 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Creates All: You Only Sample 3 Steps
Mar 23, 2026Diffusion models deliver high-fidelity generation but remain slow at inference time due to many sequential network evaluations. We find that standard timestep conditioning becomes a key bottleneck for few-step sampling. Motivated by layer-dependent denoising dynamics, we propose Multi-layer Time Embedding Optimization (MTEO), which freeze the pretrained diffusion backbone and distill a small set of step-wise, layer-wise time embeddings from reference trajectories. MTEO is plug-and-play with existing ODE solvers, adds no inference-time overhead, and trains only a tiny fraction of parameters. Extensive experiments across diverse datasets and backbones show state-of-the-art performance in the few-step sampling and substantially narrow the gap between distillation-based and lightweight methods. Code will be available.
VeloEdit: Training-Free Consistent and Continuous Instruction-Based Image Editing via Velocity Field Decomposition
Mar 11, 2026Instruction-based image editing aims to modify source content according to textual instructions. However, existing methods built upon flow matching often struggle to maintain consistency in non-edited regions due to denoising-induced reconstruction errors that cause drift in preserved content. Moreover, they typically lack fine-grained control over edit strength. To address these limitations, we propose VeloEdit, a training-free method that enables highly consistent and continuously controllable editing. VeloEdit dynamically identifies editing regions by quantifying the discrepancy between the velocity fields responsible for preserving source content and those driving the desired edits. Based on this partition, we enforce consistency in preservation regions by substituting the editing velocity with the source-restoring velocity, while enabling continuous modulation of edit intensity in target regions via velocity interpolation. Unlike prior works that rely on complex attention manipulation or auxiliary trainable modules, VeloEdit operates directly on the velocity fields. Extensive experiments on Flux.1 Kontext and Qwen-Image-Edit demonstrate that VeloEdit improves visual consistency and editing continuity with negligible additional computational cost. Code is available at https://github.com/xmulzq/VeloEdit.
Diffusion Sampling Correction via Approximately 10 Parameters
Nov 14, 2024



Diffusion Probabilistic Models (DPMs) have demonstrated exceptional performance in generative tasks, but this comes at the expense of sampling efficiency. To enhance sampling speed without sacrificing quality, various distillation-based accelerated sampling algorithms have been recently proposed. However, they typically require significant additional training costs and model parameter storage, which limit their practical application. In this work, we propose PCA-based Adaptive Search (PAS), which optimizes existing solvers for DPMs with minimal learnable parameters and training costs. Specifically, we first employ PCA to obtain a few orthogonal unit basis vectors to span the high-dimensional sampling space, which enables us to learn just a set of coordinates to correct the sampling direction; furthermore, based on the observation that the cumulative truncation error exhibits an ``S''-shape, we design an adaptive search strategy that further enhances the sampling efficiency and reduces the number of stored parameters to approximately 10. Extensive experiments demonstrate that PAS can significantly enhance existing fast solvers in a plug-and-play manner with negligible costs. For instance, on CIFAR10, PAS requires only 12 parameters and less than 1 minute of training on a single NVIDIA A100 GPU to optimize the DDIM from 15.69 FID (NFE=10) to 4.37.
PFDiff: Training-free Acceleration of Diffusion Models through the Gradient Guidance of Past and Future
Aug 16, 2024Diffusion Probabilistic Models (DPMs) have shown remarkable potential in image generation, but their sampling efficiency is hindered by the need for numerous denoising steps. Most existing solutions accelerate the sampling process by proposing fast ODE solvers. However, the inevitable discretization errors of the ODE solvers are significantly magnified when the number of function evaluations (NFE) is fewer. In this work, we propose PFDiff, a novel training-free and orthogonal timestep-skipping strategy, which enables existing fast ODE solvers to operate with fewer NFE. Based on two key observations: a significant similarity in the model's outputs at time step size that is not excessively large during the denoising process of existing ODE solvers, and a high resemblance between the denoising process and SGD. PFDiff, by employing gradient replacement from past time steps and foresight updates inspired by Nesterov momentum, rapidly updates intermediate states, thereby reducing unnecessary NFE while correcting for discretization errors inherent in first-order ODE solvers. Experimental results demonstrate that PFDiff exhibits flexible applicability across various pre-trained DPMs, particularly excelling in conditional DPMs and surpassing previous state-of-the-art training-free methods. For instance, using DDIM as a baseline, we achieved 16.46 FID (4 NFE) compared to 138.81 FID with DDIM on ImageNet 64x64 with classifier guidance, and 13.06 FID (10 NFE) on Stable Diffusion with 7.5 guidance scale.
A Faster, Lighter and Stronger Deep Learning-Based Approach for Place Recognition
Nov 27, 2022



Visual Place Recognition is an essential component of systems for camera localization and loop closure detection, and it has attracted widespread interest in multiple domains such as computer vision, robotics and AR/VR. In this work, we propose a faster, lighter and stronger approach that can generate models with fewer parameters and can spend less time in the inference stage. We designed RepVGG-lite as the backbone network in our architecture, it is more discriminative than other general networks in the Place Recognition task. RepVGG-lite has more speed advantages while achieving higher performance. We extract only one scale patch-level descriptors from global descriptors in the feature extraction stage. Then we design a trainable feature matcher to exploit both spatial relationships of the features and their visual appearance, which is based on the attention mechanism. Comprehensive experiments on challenging benchmark datasets demonstrate the proposed method outperforming recent other state-of-the-art learned approaches, and achieving even higher inference speed. Our system has 14 times less params than Patch-NetVLAD, 6.8 times lower theoretical FLOPs, and run faster 21 and 33 times in feature extraction and feature matching. Moreover, the performance of our approach is 0.5\% better than Patch-NetVLAD in Recall@1. We used subsets of Mapillary Street Level Sequences dataset to conduct experiments for all other challenging conditions.
EventPoint: Self-Supervised Local Descriptor Learning for Event Cameras
Sep 01, 2021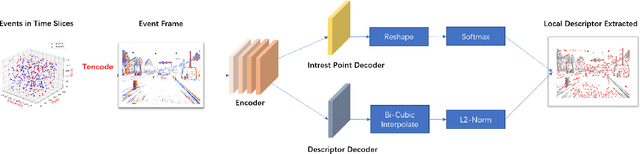

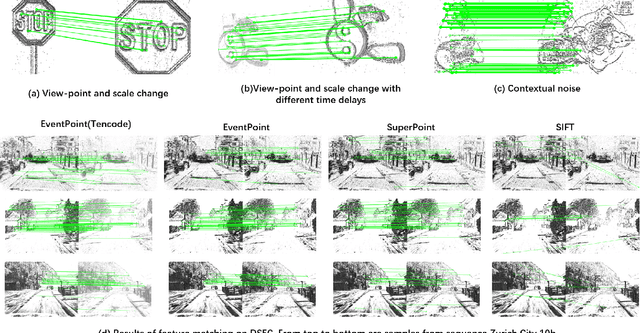
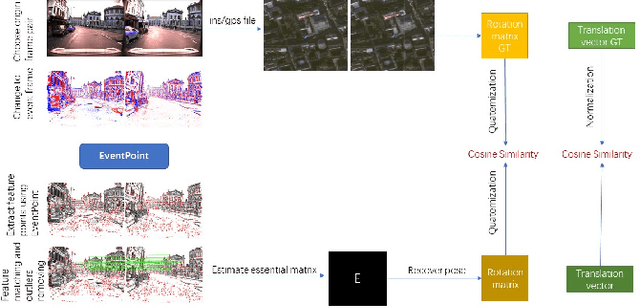
We proposes a method of extracting intrest points and descriptors using self-supervised learning method on frame-based event data, which is called EventPoint. Different from other feature extraction methods on event data, we train our model on real event-form driving dataset--DSEC with the self-supervised learning method we proposed, the training progress fully consider the characteristics of event data.To verify the effectiveness of our work,we conducted several complete evaluations: we emulated DART and carried out feature matching experiments on N-caltech101 dataset, the results shows that the effect of EventPoint is better than DART; We use Vid2e tool provided by UZH to convert Oxford robotcar data into event-based format, and combined with INS information provided to carry out the global pose estimation experiment which is important in SLAM. As far as we know, this is the first work to carry out this challenging task.Sufficient experimental data show that EventPoint can get better results while achieve real time on CPU.
NDT-Transformer: Large-Scale 3D Point Cloud Localisation using the Normal Distribution Transform Representation
Mar 23, 2021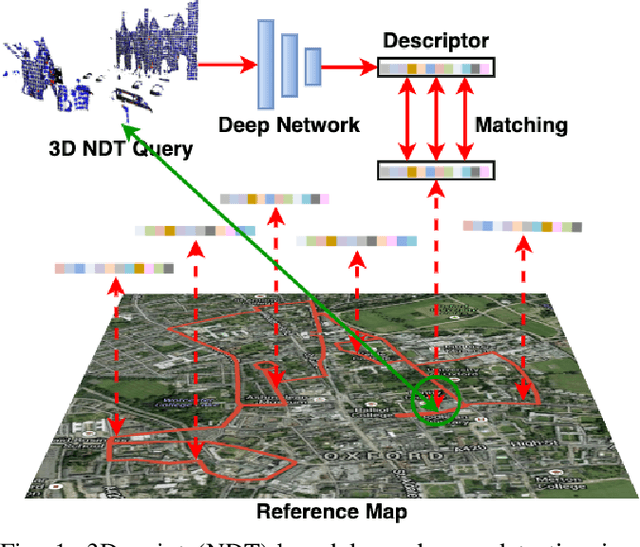

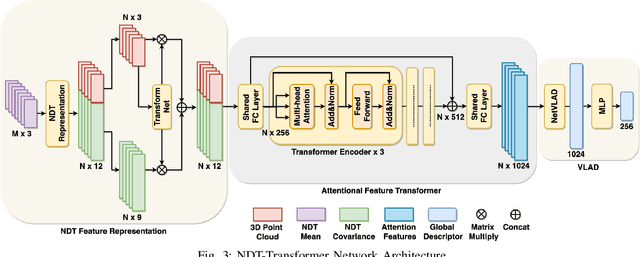
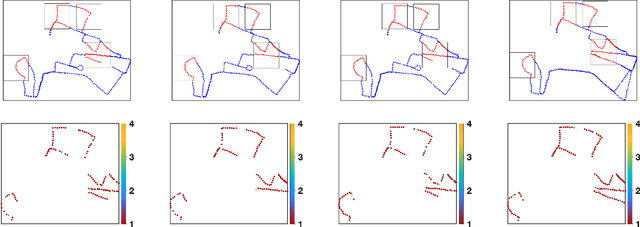
3D point cloud-based place recognition is highly demanded by autonomous driving in GPS-challenged environments and serves as an essential component (i.e. loop-closure detection) in lidar-based SLAM systems. This paper proposes a novel approach, named NDT-Transformer, for realtime and large-scale place recognition using 3D point clouds. Specifically, a 3D Normal Distribution Transform (NDT) representation is employed to condense the raw, dense 3D point cloud as probabilistic distributions (NDT cells) to provide the geometrical shape description. Then a novel NDT-Transformer network learns a global descriptor from a set of 3D NDT cell representations. Benefiting from the NDT representation and NDT-Transformer network, the learned global descriptors are enriched with both geometrical and contextual information. Finally, descriptor retrieval is achieved using a query-database for place recognition. Compared to the state-of-the-art methods, the proposed approach achieves an improvement of 7.52% on average top 1 recall and 2.73% on average top 1% recall on the Oxford Robotcar benchmark.
Detecting Ground Control Points via Convolutional Neural Network for Stereo Matching
May 08, 2016

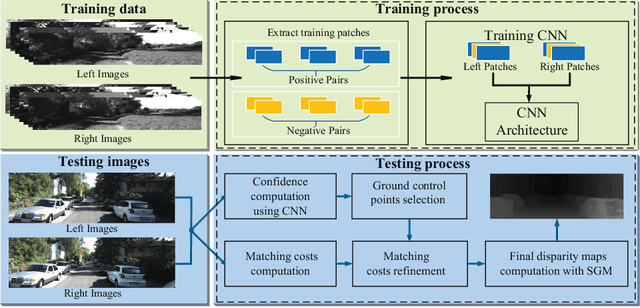

In this paper, we present a novel approach to detect ground control points (GCPs) for stereo matching problem. First of all, we train a convolutional neural network (CNN) on a large stereo set, and compute the matching confidence of each pixel by using the trained CNN model. Secondly, we present a ground control points selection scheme according to the maximum matching confidence of each pixel. Finally, the selected GCPs are used to refine the matching costs, and we apply the new matching costs to perform optimization with semi-global matching algorithm for improving the final disparity maps. We evaluate our approach on the KITTI 2012 stereo benchmark dataset. Our experiments show that the proposed approach significantly improves the accuracy of disparity maps.