 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRearrangement: A Challenge for Embodied AI
Nov 03, 2020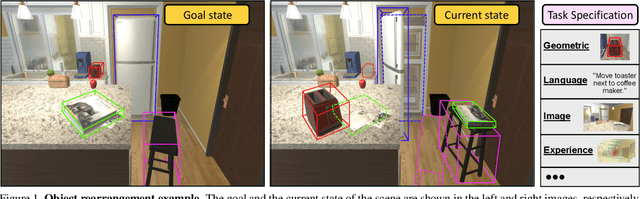
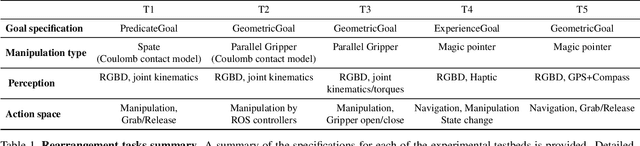


We describe a framework for research and evaluation in Embodied AI. Our proposal is based on a canonical task: Rearrangement. A standard task can focus the development of new techniques and serve as a source of trained models that can be transferred to other settings. In the rearrangement task, the goal is to bring a given physical environment into a specified state. The goal state can be specified by object poses, by images, by a description in language, or by letting the agent experience the environment in the goal state. We characterize rearrangement scenarios along different axes and describe metrics for benchmarking rearrangement performance. To facilitate research and exploration, we present experimental testbeds of rearrangement scenarios in four different simulation environments. We anticipate that other datasets will be released and new simulation platforms will be built to support training of rearrangement agents and their deployment on physical systems.
COG: Connecting New Skills to Past Experience with Offline Reinforcement Learning
Oct 27, 2020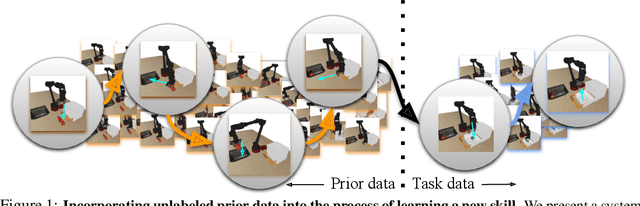
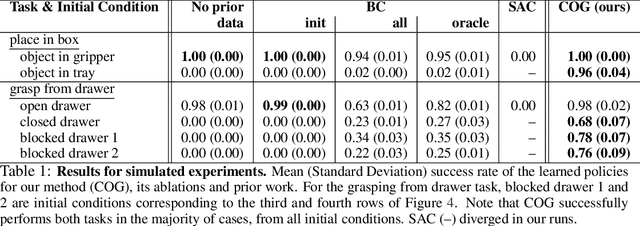
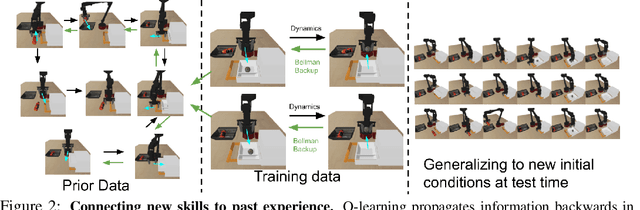

Reinforcement learning has been applied to a wide variety of robotics problems, but most of such applications involve collecting data from scratch for each new task. Since the amount of robot data we can collect for any single task is limited by time and cost considerations, the learned behavior is typically narrow: the policy can only execute the task in a handful of scenarios that it was trained on. What if there was a way to incorporate a large amount of prior data, either from previously solved tasks or from unsupervised or undirected environment interaction, to extend and generalize learned behaviors? While most prior work on extending robotic skills using pre-collected data focuses on building explicit hierarchies or skill decompositions, we show in this paper that we can reuse prior data to extend new skills simply through dynamic programming. We show that even when the prior data does not actually succeed at solving the new task, it can still be utilized for learning a better policy, by providing the agent with a broader understanding of the mechanics of its environment. We demonstrate the effectiveness of our approach by chaining together several behaviors seen in prior datasets for solving a new task, with our hardest experimental setting involving composing four robotic skills in a row: picking, placing, drawer opening, and grasping, where a +1/0 sparse reward is provided only on task completion. We train our policies in an end-to-end fashion, mapping high-dimensional image observations to low-level robot control commands, and present results in both simulated and real world domains. Additional materials and source code can be found on our project website: https://sites.google.com/view/cog-rl
Implicit Under-Parameterization Inhibits Data-Efficient Deep Reinforcement Learning
Oct 27, 2020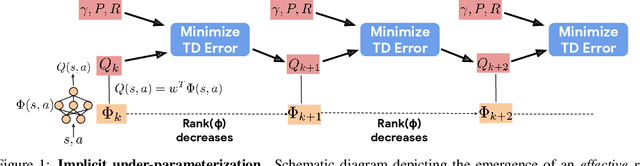
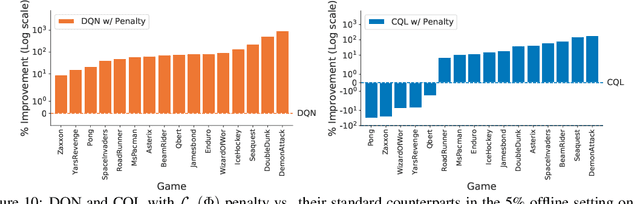
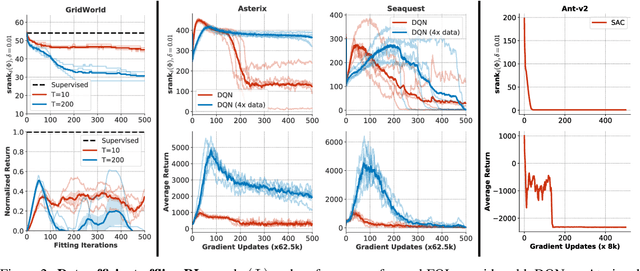
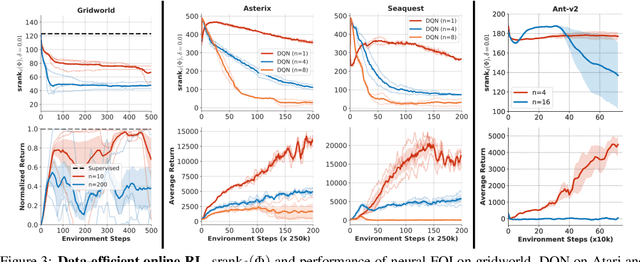
We identify an implicit under-parameterization phenomenon in value-based deep RL methods that use bootstrapping: when value functions, approximated using deep neural networks, are trained with gradient descent using iterated regression onto target values generated by previous instances of the value network, more gradient updates decrease the expressivity of the current value network. We characterize this loss of expressivity in terms of a drop in the rank of the learned value network features, and show that this corresponds to a drop in performance. We demonstrate this phenomenon on widely studies domains, including Atari and Gym benchmarks, in both offline and online RL settings. We formally analyze this phenomenon and show that it results from a pathological interaction between bootstrapping and gradient-based optimization. We further show that mitigating implicit under-parameterization by controlling rank collapse improves performance.
Conservative Safety Critics for Exploration
Oct 27, 2020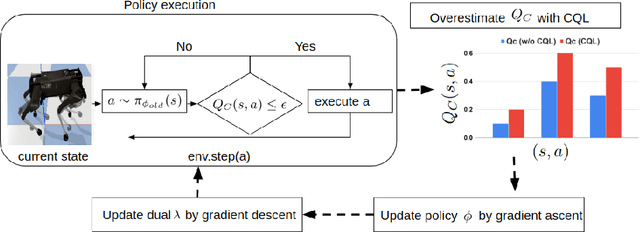

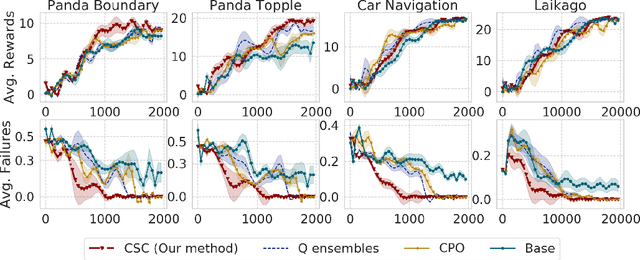
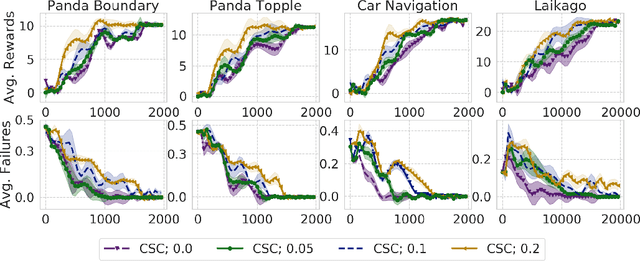
Safe exploration presents a major challenge in reinforcement learning (RL): when active data collection requires deploying partially trained policies, we must ensure that these policies avoid catastrophically unsafe regions, while still enabling trial and error learning. In this paper, we target the problem of safe exploration in RL by learning a conservative safety estimate of environment states through a critic, and provably upper bound the likelihood of catastrophic failures at every training iteration. We theoretically characterize the tradeoff between safety and policy improvement, show that the safety constraints are likely to be satisfied with high probability during training, derive provable convergence guarantees for our approach, which is no worse asymptotically than standard RL, and demonstrate the efficacy of the proposed approach on a suite of challenging navigation, manipulation, and locomotion tasks. Empirically, we show that the proposed approach can achieve competitive task performance while incurring significantly lower catastrophic failure rates during training than prior methods. Videos are at this url https://sites.google.com/view/conservative-safety-critics/home
$γ$-Models: Generative Temporal Difference Learning for Infinite-Horizon Prediction
Oct 27, 2020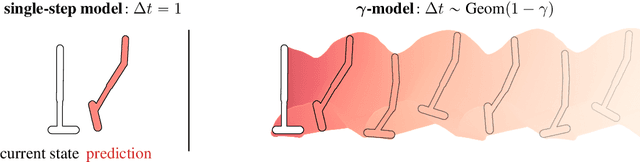

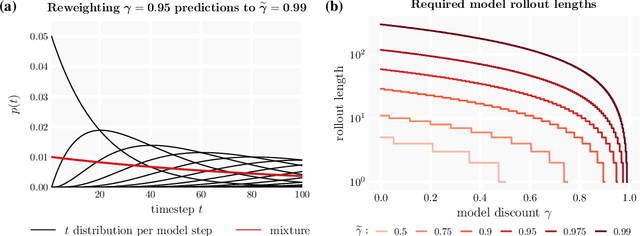

We introduce the $\gamma$-model, a predictive model of environment dynamics with an infinite probabilistic horizon. Replacing standard single-step models with $\gamma$-models leads to generalizations of the procedures that form the foundation of model-based control, including the model rollout and model-based value estimation. The $\gamma$-model, trained with a generative reinterpretation of temporal difference learning, is a natural continuous analogue of the successor representation and a hybrid between model-free and model-based mechanisms. Like a value function, it contains information about the long-term future; like a standard predictive model, it is independent of task reward. We instantiate the $\gamma$-model as both a generative adversarial network and normalizing flow, discuss how its training reflects an inescapable tradeoff between training-time and testing-time compounding errors, and empirically investigate its utility for prediction and control.
One Solution is Not All You Need: Few-Shot Extrapolation via Structured MaxEnt RL
Oct 27, 2020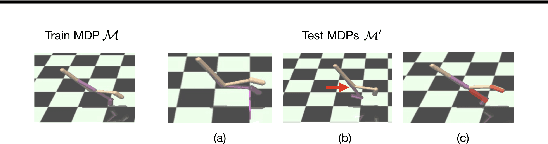
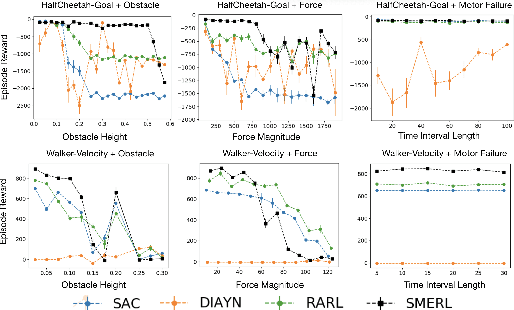
While reinforcement learning algorithms can learn effective policies for complex tasks, these policies are often brittle to even minor task variations, especially when variations are not explicitly provided during training. One natural approach to this problem is to train agents with manually specified variation in the training task or environment. However, this may be infeasible in practical situations, either because making perturbations is not possible, or because it is unclear how to choose suitable perturbation strategies without sacrificing performance. The key insight of this work is that learning diverse behaviors for accomplishing a task can directly lead to behavior that generalizes to varying environments, without needing to perform explicit perturbations during training. By identifying multiple solutions for the task in a single environment during training, our approach can generalize to new situations by abandoning solutions that are no longer effective and adopting those that are. We theoretically characterize a robustness set of environments that arises from our algorithm and empirically find that our diversity-driven approach can extrapolate to various changes in the environment and task.
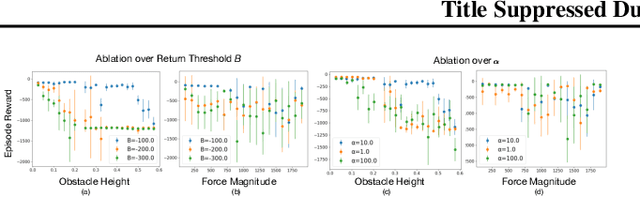
OPAL: Offline Primitive Discovery for Accelerating Offline Reinforcement Learning
Oct 27, 2020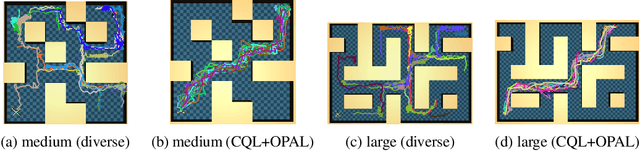

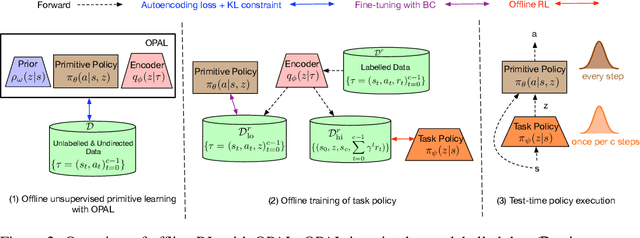

Reinforcement learning (RL) has achieved impressive performance in a variety of online settings in which an agent's ability to query the environment for transitions and rewards is effectively unlimited. However, in many practical applications, the situation is reversed: an agent may have access to large amounts of undirected offline experience data, while access to the online environment is severely limited. In this work, we focus on this offline setting. Our main insight is that, when presented with offline data composed of a variety of behaviors, an effective way to leverage this data is to extract a continuous space of recurring and temporally extended primitive behaviors before using these primitives for downstream task learning. Primitives extracted in this way serve two purposes: they delineate the behaviors that are supported by the data from those that are not, making them useful for avoiding distributional shift in offline RL; and they provide a degree of temporal abstraction, which reduces the effective horizon yielding better learning in theory, and improved offline RL in practice. In addition to benefiting offline policy optimization, we show that performing offline primitive learning in this way can also be leveraged for improving few-shot imitation learning as well as exploration and transfer in online RL on a variety of benchmark domains. Visualizations are available at https://sites.google.com/view/opal-iclr
MELD: Meta-Reinforcement Learning from Images via Latent State Models
Oct 26, 2020
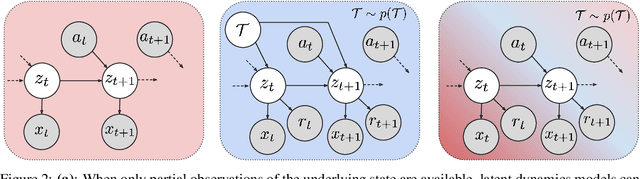
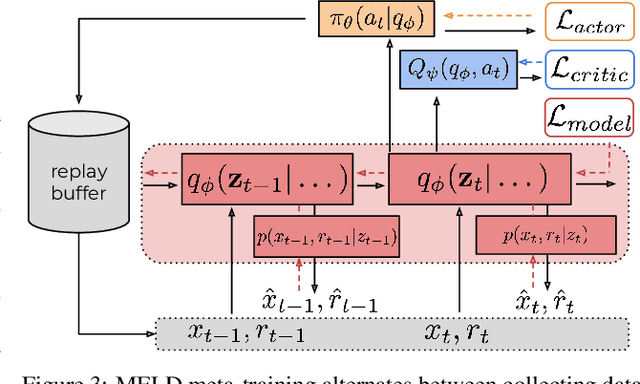
Meta-reinforcement learning algorithms can enable autonomous agents, such as robots, to quickly acquire new behaviors by leveraging prior experience in a set of related training tasks. However, the onerous data requirements of meta-training compounded with the challenge of learning from sensory inputs such as images have made meta-RL challenging to apply to real robotic systems. Latent state models, which learn compact state representations from a sequence of observations, can accelerate representation learning from visual inputs. In this paper, we leverage the perspective of meta-learning as task inference to show that latent state models can \emph{also} perform meta-learning given an appropriately defined observation space. Building on this insight, we develop meta-RL with latent dynamics (MELD), an algorithm for meta-RL from images that performs inference in a latent state model to quickly acquire new skills given observations and rewards. MELD outperforms prior meta-RL methods on several simulated image-based robotic control problems, and enables a real WidowX robotic arm to insert an Ethernet cable into new locations given a sparse task completion signal after only $8$ hours of real world meta-training. To our knowledge, MELD is the first meta-RL algorithm trained in a real-world robotic control setting from images.
LaND: Learning to Navigate from Disengagements
Oct 09, 2020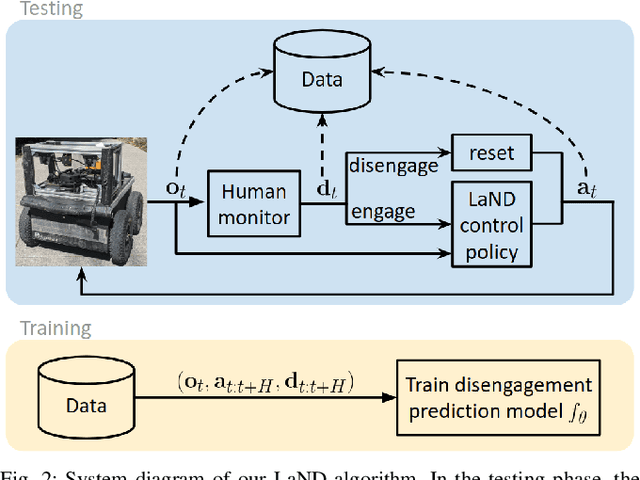

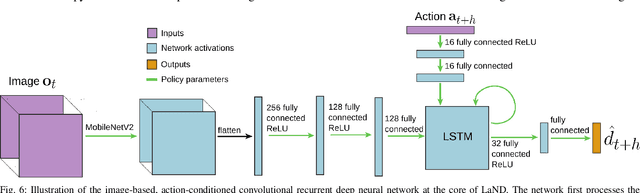
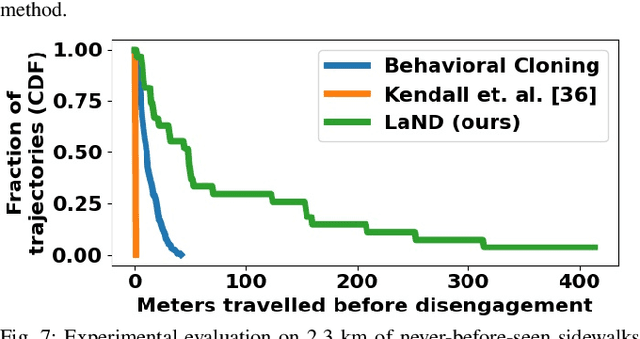
Consistently testing autonomous mobile robots in real world scenarios is a necessary aspect of developing autonomous navigation systems. Each time the human safety monitor disengages the robot's autonomy system due to the robot performing an undesirable maneuver, the autonomy developers gain insight into how to improve the autonomy system. However, we believe that these disengagements not only show where the system fails, which is useful for troubleshooting, but also provide a direct learning signal by which the robot can learn to navigate. We present a reinforcement learning approach for learning to navigate from disengagements, or LaND. LaND learns a neural network model that predicts which actions lead to disengagements given the current sensory observation, and then at test time plans and executes actions that avoid disengagements. Our results demonstrate LaND can successfully learn to navigate in diverse, real world sidewalk environments, outperforming both imitation learning and reinforcement learning approaches. Videos, code, and other material are available on our website https://sites.google.com/view/sidewalk-learning
Multi-agent Social Reinforcement Learning Improves Generalization
Oct 01, 2020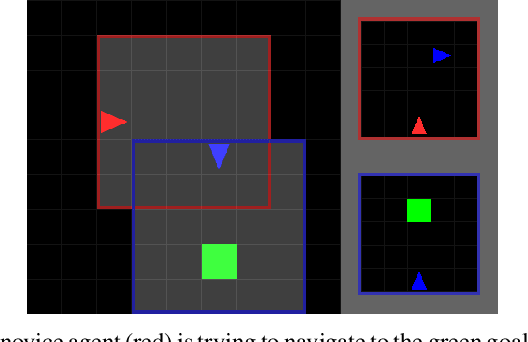
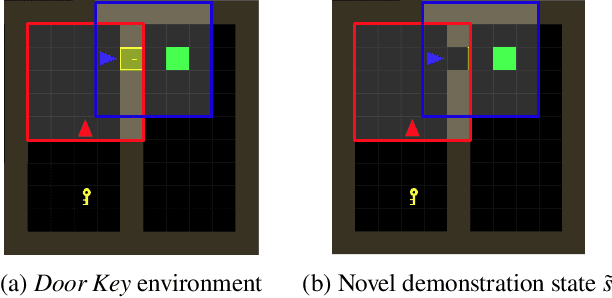
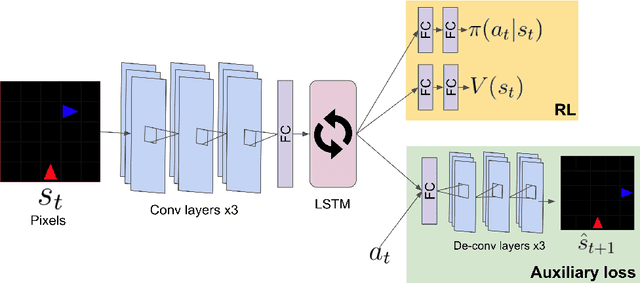
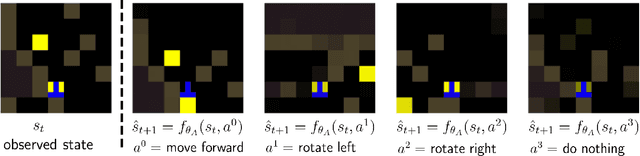
Social learning is a key component of human and animal intelligence. By taking cues from the behavior of experts in their environment, social learners can acquire sophisticated behavior and rapidly adapt to new circumstances. This paper investigates whether independent reinforcement learning (RL) agents in a multi-agent environment can use social learning to improve their performance using cues from other agents. We find that in most circumstances, vanilla model-free RL agents do not use social learning, even in environments in which individual exploration is expensive. We analyze the reasons for this deficiency, and show that by introducing a model-based auxiliary loss we are able to train agents to lever-age cues from experts to solve hard exploration tasks. The generalized social learning policy learned by these agents allows them to not only outperform the experts with which they trained, but also achieve better zero-shot transfer performance than solo learners when deployed to novel environments with experts. In contrast, agents that have not learned to rely on social learning generalize poorly and do not succeed in the transfer task. Further,we find that by mixing multi-agent and solo training, we can obtain agents that use social learning to out-perform agents trained alone, even when experts are not avail-able. This demonstrates that social learning has helped improve agents' representation of the task itself. Our results indicate that social learning can enable RL agents to not only improve performance on the task at hand, but improve generalization to novel environments.