 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Manipulation via Imitation Learning: Taxonomy, Evolution, Benchmark, and Challenges
Aug 24, 2025



Robotic Manipulation (RM) is central to the advancement of autonomous robots, enabling them to interact with and manipulate objects in real-world environments. This survey focuses on RM methodologies that leverage imitation learning, a powerful technique that allows robots to learn complex manipulation skills by mimicking human demonstrations. We identify and analyze the most influential studies in this domain, selected based on community impact and intrinsic quality. For each paper, we provide a structured summary, covering the research purpose, technical implementation, hierarchical classification, input formats, key priors, strengths and limitations, and citation metrics. Additionally, we trace the chronological development of imitation learning techniques within RM policy (RMP), offering a timeline of key technological advancements. Where available, we report benchmark results and perform quantitative evaluations to compare existing methods. By synthesizing these insights, this review provides a comprehensive resource for researchers and practitioners, highlighting both the state of the art and the challenges that lie ahead in the field of robotic manipulation through imitation learning.
ADPro: a Test-time Adaptive Diffusion Policy for Robot Manipulation via Manifold and Initial Noise Constraints
Aug 08, 2025Diffusion policies have recently emerged as a powerful class of visuomotor controllers for robot manipulation, offering stable training and expressive multi-modal action modeling. However, existing approaches typically treat action generation as an unconstrained denoising process, ignoring valuable a priori knowledge about geometry and control structure. In this work, we propose the Adaptive Diffusion Policy (ADP), a test-time adaptation method that introduces two key inductive biases into the diffusion. First, we embed a geometric manifold constraint that aligns denoising updates with task-relevant subspaces, leveraging the fact that the relative pose between the end-effector and target scene provides a natural gradient direction, and guiding denoising along the geodesic path of the manipulation manifold. Then, to reduce unnecessary exploration and accelerate convergence, we propose an analytically guided initialization: rather than sampling from an uninformative prior, we compute a rough registration between the gripper and target scenes to propose a structured initial noisy action. ADP is compatible with pre-trained diffusion policies and requires no retraining, enabling test-time adaptation that tailors the policy to specific tasks, thereby enhancing generalization across novel tasks and environments. Experiments on RLBench, CALVIN, and real-world dataset show that ADPro, an implementation of ADP, improves success rates, generalization, and sampling efficiency, achieving up to 25% faster execution and 9% points over strong diffusion baselines.
Speech Quality Assessment Model Based on Mixture of Experts: System-Level Performance Enhancement and Utterance-Level Challenge Analysis
Jul 08, 2025Automatic speech quality assessment plays a crucial role in the development of speech synthesis systems, but existing models exhibit significant performance variations across different granularity levels of prediction tasks. This paper proposes an enhanced MOS prediction system based on self-supervised learning speech models, incorporating a Mixture of Experts (MoE) classification head and utilizing synthetic data from multiple commercial generation models for data augmentation. Our method builds upon existing self-supervised models such as wav2vec2, designing a specialized MoE architecture to address different types of speech quality assessment tasks. We also collected a large-scale synthetic speech dataset encompassing the latest text-to-speech, speech conversion, and speech enhancement systems. However, despite the adoption of the MoE architecture and expanded dataset, the model's performance improvements in sentence-level prediction tasks remain limited. Our work reveals the limitations of current methods in handling sentence-level quality assessment, provides new technical pathways for the field of automatic speech quality assessment, and also delves into the fundamental causes of performance differences across different assessment granularities.
From High-SNR Radar Signal to ECG: A Transfer Learning Model with Cardio-Focusing Algorithm for Scenarios with Limited Data
Jun 24, 2025Electrocardiogram (ECG), as a crucial find-grained cardiac feature, has been successfully recovered from radar signals in the literature, but the performance heavily relies on the high-quality radar signal and numerous radar-ECG pairs for training, restricting the applications in new scenarios due to data scarcity. Therefore, this work will focus on radar-based ECG recovery in new scenarios with limited data and propose a cardio-focusing and -tracking (CFT) algorithm to precisely track the cardiac location to ensure an efficient acquisition of high-quality radar signals. Furthermore, a transfer learning model (RFcardi) is proposed to extract cardio-related information from the radar signal without ECG ground truth based on the intrinsic sparsity of cardiac features, and only a few synchronous radar-ECG pairs are required to fine-tune the pre-trained model for the ECG recovery. The experimental results reveal that the proposed CFT can dynamically identify the cardiac location, and the RFcardi model can effectively generate faithful ECG recoveries after using a small number of radar-ECG pairs for training. The code and dataset are available after the publication.
LoRA-Gen: Specializing Large Language Model via Online LoRA Generation
Jun 13, 2025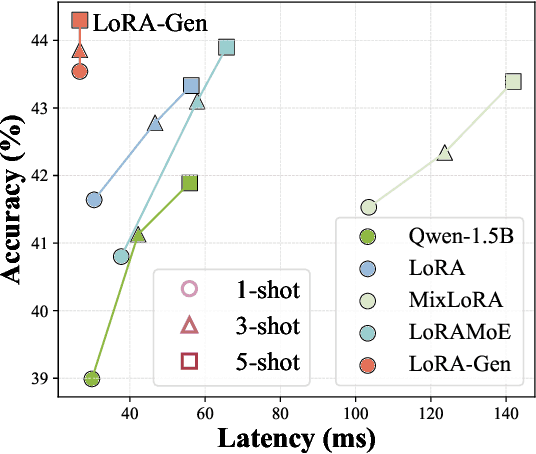

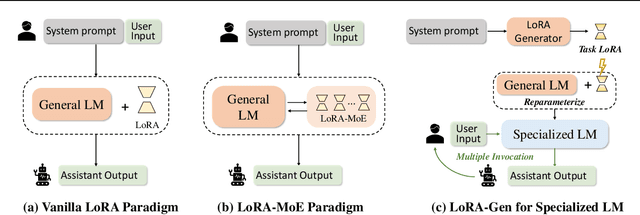
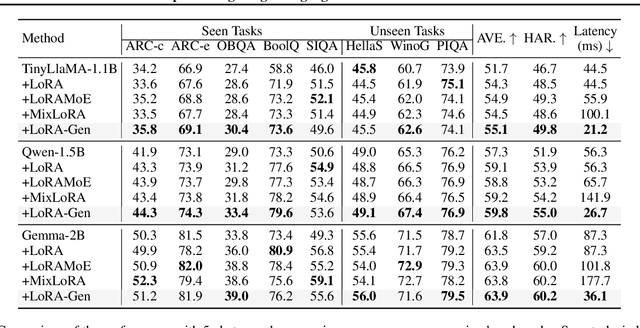
Recent advances have highlighted the benefits of scaling language models to enhance performance across a wide range of NLP tasks. However, these approaches still face limitations in effectiveness and efficiency when applied to domain-specific tasks, particularly for small edge-side models. We propose the LoRA-Gen framework, which utilizes a large cloud-side model to generate LoRA parameters for edge-side models based on task descriptions. By employing the reparameterization technique, we merge the LoRA parameters into the edge-side model to achieve flexible specialization. Our method facilitates knowledge transfer between models while significantly improving the inference efficiency of the specialized model by reducing the input context length. Without specialized training, LoRA-Gen outperforms conventional LoRA fine-tuning, which achieves competitive accuracy and a 2.1x speedup with TinyLLaMA-1.1B in reasoning tasks. Besides, our method delivers a compression ratio of 10.1x with Gemma-2B on intelligent agent tasks.
MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning
May 30, 2025Reward modeling is a key step in building safe foundation models when applying reinforcement learning from human feedback (RLHF) to align Large Language Models (LLMs). However, reward modeling based on the Bradley-Terry (BT) model assumes a global reward function, failing to capture the inherently diverse and heterogeneous human preferences. Hence, such oversimplification limits LLMs from supporting personalization and pluralistic alignment. Theoretically, we show that when human preferences follow a mixture distribution of diverse subgroups, a single BT model has an irreducible error. While existing solutions, such as multi-objective learning with fine-grained annotations, help address this issue, they are costly and constrained by predefined attributes, failing to fully capture the richness of human values. In this work, we introduce MiCRo, a two-stage framework that enhances personalized preference learning by leveraging large-scale binary preference datasets without requiring explicit fine-grained annotations. In the first stage, MiCRo introduces context-aware mixture modeling approach to capture diverse human preferences. In the second stage, MiCRo integrates an online routing strategy that dynamically adapts mixture weights based on specific context to resolve ambiguity, allowing for efficient and scalable preference adaptation with minimal additional supervision. Experiments on multiple preference datasets demonstrate that MiCRo effectively captures diverse human preferences and significantly improves downstream personalization.
Mixed-R1: Unified Reward Perspective For Reasoning Capability in Multimodal Large Language Models
May 30, 2025



Recent works on large language models (LLMs) have successfully demonstrated the emergence of reasoning capabilities via reinforcement learning (RL). Although recent efforts leverage group relative policy optimization (GRPO) for MLLMs post-training, they constantly explore one specific aspect, such as grounding tasks, math problems, or chart analysis. There are no works that can leverage multi-source MLLM tasks for stable reinforcement learning. In this work, we present a unified perspective to solve this problem. We present Mixed-R1, a unified yet straightforward framework that contains a mixed reward function design (Mixed-Reward) and a mixed post-training dataset (Mixed-45K). We first design a data engine to select high-quality examples to build the Mixed-45K post-training dataset. Then, we present a Mixed-Reward design, which contains various reward functions for various MLLM tasks. In particular, it has four different reward functions: matching reward for binary answer or multiple-choice problems, chart reward for chart-aware datasets, IoU reward for grounding problems, and open-ended reward for long-form text responses such as caption datasets. To handle the various long-form text content, we propose a new open-ended reward named Bidirectional Max-Average Similarity (BMAS) by leveraging tokenizer embedding matching between the generated response and the ground truth. Extensive experiments show the effectiveness of our proposed method on various MLLMs, including Qwen2.5-VL and Intern-VL on various sizes. Our dataset and model are available at https://github.com/xushilin1/mixed-r1.
ADG: Ambient Diffusion-Guided Dataset Recovery for Corruption-Robust Offline Reinforcement Learning
May 29, 2025Real-world datasets collected from sensors or human inputs are prone to noise and errors, posing significant challenges for applying offline reinforcement learning (RL). While existing methods have made progress in addressing corrupted actions and rewards, they remain insufficient for handling corruption in high-dimensional state spaces and for cases where multiple elements in the dataset are corrupted simultaneously. Diffusion models, known for their strong denoising capabilities, offer a promising direction for this problem-but their tendency to overfit noisy samples limits their direct applicability. To overcome this, we propose Ambient Diffusion-Guided Dataset Recovery (ADG), a novel approach that pioneers the use of diffusion models to tackle data corruption in offline RL. First, we introduce Ambient Denoising Diffusion Probabilistic Models (DDPM) from approximated distributions, which enable learning on partially corrupted datasets with theoretical guarantees. Second, we use the noise-prediction property of Ambient DDPM to distinguish between clean and corrupted data, and then use the clean subset to train a standard DDPM. Third, we employ the trained standard DDPM to refine the previously identified corrupted data, enhancing data quality for subsequent offline RL training. A notable strength of ADG is its versatility-it can be seamlessly integrated with any offline RL algorithm. Experiments on a range of benchmarks, including MuJoCo, Kitchen, and Adroit, demonstrate that ADG effectively mitigates the impact of corrupted data and improves the robustness of offline RL under various noise settings, achieving state-of-the-art results.
Benchmarking Multimodal Knowledge Conflict for Large Multimodal Models
May 26, 2025Large Multimodal Models(LMMs) face notable challenges when encountering multimodal knowledge conflicts, particularly under retrieval-augmented generation(RAG) frameworks where the contextual information from external sources may contradict the model's internal parametric knowledge, leading to unreliable outputs. However, existing benchmarks fail to reflect such realistic conflict scenarios. Most focus solely on intra-memory conflicts, while context-memory and inter-context conflicts remain largely investigated. Furthermore, commonly used factual knowledge-based evaluations are often overlooked, and existing datasets lack a thorough investigation into conflict detection capabilities. To bridge this gap, we propose MMKC-Bench, a benchmark designed to evaluate factual knowledge conflicts in both context-memory and inter-context scenarios. MMKC-Bench encompasses three types of multimodal knowledge conflicts and includes 1,573 knowledge instances and 3,381 images across 23 broad types, collected through automated pipelines with human verification. We evaluate three representative series of LMMs on both model behavior analysis and conflict detection tasks. Our findings show that while current LMMs are capable of recognizing knowledge conflicts, they tend to favor internal parametric knowledge over external evidence. We hope MMKC-Bench will foster further research in multimodal knowledge conflict and enhance the development of multimodal RAG systems. The source code is available at https://github.com/MLLMKCBENCH/MLLMKC.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.