 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
Learning Multimodal Behaviors from Scratch with Diffusion Policy Gradient
Jun 02, 2024



Deep reinforcement learning (RL) algorithms typically parameterize the policy as a deep network that outputs either a deterministic action or a stochastic one modeled as a Gaussian distribution, hence restricting learning to a single behavioral mode. Meanwhile, diffusion models emerged as a powerful framework for multimodal learning. However, the use of diffusion policies in online RL is hindered by the intractability of policy likelihood approximation, as well as the greedy objective of RL methods that can easily skew the policy to a single mode. This paper presents Deep Diffusion Policy Gradient (DDiffPG), a novel actor-critic algorithm that learns from scratch multimodal policies parameterized as diffusion models while discovering and maintaining versatile behaviors. DDiffPG explores and discovers multiple modes through off-the-shelf unsupervised clustering combined with novelty-based intrinsic motivation. DDiffPG forms a multimodal training batch and utilizes mode-specific Q-learning to mitigate the inherent greediness of the RL objective, ensuring the improvement of the diffusion policy across all modes. Our approach further allows the policy to be conditioned on mode-specific embeddings to explicitly control the learned modes. Empirical studies validate DDiffPG's capability to master multimodal behaviors in complex, high-dimensional continuous control tasks with sparse rewards, also showcasing proof-of-concept dynamic online replanning when navigating mazes with unseen obstacles.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Compositional Foundation Models for Hierarchical Planning
Sep 21, 2023



To make effective decisions in novel environments with long-horizon goals, it is crucial to engage in hierarchical reasoning across spatial and temporal scales. This entails planning abstract subgoal sequences, visually reasoning about the underlying plans, and executing actions in accordance with the devised plan through visual-motor control. We propose Compositional Foundation Models for Hierarchical Planning (HiP), a foundation model which leverages multiple expert foundation model trained on language, vision and action data individually jointly together to solve long-horizon tasks. We use a large language model to construct symbolic plans that are grounded in the environment through a large video diffusion model. Generated video plans are then grounded to visual-motor control, through an inverse dynamics model that infers actions from generated videos. To enable effective reasoning within this hierarchy, we enforce consistency between the models via iterative refinement. We illustrate the efficacy and adaptability of our approach in three different long-horizon table-top manipulation tasks.
Parallel $Q$-Learning: Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation
Jul 24, 2023Reinforcement learning is time-consuming for complex tasks due to the need for large amounts of training data. Recent advances in GPU-based simulation, such as Isaac Gym, have sped up data collection thousands of times on a commodity GPU. Most prior works used on-policy methods like PPO due to their simplicity and ease of scaling. Off-policy methods are more data efficient but challenging to scale, resulting in a longer wall-clock training time. This paper presents a Parallel $Q$-Learning (PQL) scheme that outperforms PPO in wall-clock time while maintaining superior sample efficiency of off-policy learning. PQL achieves this by parallelizing data collection, policy learning, and value learning. Different from prior works on distributed off-policy learning, such as Apex, our scheme is designed specifically for massively parallel GPU-based simulation and optimized to work on a single workstation. In experiments, we demonstrate that $Q$-learning can be scaled to \textit{tens of thousands of parallel environments} and investigate important factors affecting learning speed. The code is available at https://github.com/Improbable-AI/pql.
Statistical Learning under Heterogenous Distribution Shift
Feb 27, 2023



This paper studies the prediction of a target $\mathbf{z}$ from a pair of random variables $(\mathbf{x},\mathbf{y})$, where the ground-truth predictor is additive $\mathbb{E}[\mathbf{z} \mid \mathbf{x},\mathbf{y}] = f_\star(\mathbf{x}) +g_{\star}(\mathbf{y})$. We study the performance of empirical risk minimization (ERM) over functions $f+g$, $f \in \mathcal{F}$ and $g \in \mathcal{G}$, fit on a given training distribution, but evaluated on a test distribution which exhibits covariate shift. We show that, when the class $\mathcal{F}$ is "simpler" than $\mathcal{G}$ (measured, e.g., in terms of its metric entropy), our predictor is more resilient to \emph{heterogenous covariate shifts} in which the shift in $\mathbf{x}$ is much greater than that in $\mathbf{y}$. These results rely on a novel H\"older style inequality for the Dudley integral which may be of independent interest. Moreover, we corroborate our theoretical findings with experiments demonstrating improved resilience to shifts in "simpler" features across numerous domains.
Is Conditional Generative Modeling all you need for Decision-Making?
Dec 07, 2022



Recent improvements in conditional generative modeling have made it possible to generate high-quality images from language descriptions alone. We investigate whether these methods can directly address the problem of sequential decision-making. We view decision-making not through the lens of reinforcement learning (RL), but rather through conditional generative modeling. To our surprise, we find that our formulation leads to policies that can outperform existing offline RL approaches across standard benchmarks. By modeling a policy as a return-conditional diffusion model, we illustrate how we may circumvent the need for dynamic programming and subsequently eliminate many of the complexities that come with traditional offline RL. We further demonstrate the advantages of modeling policies as conditional diffusion models by considering two other conditioning variables: constraints and skills. Conditioning on a single constraint or skill during training leads to behaviors at test-time that can satisfy several constraints together or demonstrate a composition of skills. Our results illustrate that conditional generative modeling is a powerful tool for decision-making.
Distributionally Adaptive Meta Reinforcement Learning
Oct 06, 2022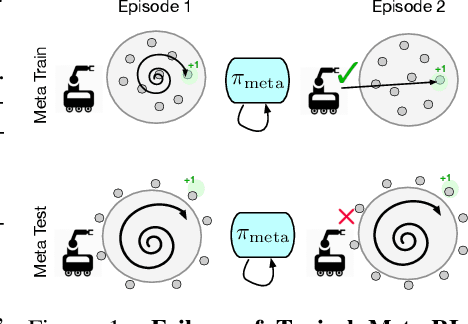

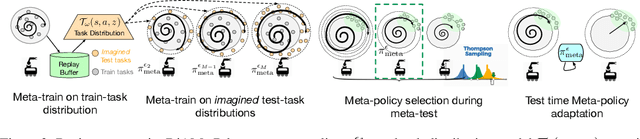
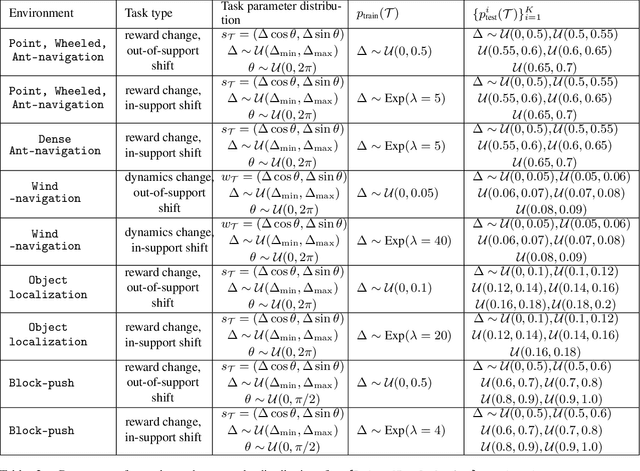
Meta-reinforcement learning algorithms provide a data-driven way to acquire policies that quickly adapt to many tasks with varying rewards or dynamics functions. However, learned meta-policies are often effective only on the exact task distribution on which they were trained and struggle in the presence of distribution shift of test-time rewards or transition dynamics. In this work, we develop a framework for meta-RL algorithms that are able to behave appropriately under test-time distribution shifts in the space of tasks. Our framework centers on an adaptive approach to distributional robustness that trains a population of meta-policies to be robust to varying levels of distribution shift. When evaluated on a potentially shifted test-time distribution of tasks, this allows us to choose the meta-policy with the most appropriate level of robustness, and use it to perform fast adaptation. We formally show how our framework allows for improved regret under distribution shift, and empirically show its efficacy on simulated robotics problems under a wide range of distribution shifts.
Offline RL Policies Should be Trained to be Adaptive
Jul 05, 2022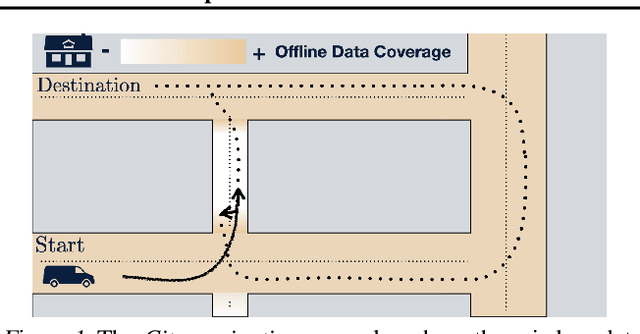
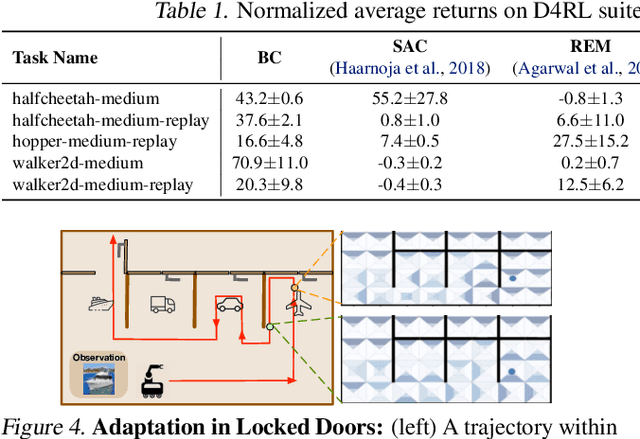
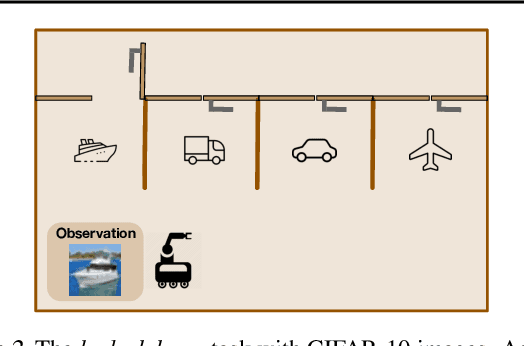
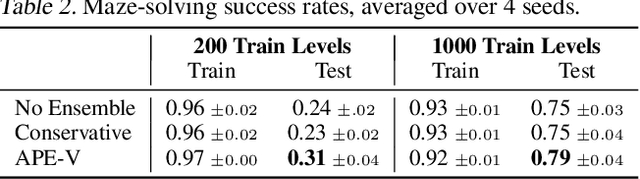
Offline RL algorithms must account for the fact that the dataset they are provided may leave many facets of the environment unknown. The most common way to approach this challenge is to employ pessimistic or conservative methods, which avoid behaviors that are too dissimilar from those in the training dataset. However, relying exclusively on conservatism has drawbacks: performance is sensitive to the exact degree of conservatism, and conservative objectives can recover highly suboptimal policies. In this work, we propose that offline RL methods should instead be adaptive in the presence of uncertainty. We show that acting optimally in offline RL in a Bayesian sense involves solving an implicit POMDP. As a result, optimal policies for offline RL must be adaptive, depending not just on the current state but rather all the transitions seen so far during evaluation.We present a model-free algorithm for approximating this optimal adaptive policy, and demonstrate the efficacy of learning such adaptive policies in offline RL benchmarks.
Overcoming the Spectral Bias of Neural Value Approximation
Jun 09, 2022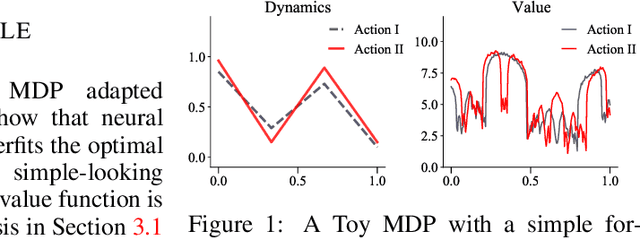

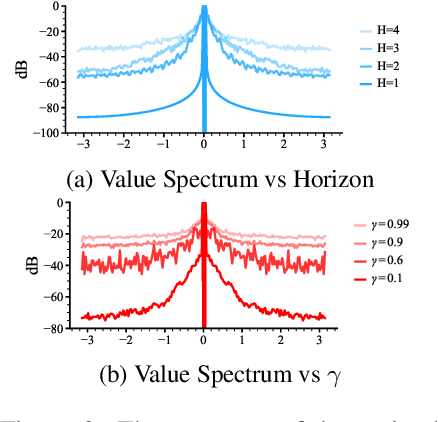
Value approximation using deep neural networks is at the heart of off-policy deep reinforcement learning, and is often the primary module that provides learning signals to the rest of the algorithm. While multi-layer perceptron networks are universal function approximators, recent works in neural kernel regression suggest the presence of a spectral bias, where fitting high-frequency components of the value function requires exponentially more gradient update steps than the low-frequency ones. In this work, we re-examine off-policy reinforcement learning through the lens of kernel regression and propose to overcome such bias via a composite neural tangent kernel. With just a single line-change, our approach, the Fourier feature networks (FFN) produce state-of-the-art performance on challenging continuous control domains with only a fraction of the compute. Faster convergence and better off-policy stability also make it possible to remove the target network without suffering catastrophic divergences, which further reduces TD}(0)'s estimation bias on a few tasks.