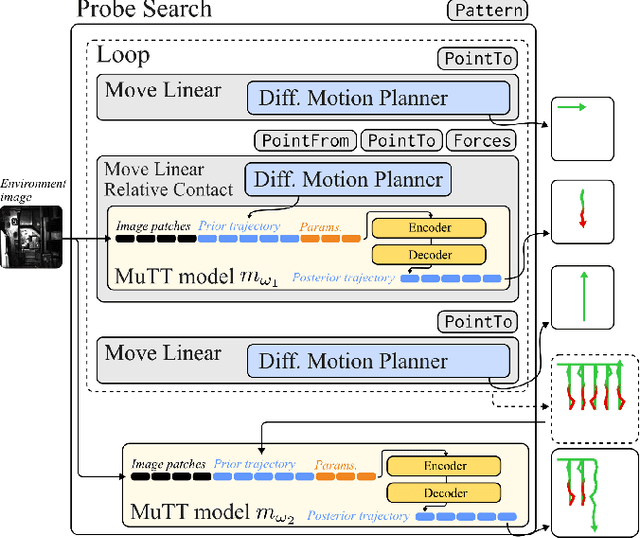
Despite the widespread adoption of industrial robots in automotive assembly, wire harness installation remains a largely manual process, as it requires precise and flexible manipulation. To address this challenge, we design a novel AI-based framework that automates cable connector mating by integrating force control with deep visuotactile learning. Our system optimizes search-and-insertion strategies using first-order optimization over a multimodal transformer architecture trained on visual, tactile, and proprioceptive data. Additionally, we design a novel automated data collection and optimization pipeline that minimizes the need for machine learning expertise. The framework optimizes robot programs that run natively on standard industrial controllers, permitting human experts to audit and certify them. Experimental validations on a center console assembly task demonstrate significant improvements in cycle times and robustness compared to conventional robot programming approaches. Videos are available under https://claudius-kienle.github.io/AppMuTT.
vMF-Contact: Uncertainty-aware Evidential Learning for Probabilistic Contact-grasp in Noisy Clutter
Nov 07, 2024Grasp learning in noisy environments, such as occlusions, sensor noise, and out-of-distribution (OOD) objects, poses significant challenges. Recent learning-based approaches focus primarily on capturing aleatoric uncertainty from inherent data noise. The epistemic uncertainty, which represents the OOD recognition, is often addressed by ensembles with multiple forward paths, limiting real-time application. In this paper, we propose an uncertainty-aware approach for 6-DoF grasp detection using evidential learning to comprehensively capture both uncertainties in real-world robotic grasping. As a key contribution, we introduce vMF-Contact, a novel architecture for learning hierarchical contact grasp representations with probabilistic modeling of directional uncertainty as von Mises-Fisher (vMF) distribution. To achieve this, we derive and analyze the theoretical formulation of the second-order objective on the posterior parametrization, providing formal guarantees for the model's ability to quantify uncertainty and improve grasp prediction performance. Moreover, we enhance feature expressiveness by applying partial point reconstructions as an auxiliary task, improving the comprehension of uncertainty quantification as well as the generalization to unseen objects. In the real-world experiments, our method demonstrates a significant improvement by 39% in the overall clearance rate compared to the baselines. Video is under https://www.youtube.com/watch?v=4aQsrDgdV8Y&t=12s
Learning Inverse Statics Models Efficiently
Oct 17, 2017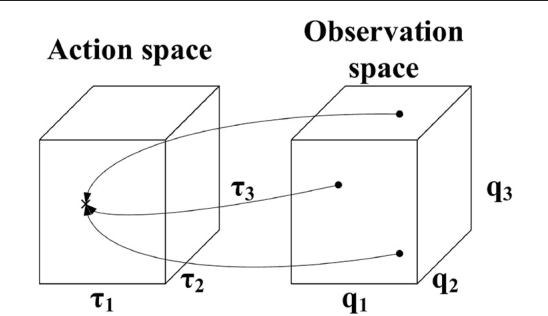
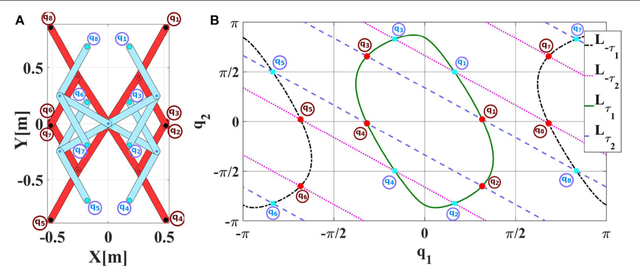
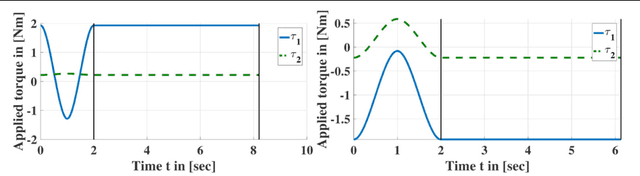
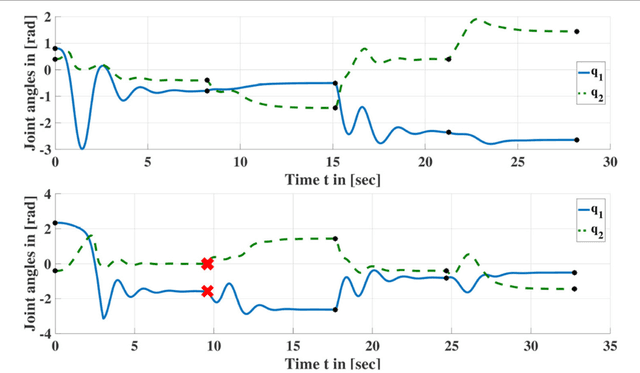
Online Goal Babbling and Direction Sampling are recently proposed methods for direct learning of inverse kinematics mappings from scratch even in high-dimensional sensorimotor spaces following the paradigm of "learning while behaving". To learn inverse statics mappings - primarily for gravity compensation - from scratch and without using any closed-loop controller, we modify and enhance the Online Goal Babbling and Direction Sampling schemes. Moreover, we exploit symmetries in the inverse statics mappings to drastically reduce the number of samples required for learning inverse statics models. Results for a 2R planar robot, a 3R simplified human arm, and a 4R humanoid robot arm clearly demonstrate that their inverse statics mappings can be learned successfully with our modified online Goal Babbling scheme. Furthermore, we show that the number of samples required for the 2R and 3R arms can be reduced by a factor of at least 8 and 16 resp. -depending on the number of discovered symmetries.