 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaultDiffusion: Few-Shot Fault Time Series Generation with Diffusion Model
Nov 19, 2025In industrial equipment monitoring, fault diagnosis is critical for ensuring system reliability and enabling predictive maintenance. However, the scarcity of fault data, due to the rarity of fault events and the high cost of data annotation, significantly hinders data-driven approaches. Existing time-series generation models, optimized for abundant normal data, struggle to capture fault distributions in few-shot scenarios, producing samples that lack authenticity and diversity due to the large domain gap and high intra-class variability of faults. To address this, we propose a novel few-shot fault time-series generation framework based on diffusion models. Our approach employs a positive-negative difference adapter, leveraging pre-trained normal data distributions to model the discrepancies between normal and fault domains for accurate fault synthesis. Additionally, a diversity loss is introduced to prevent mode collapse, encouraging the generation of diverse fault samples through inter-sample difference regularization. Experimental results demonstrate that our model significantly outperforms traditional methods in authenticity and diversity, achieving state-of-the-art performance on key benchmarks.
C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Aug 19, 2024



Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.
Factorized Learning Assisted with Large Language Model for Gloss-free Sign Language Translation
Mar 19, 2024



Previous Sign Language Translation (SLT) methods achieve superior performance by relying on gloss annotations. However, labeling high-quality glosses is a labor-intensive task, which limits the further development of SLT. Although some approaches work towards gloss-free SLT through jointly training the visual encoder and translation network, these efforts still suffer from poor performance and inefficient use of the powerful Large Language Model (LLM). Most seriously, we find that directly introducing LLM into SLT will lead to insufficient learning of visual representations as LLM dominates the learning curve. To address these problems, we propose Factorized Learning assisted with Large Language Model (FLa-LLM) for gloss-free SLT. Concretely, we factorize the training process into two stages. In the visual initialing stage, we employ a lightweight translation model after the visual encoder to pre-train the visual encoder. In the LLM fine-tuning stage, we freeze the acquired knowledge in the visual encoder and integrate it with a pre-trained LLM to inspire the LLM's translation potential. This factorized training strategy proves to be highly effective as evidenced by significant improvements achieved across three SLT datasets which are all conducted under the gloss-free setting.
Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining
Jul 27, 2023



Sign Language Translation (SLT) is a challenging task due to its cross-domain nature, involving the translation of visual-gestural language to text. Many previous methods employ an intermediate representation, i.e., gloss sequences, to facilitate SLT, thus transforming it into a two-stage task of sign language recognition (SLR) followed by sign language translation (SLT). However, the scarcity of gloss-annotated sign language data, combined with the information bottleneck in the mid-level gloss representation, has hindered the further development of the SLT task. To address this challenge, we propose a novel Gloss-Free SLT based on Visual-Language Pretraining (GFSLT-VLP), which improves SLT by inheriting language-oriented prior knowledge from pre-trained models, without any gloss annotation assistance. Our approach involves two stages: (i) integrating Contrastive Language-Image Pre-training (CLIP) with masked self-supervised learning to create pre-tasks that bridge the semantic gap between visual and textual representations and restore masked sentences, and (ii) constructing an end-to-end architecture with an encoder-decoder-like structure that inherits the parameters of the pre-trained Visual Encoder and Text Decoder from the first stage. The seamless combination of these novel designs forms a robust sign language representation and significantly improves gloss-free sign language translation. In particular, we have achieved unprecedented improvements in terms of BLEU-4 score on the PHOENIX14T dataset (>+5) and the CSL-Daily dataset (>+3) compared to state-of-the-art gloss-free SLT methods. Furthermore, our approach also achieves competitive results on the PHOENIX14T dataset when compared with most of the gloss-based methods. Our code is available at https://github.com/zhoubenjia/GFSLT-VLP.
WIDER & CLOSER: Mixture of Short-channel Distillers for Zero-shot Cross-lingual Named Entity Recognition
Dec 07, 2022



Zero-shot cross-lingual named entity recognition (NER) aims at transferring knowledge from annotated and rich-resource data in source languages to unlabeled and lean-resource data in target languages. Existing mainstream methods based on the teacher-student distillation framework ignore the rich and complementary information lying in the intermediate layers of pre-trained language models, and domain-invariant information is easily lost during transfer. In this study, a mixture of short-channel distillers (MSD) method is proposed to fully interact the rich hierarchical information in the teacher model and to transfer knowledge to the student model sufficiently and efficiently. Concretely, a multi-channel distillation framework is designed for sufficient information transfer by aggregating multiple distillers as a mixture. Besides, an unsupervised method adopting parallel domain adaptation is proposed to shorten the channels between the teacher and student models to preserve domain-invariant features. Experiments on four datasets across nine languages demonstrate that the proposed method achieves new state-of-the-art performance on zero-shot cross-lingual NER and shows great generalization and compatibility across languages and fields.
Long-Document Cross-Lingual Summarization
Dec 01, 2022



Cross-Lingual Summarization (CLS) aims at generating summaries in one language for the given documents in another language. CLS has attracted wide research attention due to its practical significance in the multi-lingual world. Though great contributions have been made, existing CLS works typically focus on short documents, such as news articles, short dialogues and guides. Different from these short texts, long documents such as academic articles and business reports usually discuss complicated subjects and consist of thousands of words, making them non-trivial to process and summarize. To promote CLS research on long documents, we construct Perseus, the first long-document CLS dataset which collects about 94K Chinese scientific documents paired with English summaries. The average length of documents in Perseus is more than two thousand tokens. As a preliminary study on long-document CLS, we build and evaluate various CLS baselines, including pipeline and end-to-end methods. Experimental results on Perseus show the superiority of the end-to-end baseline, outperforming the strong pipeline models equipped with sophisticated machine translation systems. Furthermore, to provide a deeper understanding, we manually analyze the model outputs and discuss specific challenges faced by current approaches. We hope that our work could benchmark long-document CLS and benefit future studies.
Overview of CTC 2021: Chinese Text Correction for Native Speakers
Aug 11, 2022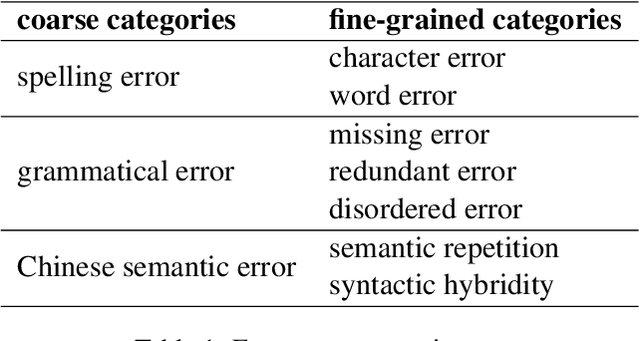
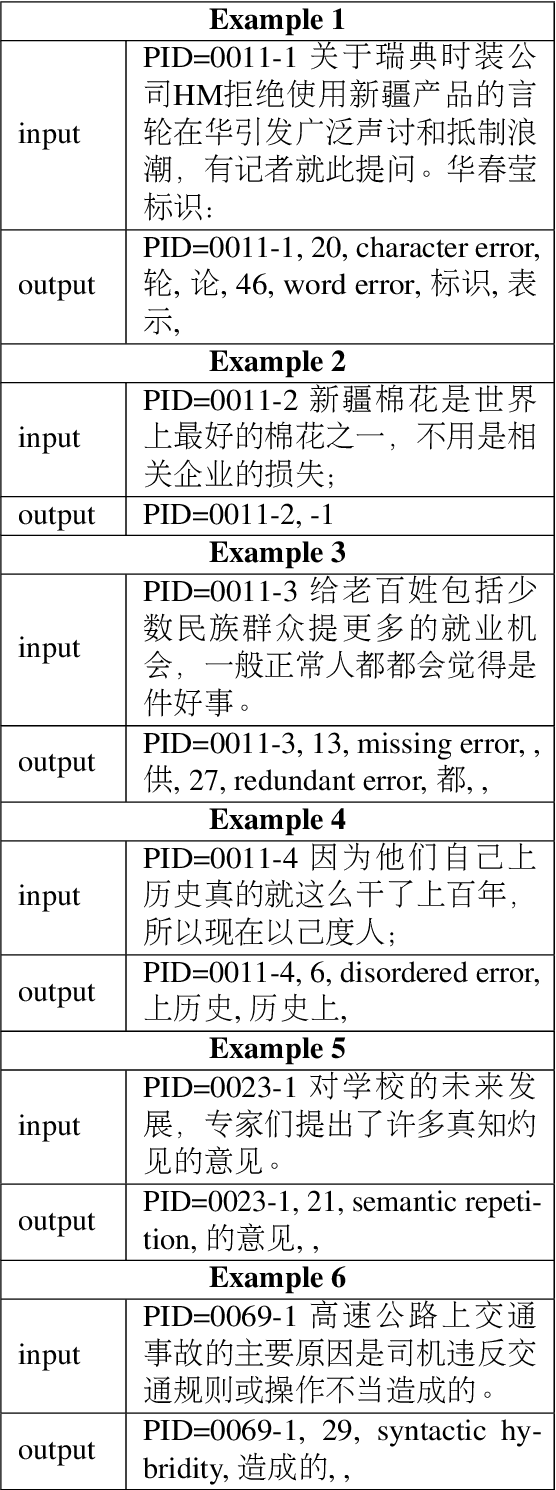

In this paper, we present an overview of the CTC 2021, a Chinese text correction task for native speakers. We give detailed descriptions of the task definition and the data for training as well as evaluation. We also summarize the approaches investigated by the participants of this task. We hope the data sets collected and annotated for this task can facilitate and expedite future development in this research area. Therefore, the pseudo training data, gold standards validation data, and entire leaderboard is publicly available online at https://destwang.github.io/CTC2021-explorer/.
JiuZhang: A Chinese Pre-trained Language Model for Mathematical Problem Understanding
Jun 13, 2022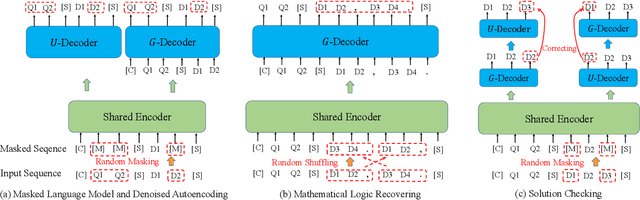
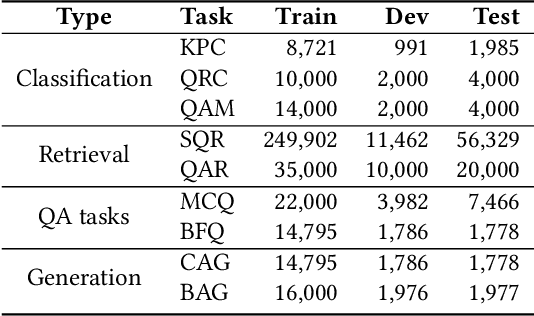
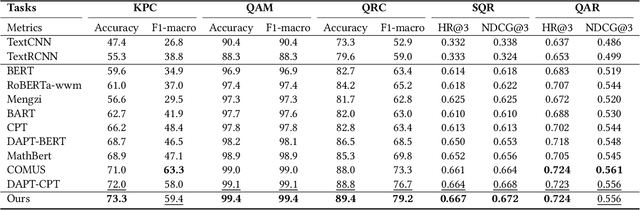

This paper aims to advance the mathematical intelligence of machines by presenting the first Chinese mathematical pre-trained language model~(PLM) for effectively understanding and representing mathematical problems. Unlike other standard NLP tasks, mathematical texts are difficult to understand, since they involve mathematical terminology, symbols and formulas in the problem statement. Typically, it requires complex mathematical logic and background knowledge for solving mathematical problems. Considering the complex nature of mathematical texts, we design a novel curriculum pre-training approach for improving the learning of mathematical PLMs, consisting of both basic and advanced courses. Specially, we first perform token-level pre-training based on a position-biased masking strategy, and then design logic-based pre-training tasks that aim to recover the shuffled sentences and formulas, respectively. Finally, we introduce a more difficult pre-training task that enforces the PLM to detect and correct the errors in its generated solutions. We conduct extensive experiments on offline evaluation (including nine math-related tasks) and online $A/B$ test. Experimental results demonstrate the effectiveness of our approach compared with a number of competitive baselines. Our code is available at: \textcolor{blue}{\url{https://github.com/RUCAIBox/JiuZhang}}.
Actions at the Edge: Jointly Optimizing the Resources in Multi-access Edge Computing
Apr 18, 2022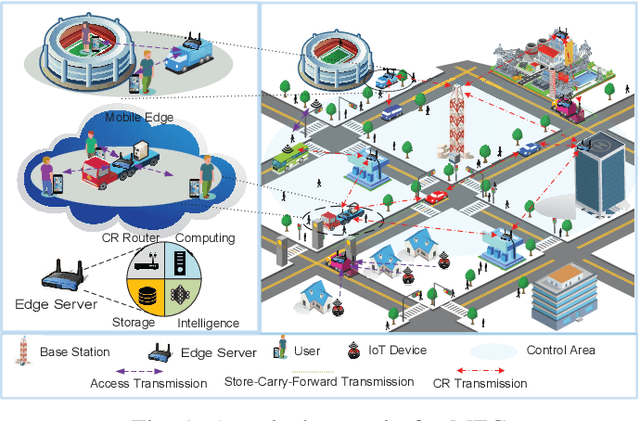
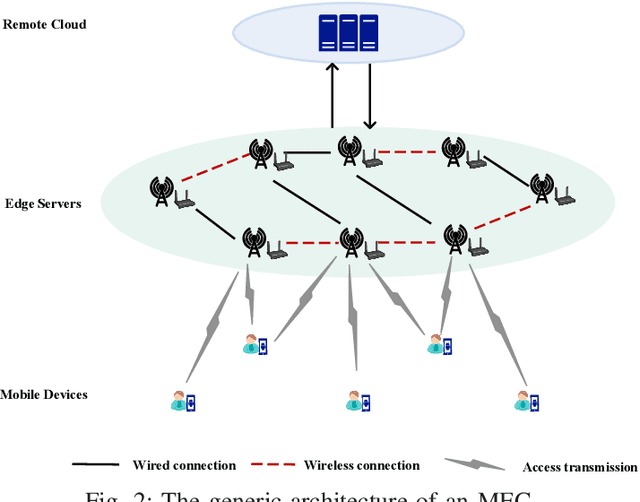
Multi-access edge computing (MEC) is an emerging paradigm that pushes resources for sensing, communications, computing, storage and intelligence (SCCSI) to the premises closer to the end users, i.e., the edge, so that they could leverage the nearby rich resources to improve their quality of experience (QoE). Due to the growing emerging applications targeting at intelligentizing life-sustaining cyber-physical systems, this paradigm has become a hot research topic, particularly when MEC is utilized to provide edge intelligence and real-time processing and control. This article is to elaborate the research issues along this line, including basic concepts and performance metrics, killer applications, architectural design, modeling approaches and solutions, and future research directions. It is hoped that this article provides a quick introduction to this fruitful research area particularly for beginning researchers.
Improving Pre-trained Language Models with Syntactic Dependency Prediction Task for Chinese Semantic Error Recognition
Apr 15, 2022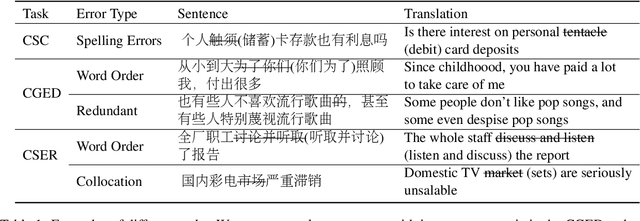
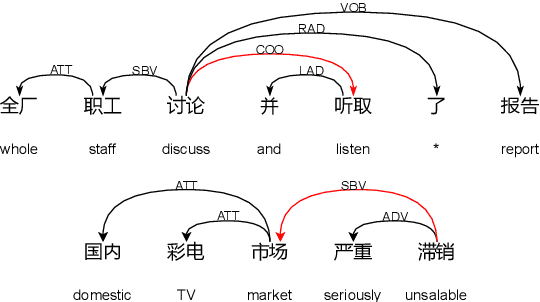

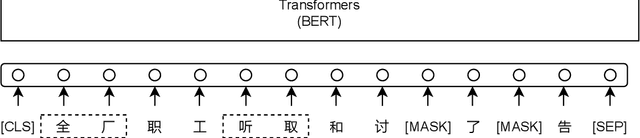
Existing Chinese text error detection mainly focuses on spelling and simple grammatical errors. These errors have been studied extensively and are relatively simple for humans. On the contrary, Chinese semantic errors are understudied and more complex that humans cannot easily recognize. The task of this paper is Chinese Semantic Error Recognition (CSER), a binary classification task to determine whether a sentence contains semantic errors. The current research has no effective method to solve this task. In this paper, we inherit the model structure of BERT and design several syntax-related pre-training tasks so that the model can learn syntactic knowledge. Our pre-training tasks consider both the directionality of the dependency structure and the diversity of the dependency relationship. Due to the lack of a published dataset for CSER, we build a high-quality dataset for CSER for the first time named Corpus of Chinese Linguistic Semantic Acceptability (CoCLSA). The experimental results on the CoCLSA show that our methods outperform universal pre-trained models and syntax-infused models.