 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-NERF: Representing Scene Changes as Directional Consistency Difference-based NeRF
Dec 23, 2023In this work, we aim to detect the changes caused by object variations in a scene represented by the neural radiance fields (NeRFs). Given an arbitrary view and two sets of scene images captured at different timestamps, we can predict the scene changes in that view, which has significant potential applications in scene monitoring and measuring. We conducted preliminary studies and found that such an exciting task cannot be easily achieved by utilizing existing NeRFs and 2D change detection methods with many false or missing detections. The main reason is that the 2D change detection is based on the pixel appearance difference between spatial-aligned image pairs and neglects the stereo information in the NeRF. To address the limitations, we propose the C-NERF to represent scene changes as directional consistency difference-based NeRF, which mainly contains three modules. We first perform the spatial alignment of two NeRFs captured before and after changes. Then, we identify the change points based on the direction-consistent constraint; that is, real change points have similar change representations across view directions, but fake change points do not. Finally, we design the change map rendering process based on the built NeRFs and can generate the change map of an arbitrarily specified view direction. To validate the effectiveness, we build a new dataset containing ten scenes covering diverse scenarios with different changing objects. Our approach surpasses state-of-the-art 2D change detection and NeRF-based methods by a significant margin.
SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
Dec 11, 2023



Current instruction-based editing methods, such as InstructPix2Pix, often fail to produce satisfactory results in complex scenarios due to their dependence on the simple CLIP text encoder in diffusion models. To rectify this, this paper introduces SmartEdit, a novel approach to instruction-based image editing that leverages Multimodal Large Language Models (MLLMs) to enhance their understanding and reasoning capabilities. However, direct integration of these elements still faces challenges in situations requiring complex reasoning. To mitigate this, we propose a Bidirectional Interaction Module that enables comprehensive bidirectional information interactions between the input image and the MLLM output. During training, we initially incorporate perception data to boost the perception and understanding capabilities of diffusion models. Subsequently, we demonstrate that a small amount of complex instruction editing data can effectively stimulate SmartEdit's editing capabilities for more complex instructions. We further construct a new evaluation dataset, Reason-Edit, specifically tailored for complex instruction-based image editing. Both quantitative and qualitative results on this evaluation dataset indicate that our SmartEdit surpasses previous methods, paving the way for the practical application of complex instruction-based image editing.
Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models
Jun 13, 2023



Large Language Models (LLMs), with their remarkable task-handling capabilities and innovative outputs, have catalyzed significant advancements across a spectrum of fields. However, their proficiency within specialized domains such as biomolecular studies remains limited. To address this challenge, we introduce Mol-Instructions, a meticulously curated, comprehensive instruction dataset expressly designed for the biomolecular realm. Mol-Instructions is composed of three pivotal components: molecule-oriented instructions, protein-oriented instructions, and biomolecular text instructions, each curated to enhance the understanding and prediction capabilities of LLMs concerning biomolecular features and behaviors. Through extensive instruction tuning experiments on the representative LLM, we underscore the potency of Mol-Instructions to enhance the adaptability and cognitive acuity of large models within the complex sphere of biomolecular studies, thereby promoting advancements in the biomolecular research community. Mol-Instructions is made publicly accessible for future research endeavors and will be subjected to continual updates for enhanced applicability.
Producing Usable Taxonomies Cheaply and Rapidly at Pinterest Using Discovered Dynamic $μ$-Topics
Jan 29, 2023
Creating a taxonomy of interests is expensive and human-effort intensive: not only do we need to identify nodes and interconnect them, in order to use the taxonomy, we must also connect the nodes to relevant entities such as users, pins, and queries. Connecting to entities is challenging because of ambiguities inherent to language but also because individual interests are dynamic and evolve. Here, we offer an alternative approach that begins with bottom-up discovery of $\mu$-topics called pincepts. The discovery process itself connects these $\mu$-topics dynamically with relevant queries, pins, and users at high precision, automatically adapting to shifting interests. Pincepts cover all areas of user interest and automatically adjust to the specificity of user interests and are thus suitable for the creation of various kinds of taxonomies. Human experts associate taxonomy nodes with $\mu$-topics (on average, 3 $\mu$-topics per node), and the $\mu$-topics offer a high-level data layer that allows quick definition, immediate inspection, and easy modification. Even more powerfully, $\mu$-topics allow easy exploration of nearby semantic space, enabling curators to spot and fill gaps. Curators' domain knowledge is heavily leveraged and we thus don't need untrained mechanical Turks, allowing further cost reduction. These $\mu$-topics thus offer a satisfactory "symbolic" stratum over which to define taxonomies. We have successfully applied this technique for very rapidly iterating on and launching the home decor and fashion styles taxonomy for style-based personalization, prominently featured at the top of Pinterest search results, at 94% precision, improving search success rate by 34.8% as well as boosting long clicks and pin saves.
Joint Representation Learning for Text and 3D Point Cloud
Jan 18, 2023



Recent advancements in vision-language pre-training (e.g. CLIP) have shown that vision models can benefit from language supervision. While many models using language modality have achieved great success on 2D vision tasks, the joint representation learning of 3D point cloud with text remains under-explored due to the difficulty of 3D-Text data pair acquisition and the irregularity of 3D data structure. In this paper, we propose a novel Text4Point framework to construct language-guided 3D point cloud models. The key idea is utilizing 2D images as a bridge to connect the point cloud and the language modalities. The proposed Text4Point follows the pre-training and fine-tuning paradigm. During the pre-training stage, we establish the correspondence of images and point clouds based on the readily available RGB-D data and use contrastive learning to align the image and point cloud representations. Together with the well-aligned image and text features achieved by CLIP, the point cloud features are implicitly aligned with the text embeddings. Further, we propose a Text Querying Module to integrate language information into 3D representation learning by querying text embeddings with point cloud features. For fine-tuning, the model learns task-specific 3D representations under informative language guidance from the label set without 2D images. Extensive experiments demonstrate that our model shows consistent improvement on various downstream tasks, such as point cloud semantic segmentation, instance segmentation, and object detection. The code will be available here: https://github.com/LeapLabTHU/Text4Point
Background-Mixed Augmentation for Weakly Supervised Change Detection
Dec 01, 2022Change detection (CD) is to decouple object changes (i.e., object missing or appearing) from background changes (i.e., environment variations) like light and season variations in two images captured in the same scene over a long time span, presenting critical applications in disaster management, urban development, etc. In particular, the endless patterns of background changes require detectors to have a high generalization against unseen environment variations, making this task significantly challenging. Recent deep learning-based methods develop novel network architectures or optimization strategies with paired-training examples, which do not handle the generalization issue explicitly and require huge manual pixel-level annotation efforts. In this work, for the first attempt in the CD community, we study the generalization issue of CD from the perspective of data augmentation and develop a novel weakly supervised training algorithm that only needs image-level labels. Different from general augmentation techniques for classification, we propose the background-mixed augmentation that is specifically designed for change detection by augmenting examples under the guidance of a set of background-changing images and letting deep CD models see diverse environment variations. Moreover, we propose the augmented & real data consistency loss that encourages the generalization increase significantly. Our method as a general framework can enhance a wide range of existing deep learning-based detectors. We conduct extensive experiments in two public datasets and enhance four state-of-the-art methods, demonstrating the advantages of our method. We release the code at https://github.com/tsingqguo/bgmix.
A Faster, Lighter and Stronger Deep Learning-Based Approach for Place Recognition
Nov 27, 2022



Visual Place Recognition is an essential component of systems for camera localization and loop closure detection, and it has attracted widespread interest in multiple domains such as computer vision, robotics and AR/VR. In this work, we propose a faster, lighter and stronger approach that can generate models with fewer parameters and can spend less time in the inference stage. We designed RepVGG-lite as the backbone network in our architecture, it is more discriminative than other general networks in the Place Recognition task. RepVGG-lite has more speed advantages while achieving higher performance. We extract only one scale patch-level descriptors from global descriptors in the feature extraction stage. Then we design a trainable feature matcher to exploit both spatial relationships of the features and their visual appearance, which is based on the attention mechanism. Comprehensive experiments on challenging benchmark datasets demonstrate the proposed method outperforming recent other state-of-the-art learned approaches, and achieving even higher inference speed. Our system has 14 times less params than Patch-NetVLAD, 6.8 times lower theoretical FLOPs, and run faster 21 and 33 times in feature extraction and feature matching. Moreover, the performance of our approach is 0.5\% better than Patch-NetVLAD in Recall@1. We used subsets of Mapillary Street Level Sequences dataset to conduct experiments for all other challenging conditions.
Cross-Modal Adapter for Text-Video Retrieval
Nov 17, 2022Text-video retrieval is an important multi-modal learning task, where the goal is to retrieve the most relevant video for a given text query. Recently, pre-trained models, e.g., CLIP, show great potential on this task. However, as pre-trained models are scaling up, fully fine-tuning them on text-video retrieval datasets has a high risk of overfitting. Moreover, in practice, it would be costly to train and store a large model for each task. To overcome the above issues, we present a novel $\textbf{Cross-Modal Adapter}$ for parameter-efficient fine-tuning. Inspired by adapter-based methods, we adjust the pre-trained model with a few parameterization layers. However, there are two notable differences. First, our method is designed for the multi-modal domain. Secondly, it allows early cross-modal interactions between CLIP's two encoders. Although surprisingly simple, our approach has three notable benefits: (1) reduces $\textbf{99.6}\%$ of fine-tuned parameters, and alleviates the problem of overfitting, (2) saves approximately 30% of training time, and (3) allows all the pre-trained parameters to be fixed, enabling the pre-trained model to be shared across datasets. Extensive experiments demonstrate that, without bells and whistles, it achieves superior or comparable performance compared to fully fine-tuned methods on MSR-VTT, MSVD, VATEX, ActivityNet, and DiDeMo datasets. The code will be available at \url{https://github.com/LeapLabTHU/Cross-Modal-Adapter}.
Efficient Knowledge Distillation from Model Checkpoints
Oct 12, 2022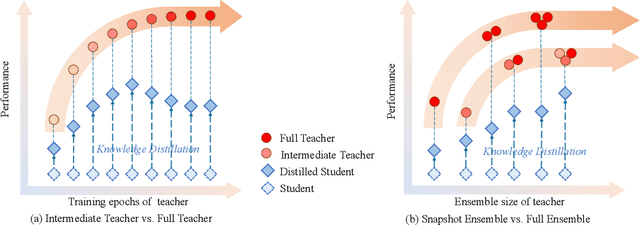
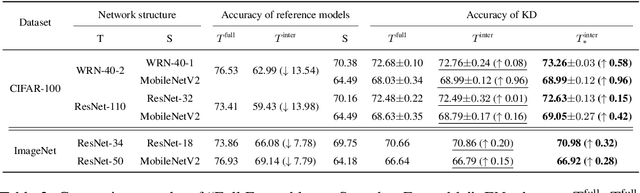
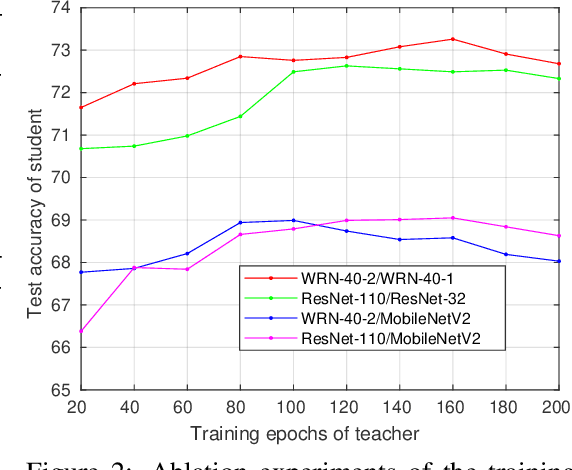
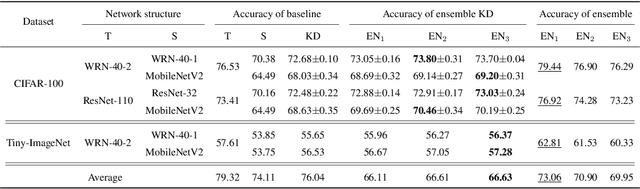
Knowledge distillation is an effective approach to learn compact models (students) with the supervision of large and strong models (teachers). As empirically there exists a strong correlation between the performance of teacher and student models, it is commonly believed that a high performing teacher is preferred. Consequently, practitioners tend to use a well trained network or an ensemble of them as the teacher. In this paper, we make an intriguing observation that an intermediate model, i.e., a checkpoint in the middle of the training procedure, often serves as a better teacher compared to the fully converged model, although the former has much lower accuracy. More surprisingly, a weak snapshot ensemble of several intermediate models from a same training trajectory can outperform a strong ensemble of independently trained and fully converged models, when they are used as teachers. We show that this phenomenon can be partially explained by the information bottleneck principle: the feature representations of intermediate models can have higher mutual information regarding the input, and thus contain more "dark knowledge" for effective distillation. We further propose an optimal intermediate teacher selection algorithm based on maximizing the total task-related mutual information. Experiments verify its effectiveness and applicability.
RenderNet: Visual Relocalization Using Virtual Viewpoints in Large-Scale Indoor Environments
Jul 26, 2022
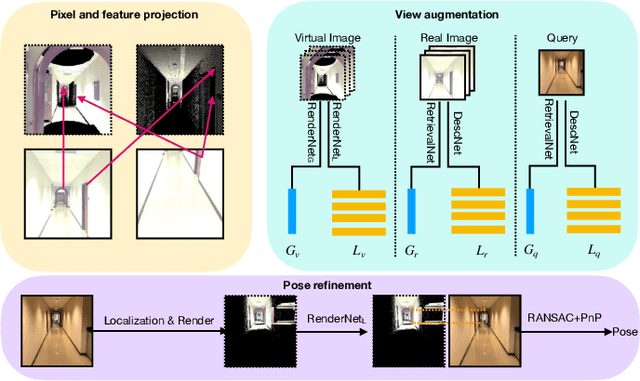
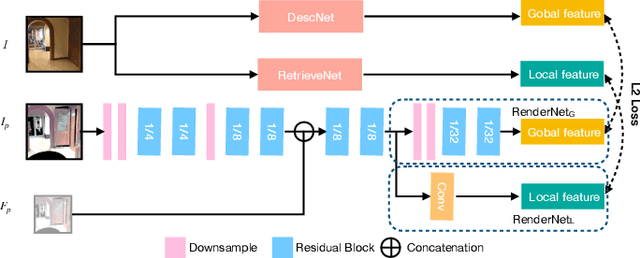

Visual relocalization has been a widely discussed problem in 3D vision: given a pre-constructed 3D visual map, the 6 DoF (Degrees-of-Freedom) pose of a query image is estimated. Relocalization in large-scale indoor environments enables attractive applications such as augmented reality and robot navigation. However, appearance changes fast in such environments when the camera moves, which is challenging for the relocalization system. To address this problem, we propose a virtual view synthesis-based approach, RenderNet, to enrich the database and refine poses regarding this particular scenario. Instead of rendering real images which requires high-quality 3D models, we opt to directly render the needed global and local features of virtual viewpoints and apply them in the subsequent image retrieval and feature matching operations respectively. The proposed method can largely improve the performance in large-scale indoor environments, e.g., achieving an improvement of 7.1\% and 12.2\% on the Inloc dataset.