 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning
Jan 22, 2020
With the emergence of a spectrum of high-end mobile devices, many applications that formerly required desktop-level computation capability are being transferred to these devices. However, executing the inference of Deep Neural Networks (DNNs) is still challenging considering high computation and storage demands, specifically, if real-time performance with high accuracy is needed. Weight pruning of DNNs is proposed, but existing schemes represent two extremes in the design space: non-structured pruning is fine-grained, accurate, but not hardware friendly; structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss. In this paper, we introduce a new dimension, fine-grained pruning patterns inside the coarse-grained structures, revealing a previously unknown point in design space. With the higher accuracy enabled by fine-grained pruning patterns, the unique insight is to use the compiler to re-gain and guarantee high hardware efficiency. In other words, our method achieves the best of both worlds, and is desirable across theory/algorithm, compiler, and hardware levels. The proposed PatDNN is an end-to-end framework to efficiently execute DNN on mobile devices with the help of a novel model compression technique (pattern-based pruning based on extended ADMM solution framework) and a set of thorough architecture-aware compiler- and code generation-based optimizations (filter kernel reordering, compressed weight storage, register load redundancy elimination, and parameter auto-tuning). Evaluation results demonstrate that PatDNN outperforms three state-of-the-art end-to-end DNN frameworks, TensorFlow Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 44.5x, 11.4x, and 7.1x, respectively, with no accuracy compromise. Real-time inference of representative large-scale DNNs (e.g., VGG-16, ResNet-50) can be achieved using mobile devices.
A SOT-MRAM-based Processing-In-Memory Engine for Highly Compressed DNN Implementation
Nov 24, 2019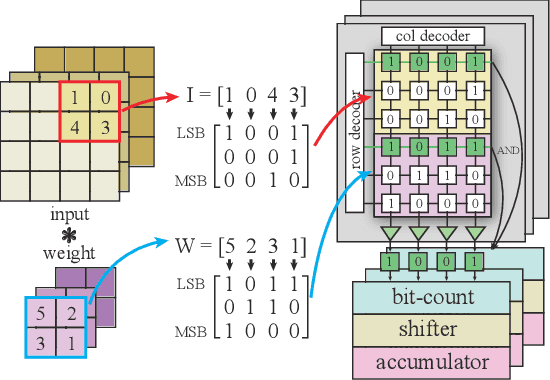
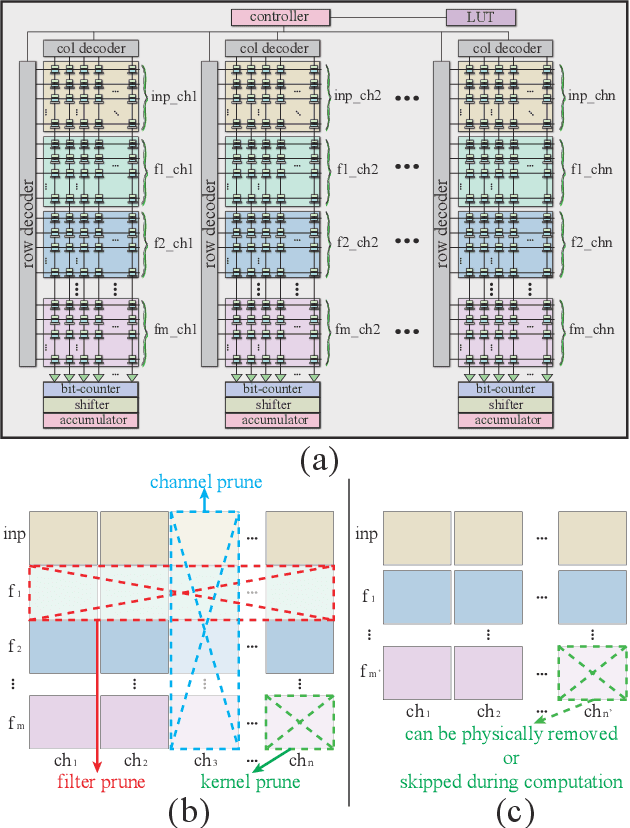
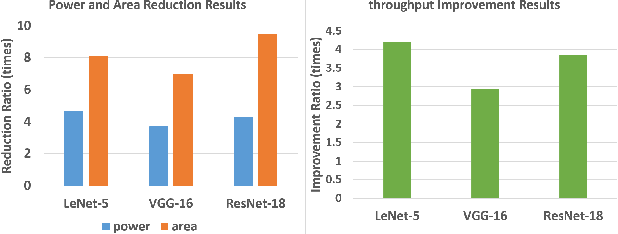
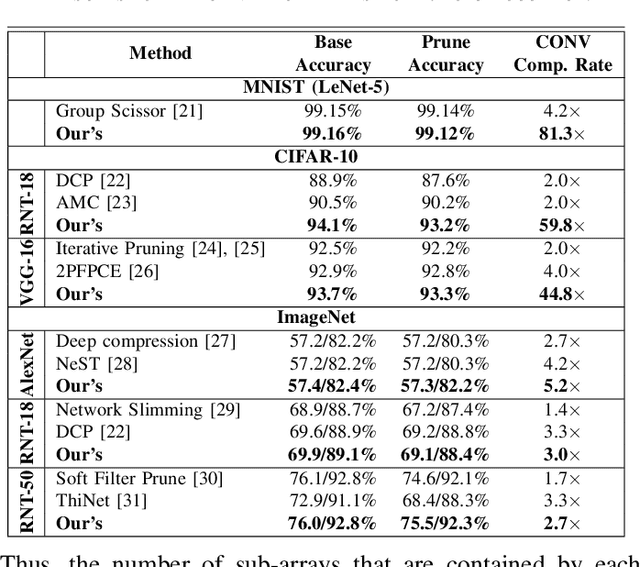
The computing wall and data movement challenges of deep neural networks (DNNs) have exposed the limitations of conventional CMOS-based DNN accelerators. Furthermore, the deep structure and large model size will make DNNs prohibitive to embedded systems and IoT devices, where low power consumption are required. To address these challenges, spin orbit torque magnetic random-access memory (SOT-MRAM) and SOT-MRAM based Processing-In-Memory (PIM) engines have been used to reduce the power consumption of DNNs since SOT-MRAM has the characteristic of near-zero standby power, high density, none-volatile. However, the drawbacks of SOT-MRAM based PIM engines such as high writing latency and requiring low bit-width data decrease its popularity as a favorable energy efficient DNN accelerator. To mitigate these drawbacks, we propose an ultra energy efficient framework by using model compression techniques including weight pruning and quantization from the software level considering the architecture of SOT-MRAM PIM. And we incorporate the alternating direction method of multipliers (ADMM) into the training phase to further guarantee the solution feasibility and satisfy SOT-MRAM hardware constraints. Thus, the footprint and power consumption of SOT-MRAM PIM can be reduced, while increasing the overall system throughput at the meantime, making our proposed ADMM-based SOT-MRAM PIM more energy efficiency and suitable for embedded systems or IoT devices. Our experimental results show the accuracy and compression rate of our proposed framework is consistently outperforming the reference works, while the efficiency (area \& power) and throughput of SOT-MRAM PIM engine is significantly improved.
DARB: A Density-Aware Regular-Block Pruning for Deep Neural Networks
Nov 20, 2019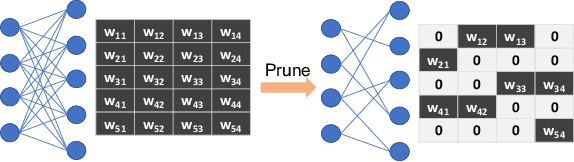
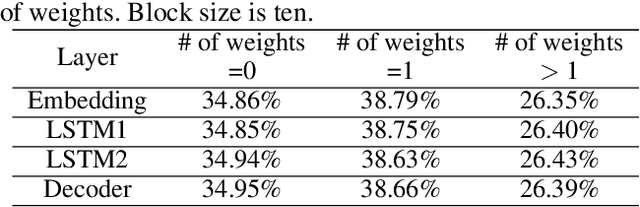
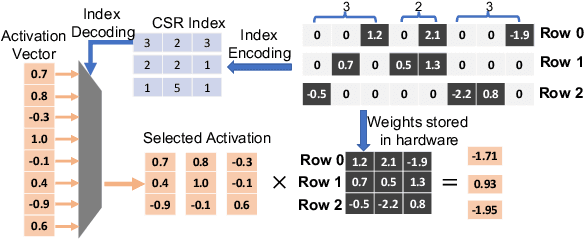
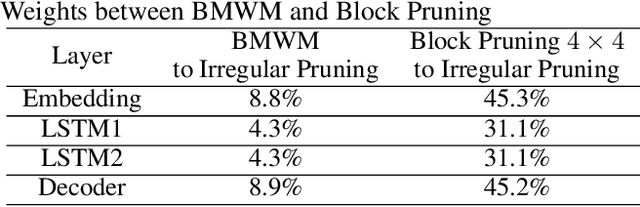
The rapidly growing parameter volume of deep neural networks (DNNs) hinders the artificial intelligence applications on resource constrained devices, such as mobile and wearable devices. Neural network pruning, as one of the mainstream model compression techniques, is under extensive study to reduce the number of parameters and computations. In contrast to irregular pruning that incurs high index storage and decoding overhead, structured pruning techniques have been proposed as the promising solutions. However, prior studies on structured pruning tackle the problem mainly from the perspective of facilitating hardware implementation, without analyzing the characteristics of sparse neural networks. The neglect on the study of sparse neural networks causes inefficient trade-off between regularity and pruning ratio. Consequently, the potential of structurally pruning neural networks is not sufficiently mined. In this work, we examine the structural characteristics of the irregularly pruned weight matrices, such as the diverse redundancy of different rows, the sensitivity of different rows to pruning, and the positional characteristics of retained weights. By leveraging the gained insights as a guidance, we first propose the novel block-max weight masking (BMWM) method, which can effectively retain the salient weights while imposing high regularity to the weight matrix. As a further optimization, we propose a density-adaptive regular-block (DARB) pruning that outperforms prior structured pruning work with high pruning ratio and decoding efficiency. Our experimental results show that DARB can achieve 13$\times$ to 25$\times$ pruning ratio, which are 2.8$\times$ to 4.3$\times$ improvements than the state-of-the-art counterparts on multiple neural network models and tasks. Moreover, DARB can achieve 14.3$\times$ decoding efficiency than block pruning with higher pruning ratio.
Deep Compressed Pneumonia Detection for Low-Power Embedded Devices
Nov 04, 2019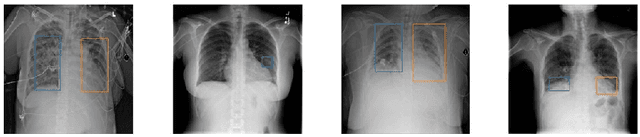
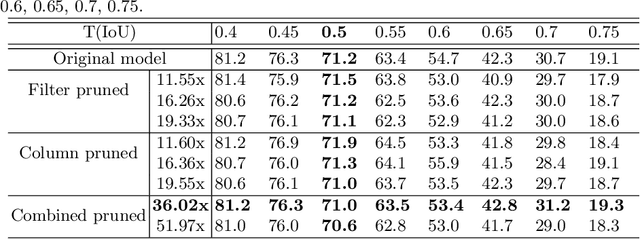
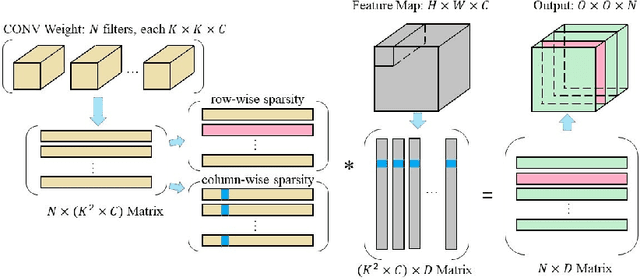
Deep neural networks (DNNs) have been expanded into medical fields and triggered the revolution of some medical applications by extracting complex features and achieving high accuracy and performance, etc. On the contrast, the large-scale network brings high requirements of both memory storage and computation resource, especially for portable medical devices and other embedded systems. In this work, we first train a DNN for pneumonia detection using the dataset provided by RSNA Pneumonia Detection Challenge. To overcome hardware limitation for implementing large-scale networks, we develop a systematic structured weight pruning method with filter sparsity, column sparsity and combined sparsity. Experiments show that we can achieve up to 36x compression ratio compared to the original model with 106 layers, while maintaining no accuracy degradation. We evaluate the proposed methods on an embedded low-power device, Jetson TX2, and achieve low power usage and high energy efficiency.
Learning Dynamic Context Augmentation for Global Entity Linking
Sep 04, 2019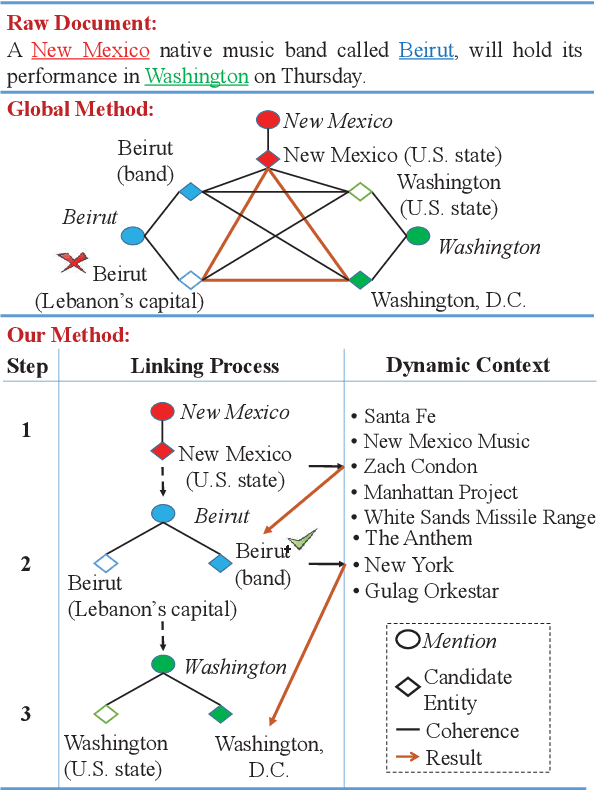
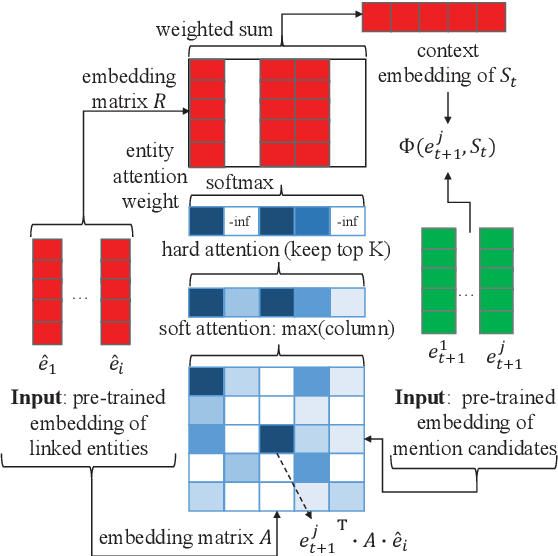
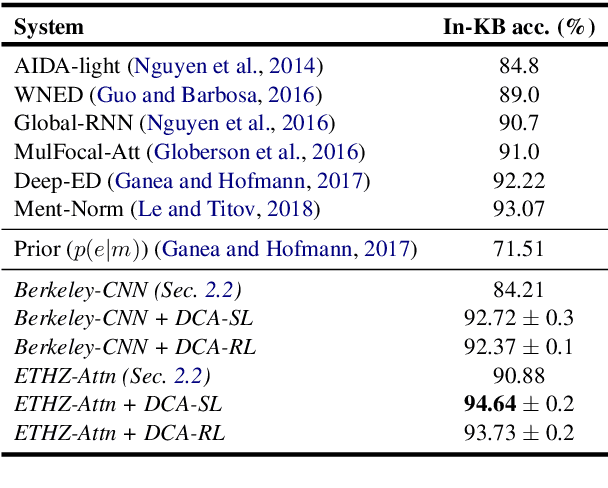
Despite of the recent success of collective entity linking (EL) methods, these "global" inference methods may yield sub-optimal results when the "all-mention coherence" assumption breaks, and often suffer from high computational cost at the inference stage, due to the complex search space. In this paper, we propose a simple yet effective solution, called Dynamic Context Augmentation (DCA), for collective EL, which requires only one pass through the mentions in a document. DCA sequentially accumulates context information to make efficient, collective inference, and can cope with different local EL models as a plug-and-enhance module. We explore both supervised and reinforcement learning strategies for learning the DCA model. Extensive experiments show the effectiveness of our model with different learning settings, base models, decision orders and attention mechanisms.
An Ultra-Efficient Memristor-Based DNN Framework with Structured Weight Pruning and Quantization Using ADMM
Aug 29, 2019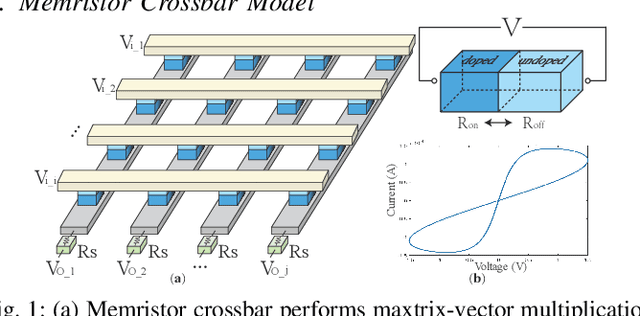
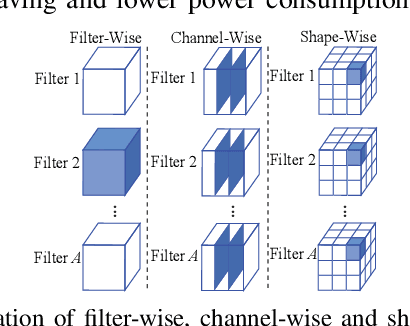
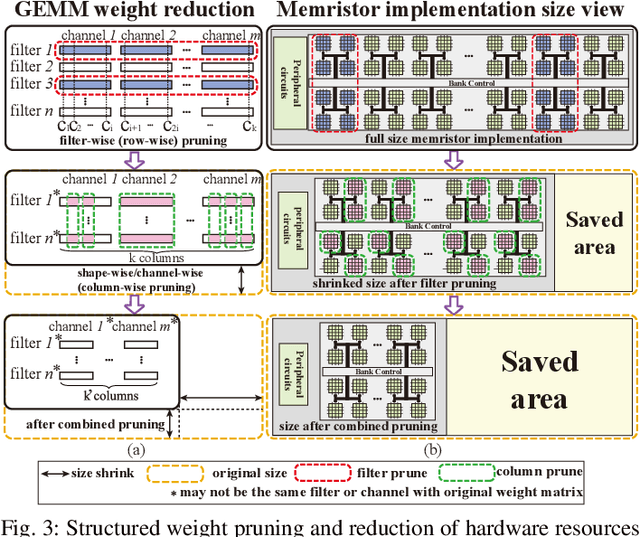
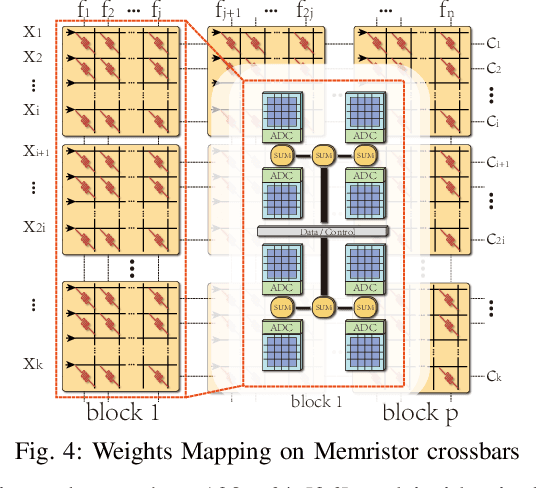
The high computation and memory storage of large deep neural networks (DNNs) models pose intensive challenges to the conventional Von-Neumann architecture, incurring substantial data movements in the memory hierarchy. The memristor crossbar array has emerged as a promising solution to mitigate the challenges and enable low-power acceleration of DNNs. Memristor-based weight pruning and weight quantization have been seperately investigated and proven effectiveness in reducing area and power consumption compared to the original DNN model. However, there has been no systematic investigation of memristor-based neuromorphic computing (NC) systems considering both weight pruning and weight quantization. In this paper, we propose an unified and systematic memristor-based framework considering both structured weight pruning and weight quantization by incorporating alternating direction method of multipliers (ADMM) into DNNs training. We consider hardware constraints such as crossbar blocks pruning, conductance range, and mismatch between weight value and real devices, to achieve high accuracy and low power and small area footprint. Our framework is mainly integrated by three steps, i.e., memristor-based ADMM regularized optimization, masked mapping and retraining. Experimental results show that our proposed framework achieves 29.81X (20.88X) weight compression ratio, with 98.38% (96.96%) and 98.29% (97.47%) power and area reduction on VGG-16 (ResNet-18) network where only have 0.5% (0.76%) accuracy loss, compared to the original DNN models. We share our models at link http://bit.ly/2Jp5LHJ.
Tiny but Accurate: A Pruned, Quantized and Optimized Memristor Crossbar Framework for Ultra Efficient DNN Implementation
Aug 27, 2019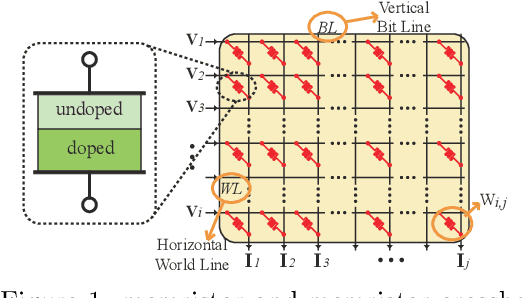
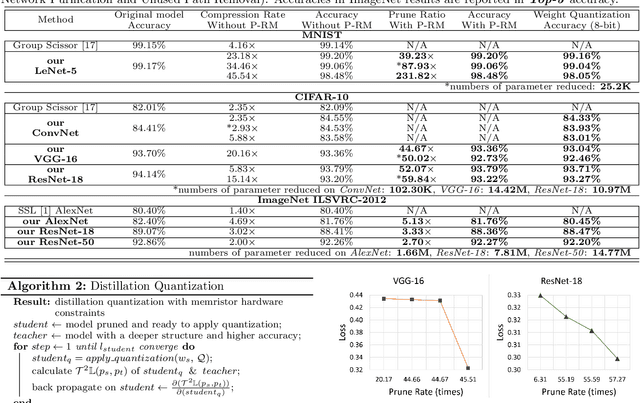
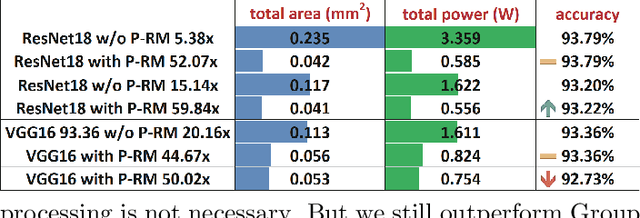
The state-of-art DNN structures involve intensive computation and high memory storage. To mitigate the challenges, the memristor crossbar array has emerged as an intrinsically suitable matrix computation and low-power acceleration framework for DNN applications. However, the high accuracy solution for extreme model compression on memristor crossbar array architecture is still waiting for unraveling. In this paper, we propose a memristor-based DNN framework which combines both structured weight pruning and quantization by incorporating alternating direction method of multipliers (ADMM) algorithm for better pruning and quantization performance. We also discover the non-optimality of the ADMM solution in weight pruning and the unused data path in a structured pruned model. Motivated by these discoveries, we design a software-hardware co-optimization framework which contains the first proposed Network Purification and Unused Path Removal algorithms targeting on post-processing a structured pruned model after ADMM steps. By taking memristor hardware constraints into our whole framework, we achieve extreme high compression ratio on the state-of-art neural network structures with minimum accuracy loss. For quantizing structured pruned model, our framework achieves nearly no accuracy loss after quantizing weights to 8-bit memristor weight representation. We share our models at anonymous link https://bit.ly/2VnMUy0.
Non-structured DNN Weight Pruning Considered Harmful
Jul 03, 2019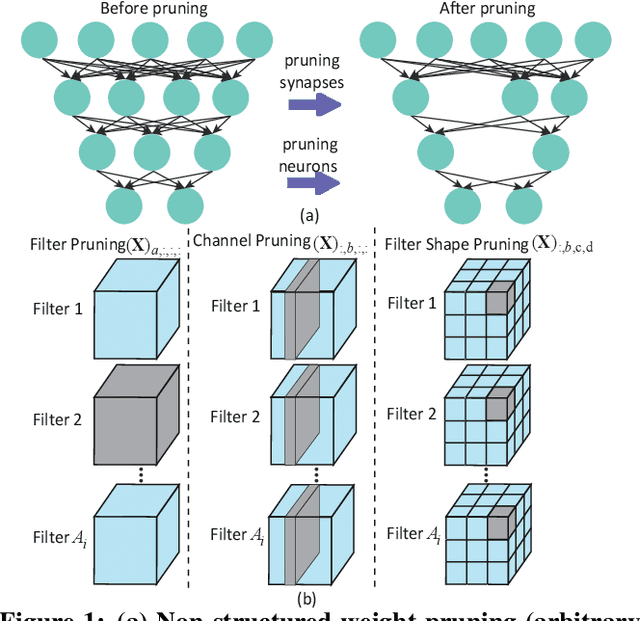
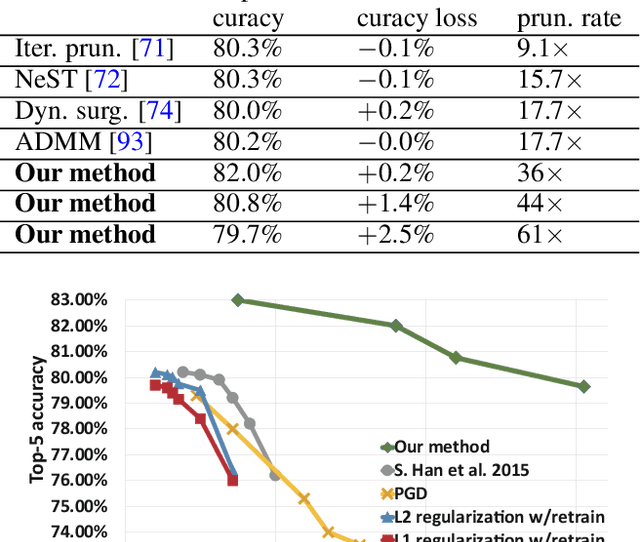
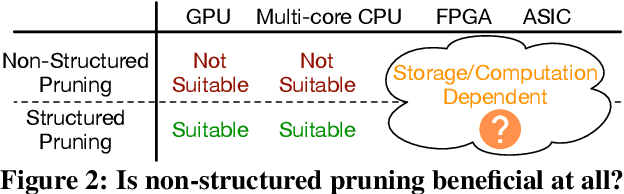
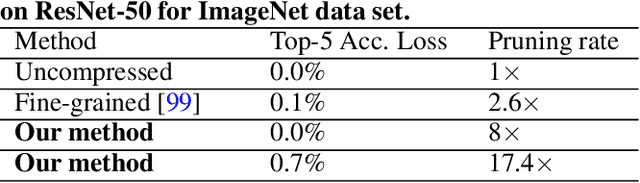
Large deep neural network (DNN) models pose the key challenge to energy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensive research on model compression with two main approaches. Weight pruning leverages the redundancy in the number of weights and can be performed in a non-structured, which has higher flexibility and pruning rate but incurs index accesses due to irregular weights, or structured manner, which preserves the full matrix structure with lower pruning rate. Weight quantization leverages the redundancy in the number of bits in weights. Compared to pruning, quantization is much more hardware-friendly, and has become a "must-do" step for FPGA and ASIC implementations. This paper provides a definitive answer to the question for the first time. First, we build ADMM-NN-S by extending and enhancing ADMM-NN, a recently proposed joint weight pruning and quantization framework. Second, we develop a methodology for fair and fundamental comparison of non-structured and structured pruning in terms of both storage and computation efficiency. Our results show that ADMM-NN-S consistently outperforms the prior art: (i) it achieves 348x, 36x, and 8x overall weight pruning on LeNet-5, AlexNet, and ResNet-50, respectively, with (almost) zero accuracy loss; (ii) we demonstrate the first fully binarized (for all layers) DNNs can be lossless in accuracy in many cases. These results provide a strong baseline and credibility of our study. Based on the proposed comparison framework, with the same accuracy and quantization, the results show that non-structrued pruning is not competitive in terms of both storage and computation efficiency. Thus, we conclude that non-structured pruning is considered harmful. We urge the community not to continue the DNN inference acceleration for non-structured sparsity.
KCAT: A Knowledge-Constraint Typing Annotation Tool
Jun 13, 2019
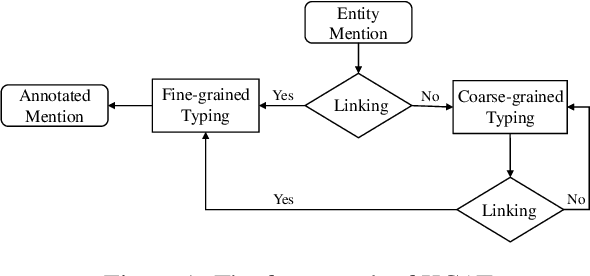
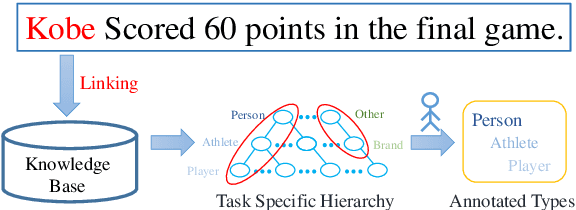
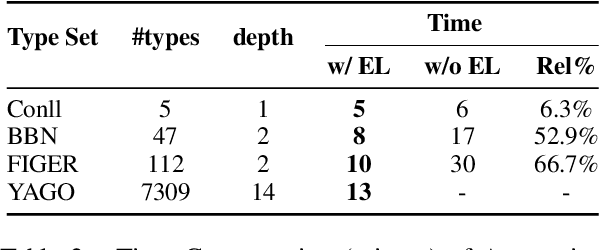
Fine-grained Entity Typing is a tough task which suffers from noise samples extracted from distant supervision. Thousands of manually annotated samples can achieve greater performance than millions of samples generated by the previous distant supervision method. Whereas, it's hard for human beings to differentiate and memorize thousands of types, thus making large-scale human labeling hardly possible. In this paper, we introduce a Knowledge-Constraint Typing Annotation Tool (KCAT), which is efficient for fine-grained entity typing annotation. KCAT reduces the size of candidate types to an acceptable range for human beings through entity linking and provides a Multi-step Typing scheme to revise the entity linking result. Moreover, KCAT provides an efficient Annotator Client to accelerate the annotation process and a comprehensive Manager Module to analyse crowdsourcing annotations. Experiment shows that KCAT can significantly improve annotation efficiency, the time consumption increases slowly as the size of type set expands.
Toward Extremely Low Bit and Lossless Accuracy in DNNs with Progressive ADMM
May 02, 2019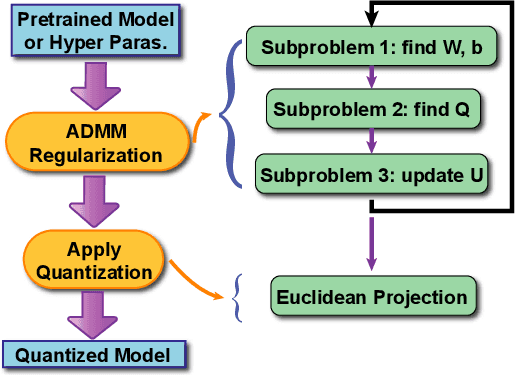
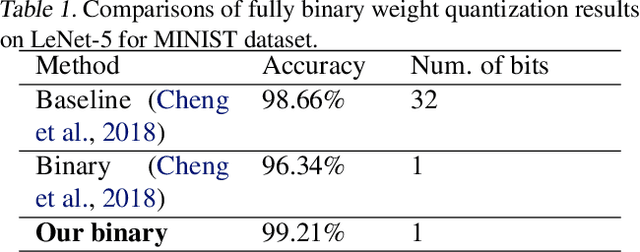
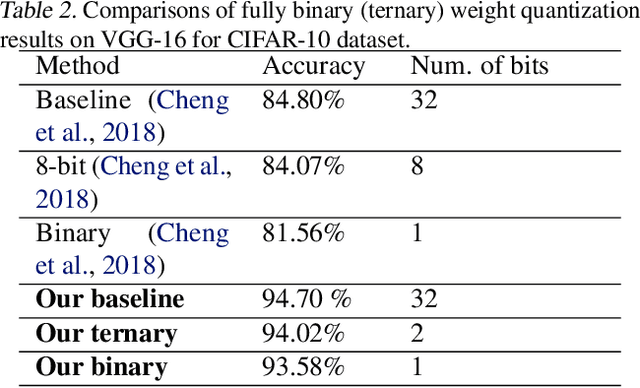
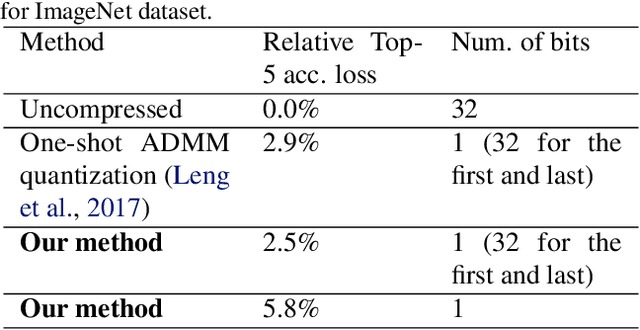
Weight quantization is one of the most important techniques of Deep Neural Networks (DNNs) model compression method. A recent work using systematic framework of DNN weight quantization with the advanced optimization algorithm ADMM (Alternating Direction Methods of Multipliers) achieves one of state-of-art results in weight quantization. In this work, we first extend such ADMM-based framework to guarantee solution feasibility and we have further developed a multi-step, progressive DNN weight quantization framework, with dual benefits of (i) achieving further weight quantization thanks to the special property of ADMM regularization, and (ii) reducing the search space within each step. Extensive experimental results demonstrate the superior performance compared with prior work. Some highlights: we derive the first lossless and fully binarized (for all layers) LeNet-5 for MNIST; And we derive the first fully binarized (for all layers) VGG-16 for CIFAR-10 and ResNet for ImageNet with reasonable accuracy loss.