 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODE-CNN: Omnidirectional Depth Extension Networks
Jul 03, 2020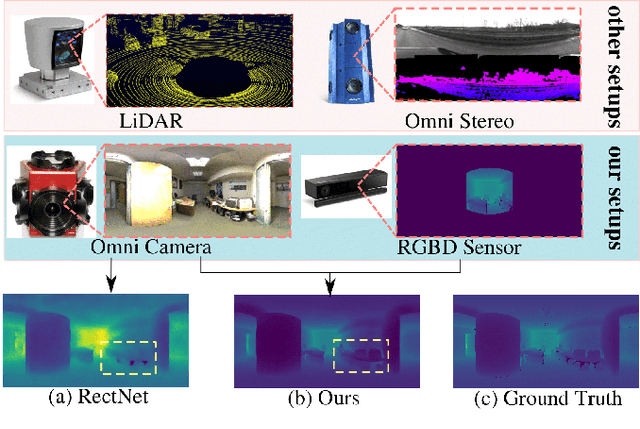
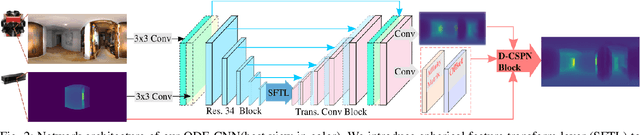
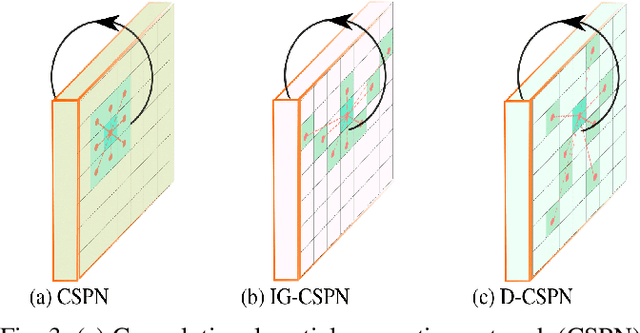

Omnidirectional 360{\deg} camera proliferates rapidly for autonomous robots since it significantly enhances the perception ability by widening the field of view(FoV). However, corresponding 360{\deg} depth sensors, which are also critical for the perception system, are still difficult or expensive to have. In this paper, we propose a low-cost 3D sensing system that combines an omnidirectional camera with a calibrated projective depth camera, where the depth from the limited FoV can be automatically extended to the rest of the recorded omnidirectional image. To accurately recover the missing depths, we design an omnidirectional depth extension convolutional neural network(ODE-CNN), in which a spherical feature transform layer(SFTL) is embedded at the end of feature encoding layers, and a deformable convolutional spatial propagation network(D-CSPN) is appended at the end of feature decoding layers. The former resamples the neighborhood of each pixel in the omnidirectional coordination to the projective coordination, which reduces the difficulty of feature learning, and the later automatically finds a proper context to well align the structures in the estimated depths via CNN w.r.t. the reference image, which significantly improves the visual quality. Finally, we demonstrate the effectiveness of proposed ODE-CNN over the popular 360D dataset and show that ODE-CNN significantly outperforms (relatively 33% reduction in-depth error) other state-of-the-art (SoTA) methods.
SparseFusion: Dynamic Human Avatar Modeling from Sparse RGBD Images
Jun 05, 2020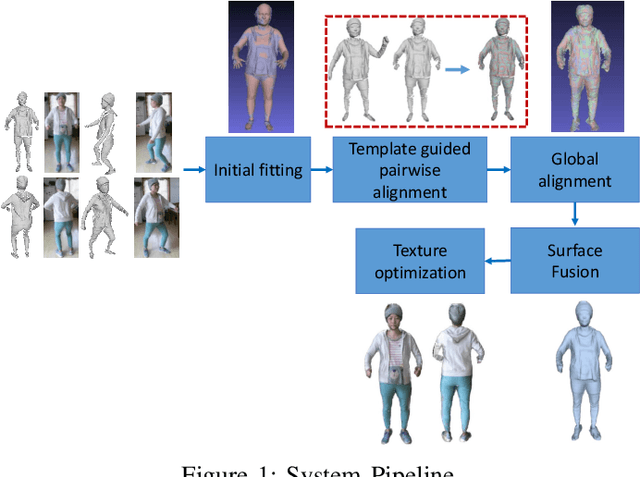

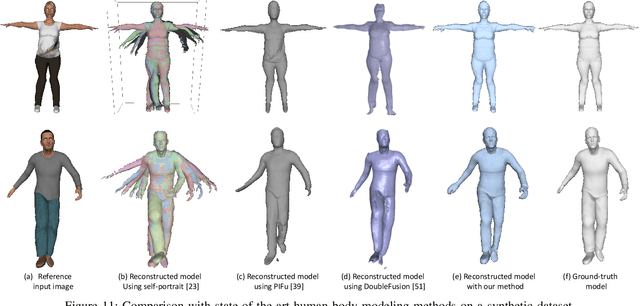
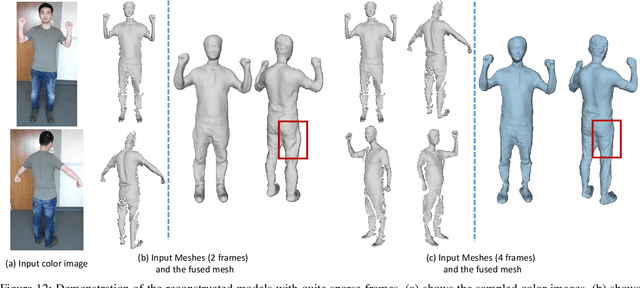
In this paper, we propose a novel approach to reconstruct 3D human body shapes based on a sparse set of RGBD frames using a single RGBD camera. We specifically focus on the realistic settings where human subjects move freely during the capture. The main challenge is how to robustly fuse these sparse frames into a canonical 3D model, under pose changes and surface occlusions. This is addressed by our new framework consisting of the following steps. First, based on a generative human template, for every two frames having sufficient overlap, an initial pairwise alignment is performed; It is followed by a global non-rigid registration procedure, in which partial results from RGBD frames are collected into a unified 3D shape, under the guidance of correspondences from the pairwise alignment; Finally, the texture map of the reconstructed human model is optimized to deliver a clear and spatially consistent texture. Empirical evaluations on synthetic and real datasets demonstrate both quantitatively and qualitatively the superior performance of our framework in reconstructing complete 3D human models with high fidelity. It is worth noting that our framework is flexible, with potential applications going beyond shape reconstruction. As an example, we showcase its use in reshaping and reposing to a new avatar.
Channel Attention based Iterative Residual Learning for Depth Map Super-Resolution
Jun 02, 2020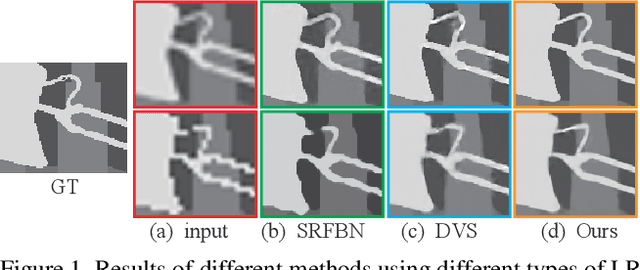
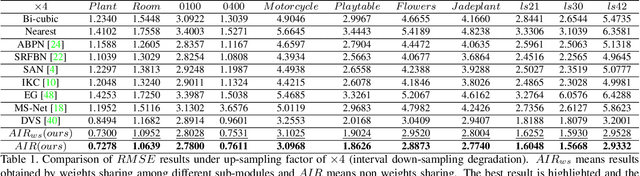
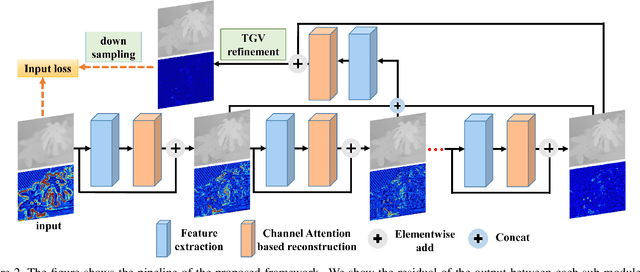
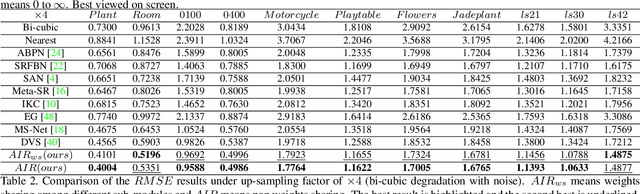
Despite the remarkable progresses made in deep-learning based depth map super-resolution (DSR), how to tackle real-world degradation in low-resolution (LR) depth maps remains a major challenge. Existing DSR model is generally trained and tested on synthetic dataset, which is very different from what would get from a real depth sensor. In this paper, we argue that DSR models trained under this setting are restrictive and not effective in dealing with real-world DSR tasks. We make two contributions in tackling real-world degradation of different depth sensors. First, we propose to classify the generation of LR depth maps into two types: non-linear downsampling with noise and interval downsampling, for which DSR models are learned correspondingly. Second, we propose a new framework for real-world DSR, which consists of four modules : 1) An iterative residual learning module with deep supervision to learn effective high-frequency components of depth maps in a coarse-to-fine manner; 2) A channel attention strategy to enhance channels with abundant high-frequency components; 3) A multi-stage fusion module to effectively re-exploit the results in the coarse-to-fine process; and 4) A depth refinement module to improve the depth map by TGV regularization and input loss. Extensive experiments on benchmarking datasets demonstrate the superiority of our method over current state-of-the-art DSR methods.
FaceScape: a Large-scale High Quality 3D Face Dataset and Detailed Riggable 3D Face Prediction
Apr 21, 2020
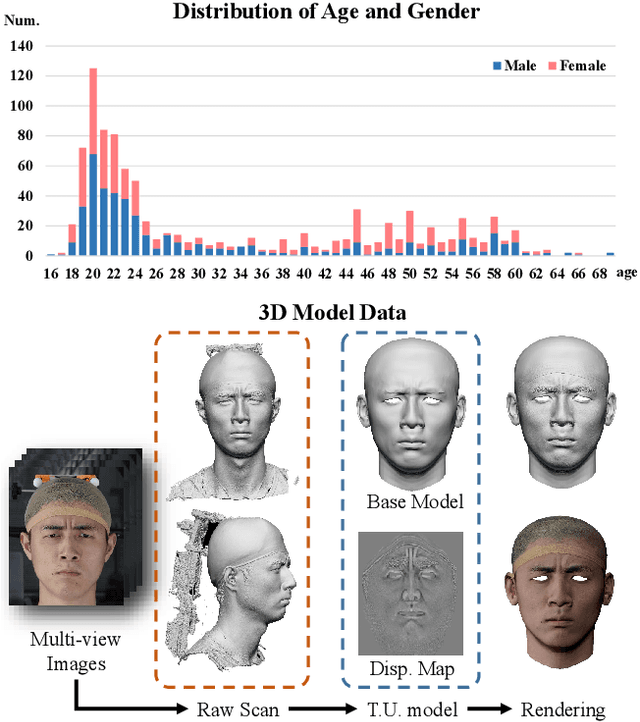
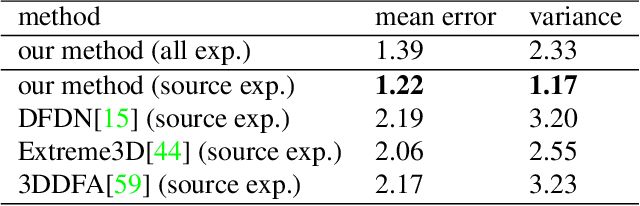
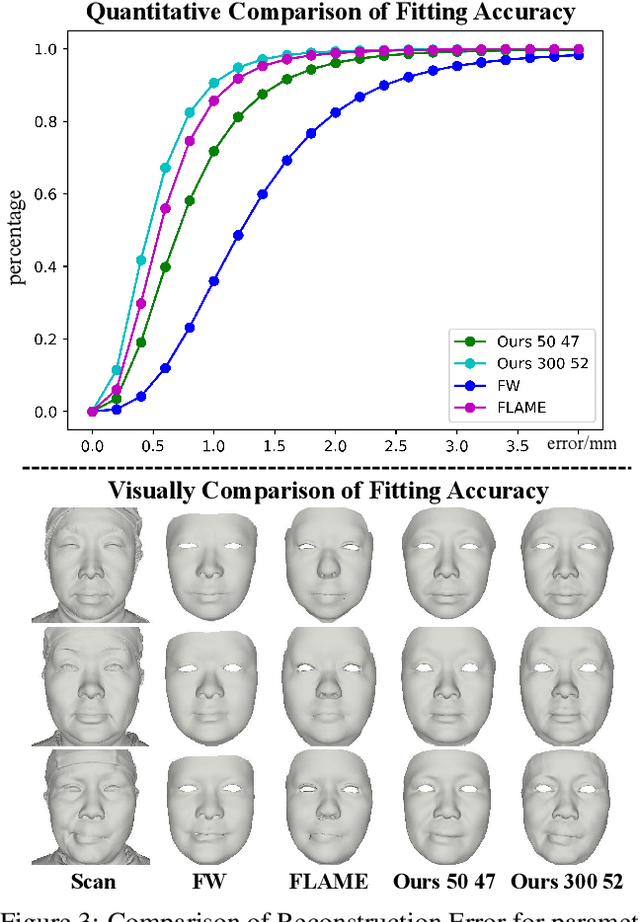
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and propose a novel algorithm that is able to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. The unprecedented dataset and code will be released to public for research purpose.
CVPR 2019 WAD Challenge on Trajectory Prediction and 3D Perception
Apr 06, 2020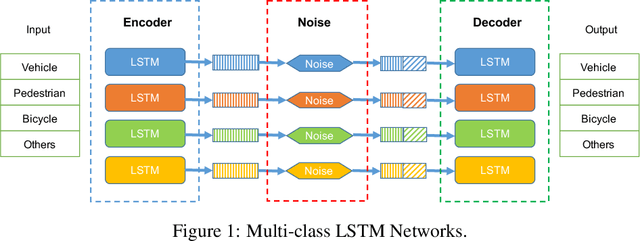

This paper reviews the CVPR 2019 challenge on Autonomous Driving. Baidu's Robotics and Autonomous Driving Lab (RAL) providing 150 minutes labeled Trajectory and 3D Perception dataset including about 80k lidar point cloud and 1000km trajectories for urban traffic. The challenge has two tasks in (1) Trajectory Prediction and (2) 3D Lidar Object Detection. There are more than 200 teams submitted results on Leaderboard and more than 1000 participants attended the workshop.
LiDAR-based Online 3D Video Object Detection with Graph-based Message Passing and Spatiotemporal Transformer Attention
Apr 03, 2020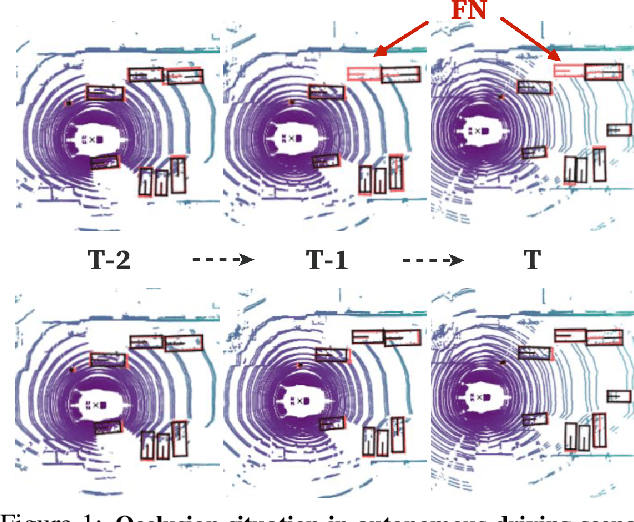
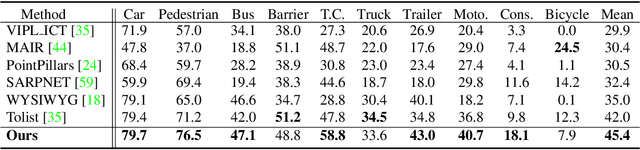
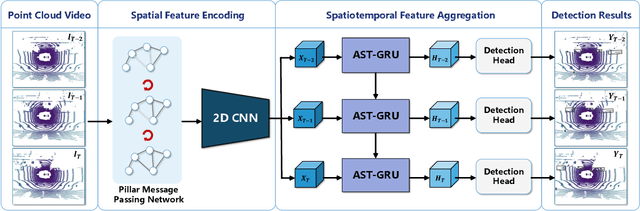
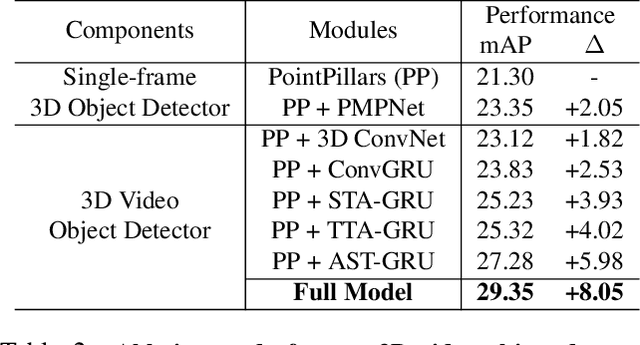
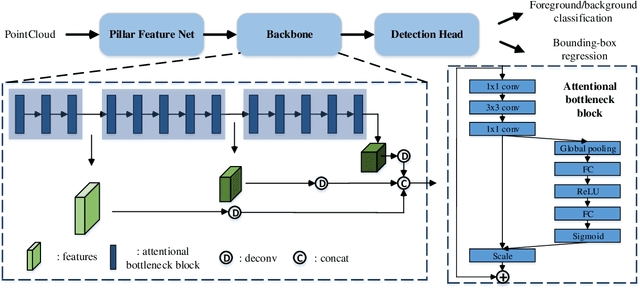
Existing LiDAR-based 3D object detectors usually focus on the single-frame detection, while ignoring the spatiotemporal information in consecutive point cloud frames. In this paper, we propose an end-to-end online 3D video object detector that operates on point cloud sequences. The proposed model comprises a spatial feature encoding component and a spatiotemporal feature aggregation component. In the former component, a novel Pillar Message Passing Network (PMPNet) is proposed to encode each discrete point cloud frame. It adaptively collects information for a pillar node from its neighbors by iterative message passing, which effectively enlarges the receptive field of the pillar feature. In the latter component, we propose an Attentive Spatiotemporal Transformer GRU (AST-GRU) to aggregate the spatiotemporal information, which enhances the conventional ConvGRU with an attentive memory gating mechanism. AST-GRU contains a Spatial Transformer Attention (STA) module and a Temporal Transformer Attention (TTA) module, which can emphasize the foreground objects and align the dynamic objects, respectively. Experimental results demonstrate that the proposed 3D video object detector achieves state-of-the-art performance on the large-scale nuScenes benchmark.
A Unified Object Motion and Affinity Model for Online Multi-Object Tracking
Apr 03, 2020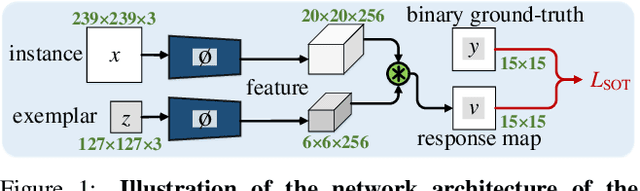
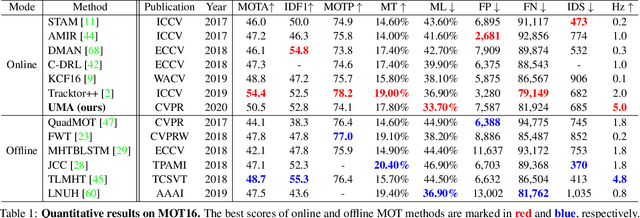
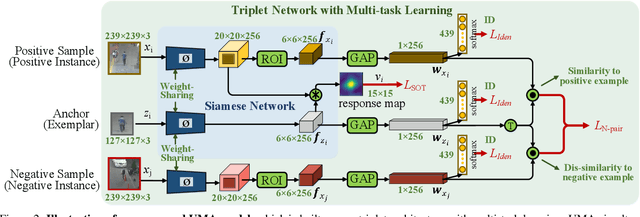
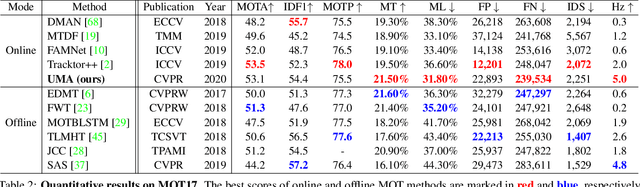
Current popular online multi-object tracking (MOT) solutions apply single object trackers (SOTs) to capture object motions, while often requiring an extra affinity network to associate objects, especially for the occluded ones. This brings extra computational overhead due to repetitive feature extraction for SOT and affinity computation. Meanwhile, the model size of the sophisticated affinity network is usually non-trivial. In this paper, we propose a novel MOT framework that unifies object motion and affinity model into a single network, named UMA, in order to learn a compact feature that is discriminative for both object motion and affinity measure. In particular, UMA integrates single object tracking and metric learning into a unified triplet network by means of multi-task learning. Such design brings advantages of improved computation efficiency, low memory requirement and simplified training procedure. In addition, we equip our model with a task-specific attention module, which is used to boost task-aware feature learning. The proposed UMA can be easily trained end-to-end, and is elegant - requiring only one training stage. Experimental results show that it achieves promising performance on several MOT Challenge benchmarks.
Learning 2D-3D Correspondences To Solve The Blind Perspective-n-Point Problem
Mar 15, 2020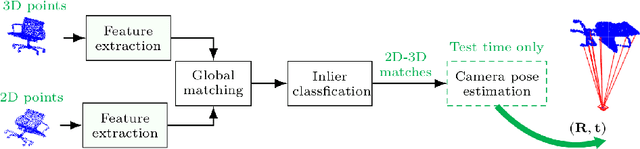

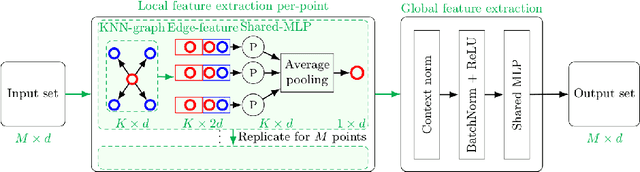

Conventional absolute camera pose via a Perspective-n-Point (PnP) solver often assumes that the correspondences between 2D image pixels and 3D points are given. When the correspondences between 2D and 3D points are not known a priori, the task becomes the much more challenging blind PnP problem. This paper proposes a deep CNN model which simultaneously solves for both the 6-DoF absolute camera pose and 2D--3D correspondences. Our model comprises three neural modules connected in sequence. First, a two-stream PointNet-inspired network is applied directly to both the 2D image keypoints and the 3D scene points in order to extract discriminative point-wise features harnessing both local and contextual information. Second, a global feature matching module is employed to estimate a matchability matrix among all 2D--3D pairs. Third, the obtained matchability matrix is fed into a classification module to disambiguate inlier matches. The entire network is trained end-to-end, followed by a robust model fitting (P3P-RANSAC) at test time only to recover the 6-DoF camera pose. Extensive tests on both real and simulated data have shown that our method substantially outperforms existing approaches, and is capable of processing thousands of points a second with the state-of-the-art accuracy.
Gated Path Selection Network for Semantic Segmentation
Jan 19, 2020
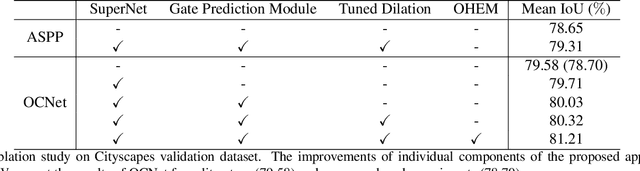
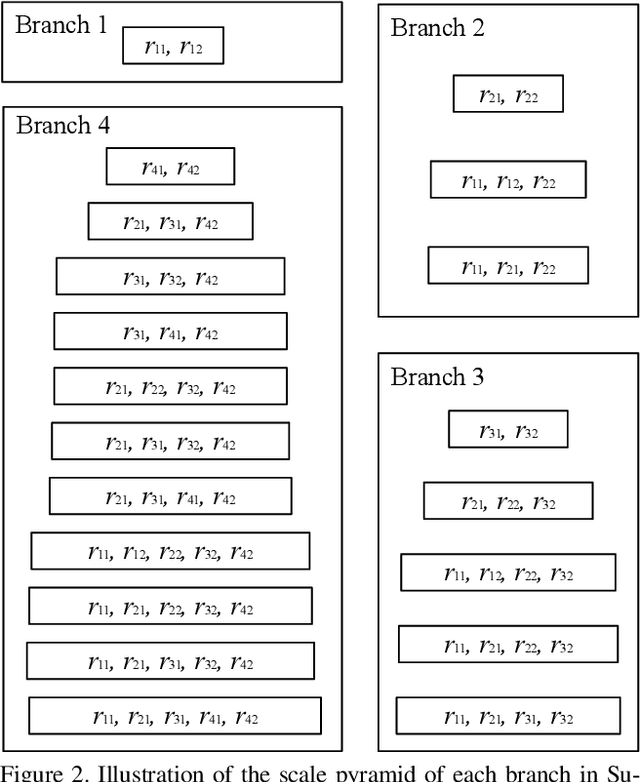
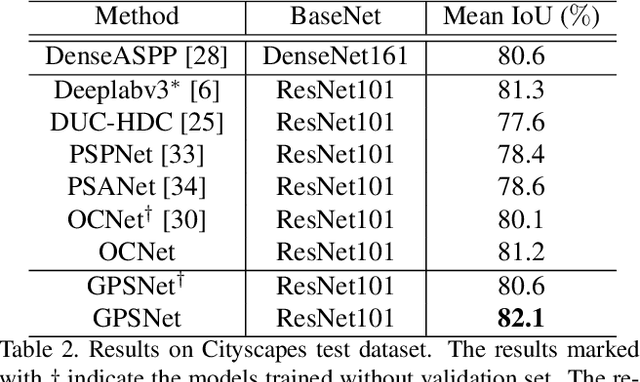
Semantic segmentation is a challenging task that needs to handle large scale variations, deformations and different viewpoints. In this paper, we develop a novel network named Gated Path Selection Network (GPSNet), which aims to learn adaptive receptive fields. In GPSNet, we first design a two-dimensional multi-scale network - SuperNet, which densely incorporates features from growing receptive fields. To dynamically select desirable semantic context, a gate prediction module is further introduced. In contrast to previous works that focus on optimizing sample positions on the regular grids, GPSNet can adaptively capture free form dense semantic contexts. The derived adaptive receptive fields are data-dependent, and are flexible that can model different object geometric transformations. On two representative semantic segmentation datasets, i.e., Cityscapes, and ADE20K, we show that the proposed approach consistently outperforms previous methods and achieves competitive performance without bells and whistles.
Domain-invariant Stereo Matching Networks
Nov 29, 2019
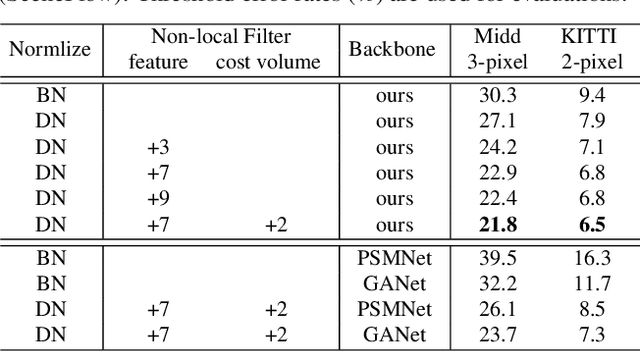
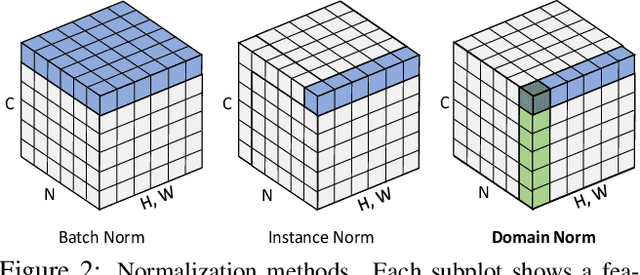
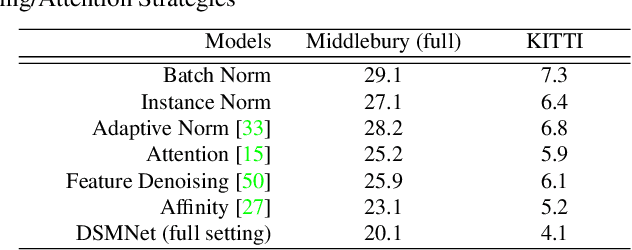
State-of-the-art stereo matching networks have difficulties in generalizing to new unseen environments due to significant domain differences, such as color, illumination, contrast, and texture. In this paper, we aim at designing a domain-invariant stereo matching network (DSMNet) that generalizes well to unseen scenes. To achieve this goal, we propose i) a novel "domain normalization" approach that regularizes the distribution of learned representations to allow them to be invariant to domain differences, and ii) a trainable non-local graph-based filter for extracting robust structural and geometric representations that can further enhance domain-invariant generalizations. When trained on synthetic data and generalized to real test sets, our model performs significantly better than all state-of-the-art models. It even outperforms some deep learning models (e.g. MC-CNN) fine-tuned with test-domain data.