 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning
Mar 20, 2019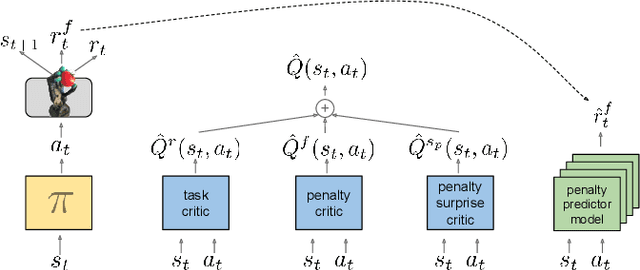

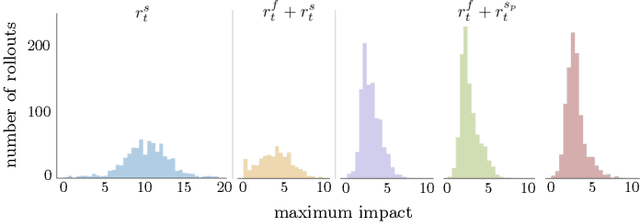
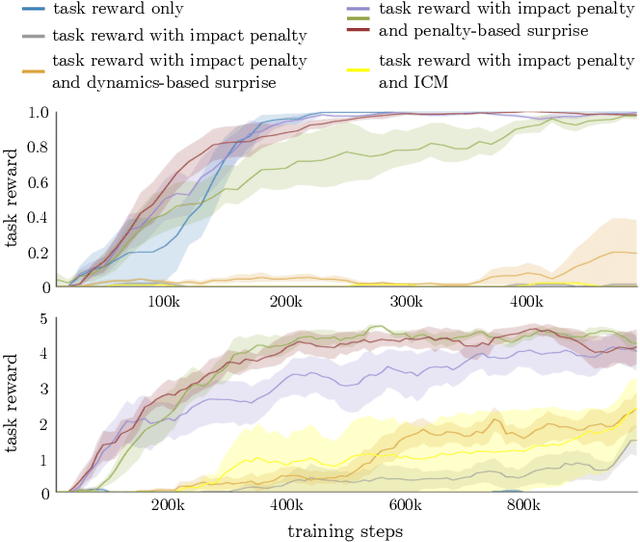
Robots must know how to be gentle when they need to interact with fragile objects, or when the robot itself is prone to wear and tear. We propose an approach that enables deep reinforcement learning to train policies that are gentle, both during exploration and task execution. In a reward-based learning environment, a natural approach involves augmenting the (task) reward with a penalty for non-gentleness, which can be defined as excessive impact force. However, augmenting with only this penalty impairs learning: policies get stuck in a local optimum which avoids all contact with the environment. Prior research has shown that combining auxiliary tasks or intrinsic rewards can be beneficial for stabilizing and accelerating learning in sparse-reward domains, and indeed we find that introducing a surprise-based intrinsic reward does avoid the no-contact failure case. However, we show that a simple dynamics-based surprise is not as effective as penalty-based surprise. Penalty-based surprise, based on predicting forceful contacts, has a further benefit: it encourages exploration which is contact-rich yet gentle. We demonstrate the effectiveness of the approach using a complex, tendon-powered robot hand with tactile sensors. Videos are available at http://sites.google.com/view/gentlemanipulation.
The StreetLearn Environment and Dataset
Mar 04, 2019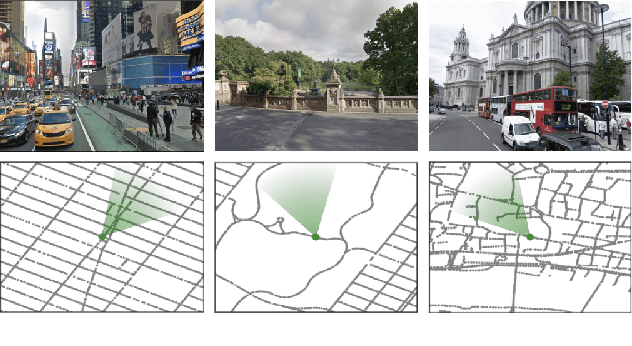
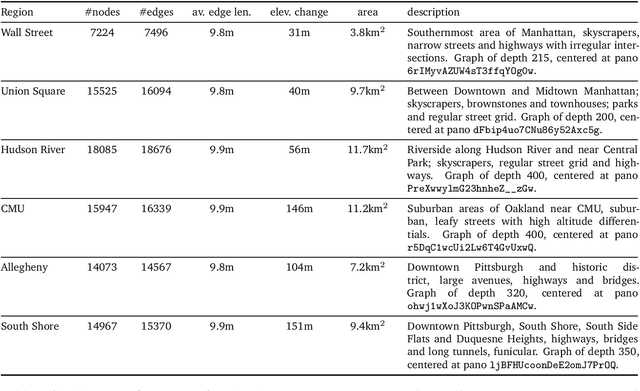
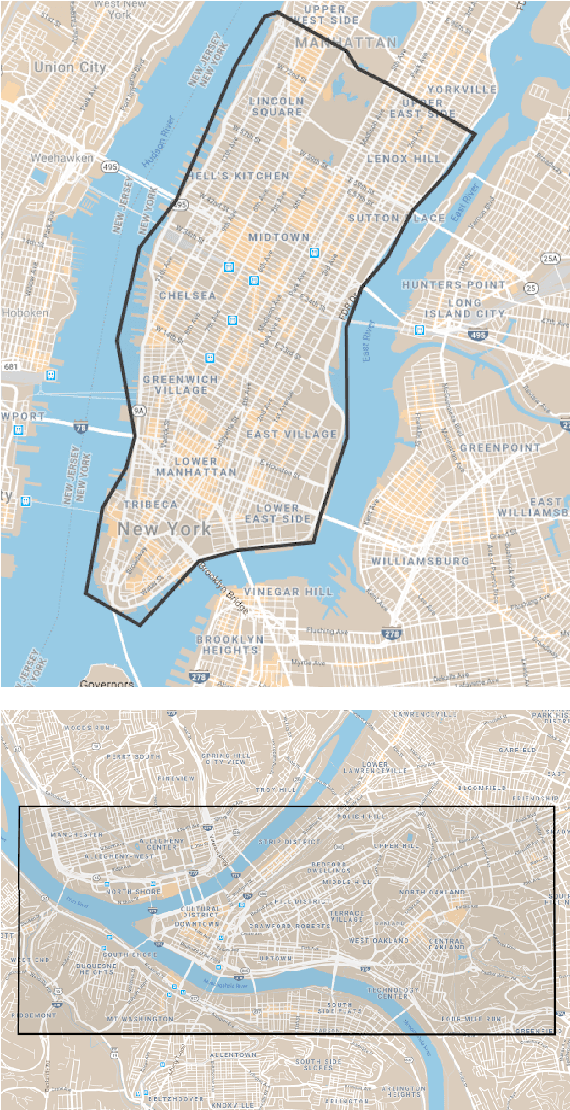
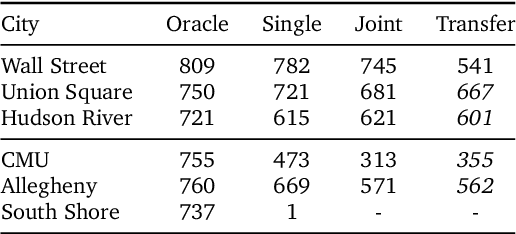
Navigation is a rich and well-grounded problem domain that drives progress in many different areas of research: perception, planning, memory, exploration, and optimisation in particular. Historically these challenges have been separately considered and solutions built that rely on stationary datasets - for example, recorded trajectories through an environment. These datasets cannot be used for decision-making and reinforcement learning, however, and in general the perspective of navigation as an interactive learning task, where the actions and behaviours of a learning agent are learned simultaneously with the perception and planning, is relatively unsupported. Thus, existing navigation benchmarks generally rely on static datasets (Geiger et al., 2013; Kendall et al., 2015) or simulators (Beattie et al., 2016; Shah et al., 2018). To support and validate research in end-to-end navigation, we present StreetLearn: an interactive, first-person, partially-observed visual environment that uses Google Street View for its photographic content and broad coverage, and give performance baselines for a challenging goal-driven navigation task. The environment code, baseline agent code, and the dataset are available at http://streetlearn.cc
Learning To Follow Directions in Street View
Mar 01, 2019
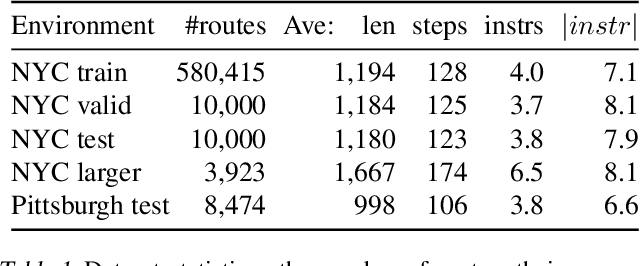
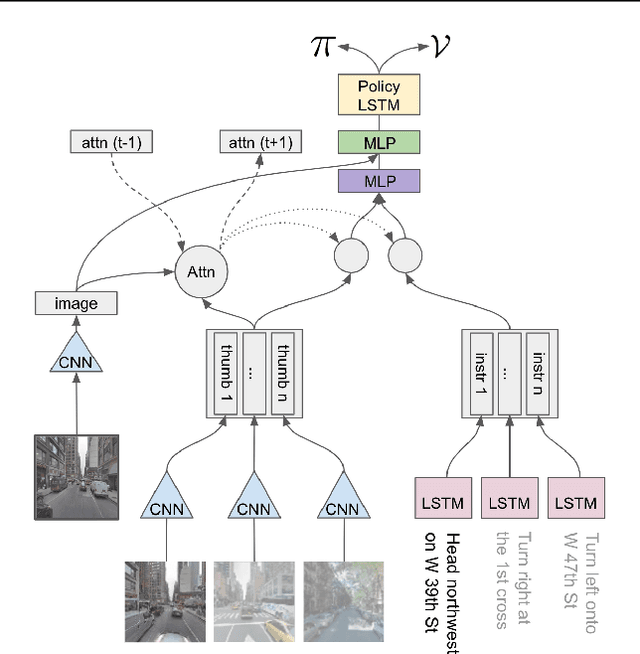
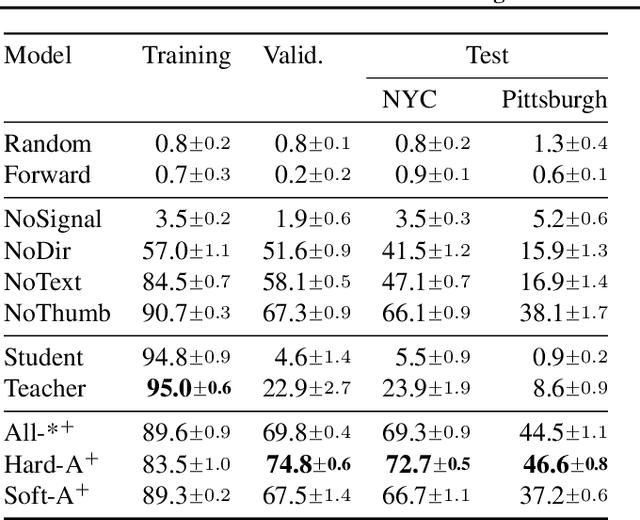
Navigating and understanding the real world remains a key challenge in machine learning and inspires a great variety of research in areas such as language grounding, planning, navigation and computer vision. We propose an instruction-following task that requires all of the above, and which combines the practicality of simulated environments with the challenges of ambiguous, noisy real world data. StreetNav is built on top of Google Street View and provides visually accurate environments representing real places. Agents are given driving instructions which they must learn to interpret in order to successfully navigate in this environment. Since humans equipped with driving instructions can readily navigate in previously unseen cities, we set a high bar and test our trained agents for similar cognitive capabilities. Although deep reinforcement learning (RL) methods are frequently evaluated only on data that closely follow the training distribution, our dataset extends to multiple cities and has a clean train/test separation. This allows for thorough testing of generalisation ability. This paper presents the StreetNav environment and tasks, a set of novel models that establish strong baselines, and analysis of the task and the trained agents.
Value constrained model-free continuous control
Feb 12, 2019
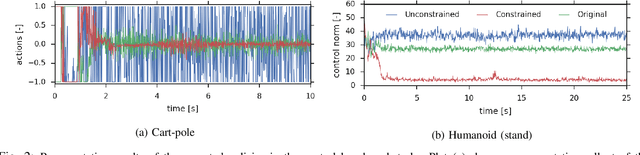

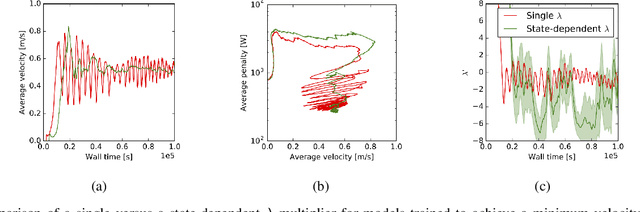
The naive application of Reinforcement Learning algorithms to continuous control problems -- such as locomotion and manipulation -- often results in policies which rely on high-amplitude, high-frequency control signals, known colloquially as bang-bang control. Although such solutions may indeed maximize task reward, they can be unsuitable for real world systems. Bang-bang control may lead to increased wear and tear or energy consumption, and tends to excite undesired second-order dynamics. To counteract this issue, multi-objective optimization can be used to simultaneously optimize both the reward and some auxiliary cost that discourages undesired (e.g. high-amplitude) control. In principle, such an approach can yield the sought after, smooth, control policies. It can, however, be hard to find the correct trade-off between cost and return that results in the desired behavior. In this paper we propose a new constraint-based reinforcement learning approach that ensures task success while minimizing one or more auxiliary costs (such as control effort). We employ Lagrangian relaxation to learn both (a) the parameters of a control policy that satisfies the desired constraints and (b) the Lagrangian multipliers for the optimization. Moreover, we demonstrate that we can satisfy constraints either in expectation or in a per-step fashion, and can even learn a single policy that is able to dynamically trade-off between return and cost. We demonstrate the efficacy of our approach using a number of continuous control benchmark tasks, a realistic, energy-optimized quadruped locomotion task, as well as a reaching task on a real robot arm.
From pixels to percepts: Highly robust edge perception and contour following using deep learning and an optical biomimetic tactile sensor
Feb 06, 2019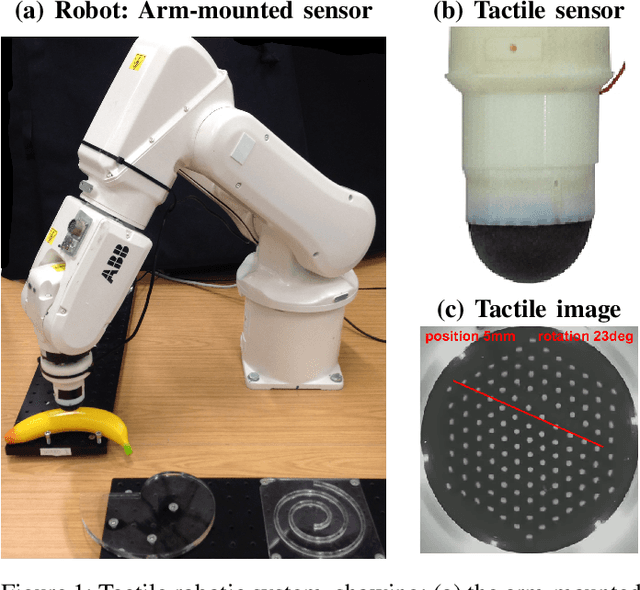
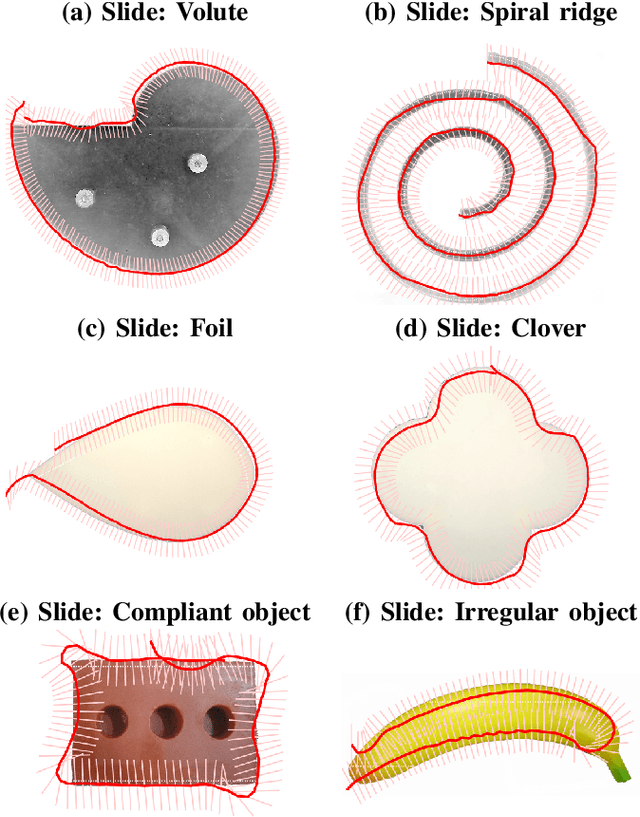
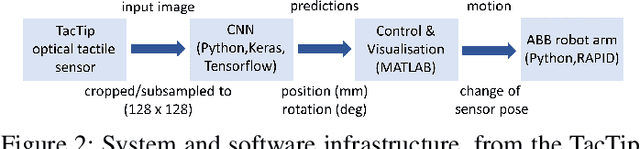
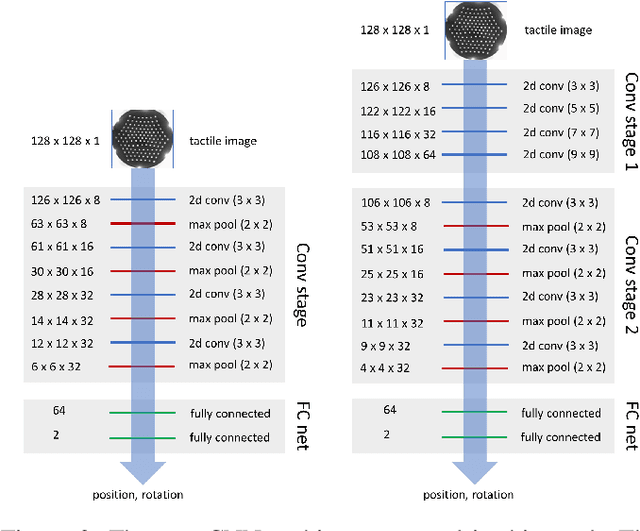
Deep learning has the potential to have the impact on robot touch that it has had on robot vision. Optical tactile sensors act as a bridge between the subjects by allowing techniques from vision to be applied to touch. In this paper, we apply deep learning to an optical biomimetic tactile sensor, the TacTip, which images an array of papillae (pins) inside its sensing surface analogous to structures within human skin. Our main result is that the application of a deep CNN can give reliable edge perception and thus a robust policy for planning contact points to move around object contours. Robustness is demonstrated over several irregular and compliant objects with both tapping and continuous sliding, using a model trained only by tapping onto a disk. These results relied on using techniques to encourage generalization to tasks beyond which the model was trained. We expect this is a generic problem in practical applications of tactile sensing that deep learning will solve. A video demonstrating the approach can be found at https://www.youtube.com/watch?v=QHrGsG9AHts
Meta-Learning with Latent Embedding Optimization
Sep 28, 2018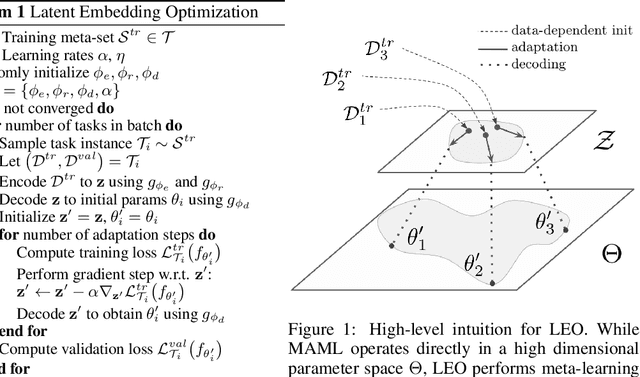
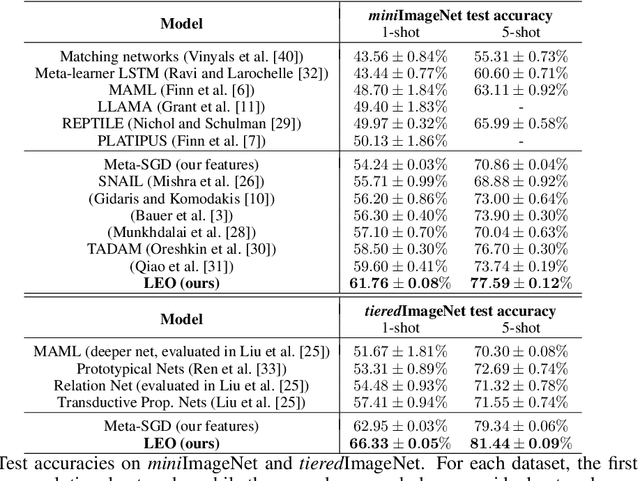
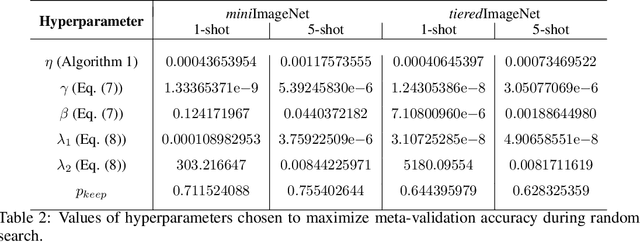
Gradient-based meta-learning techniques are both widely applicable and proficient at solving challenging few-shot learning and fast adaptation problems. However, they have practical difficulties when operating on high-dimensional parameter spaces in extreme low-data regimes. We show that it is possible to bypass these limitations by learning a data-dependent latent generative representation of model parameters, and performing gradient-based meta-learning in this low-dimensional latent space. The resulting approach, latent embedding optimization (LEO), decouples the gradient-based adaptation procedure from the underlying high-dimensional space of model parameters. Our evaluation shows that LEO can achieve state-of-the-art performance on the competitive miniImageNet and tieredImageNet few-shot classification tasks. Further analysis indicates LEO is able to capture uncertainty in the data, and can perform adaptation more effectively by optimizing in latent space.
Learning Deployable Navigation Policies at Kilometer Scale from a Single Traversal
Jul 11, 2018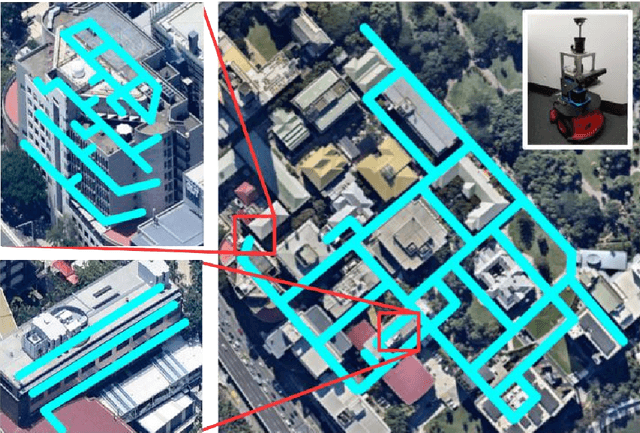
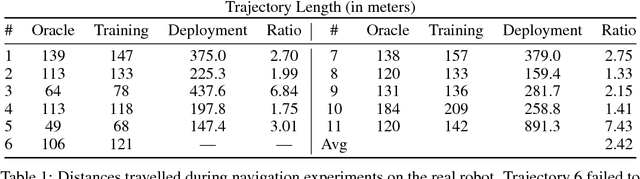

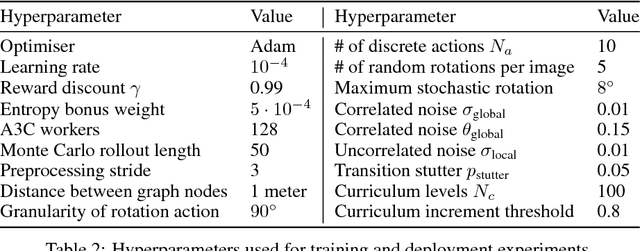
Model-free reinforcement learning has recently been shown to be effective at learning navigation policies from complex image input. However, these algorithms tend to require large amounts of interaction with the environment, which can be prohibitively costly to obtain on robots in the real world. We present an approach for efficiently learning goal-directed navigation policies on a mobile robot, from only a single coverage traversal of recorded data. The navigation agent learns an effective policy over a diverse action space in a large heterogeneous environment consisting of more than 2km of travel, through buildings and outdoor regions that collectively exhibit large variations in visual appearance, self-similarity, and connectivity. We compare pretrained visual encoders that enable precomputation of visual embeddings to achieve a throughput of tens of thousands of transitions per second at training time on a commodity desktop computer, allowing agents to learn from millions of trajectories of experience in a matter of hours. We propose multiple forms of computationally efficient stochastic augmentation to enable the learned policy to generalise beyond these precomputed embeddings, and demonstrate successful deployment of the learned policy on the real robot without fine tuning, despite environmental appearance differences at test time. The dataset and code required to reproduce these results and apply the technique to other datasets and robots is made publicly available at rl-navigation.github.io/deployable.
Progress & Compress: A scalable framework for continual learning
Jul 02, 2018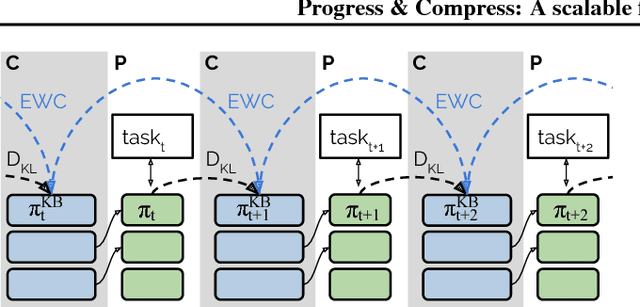
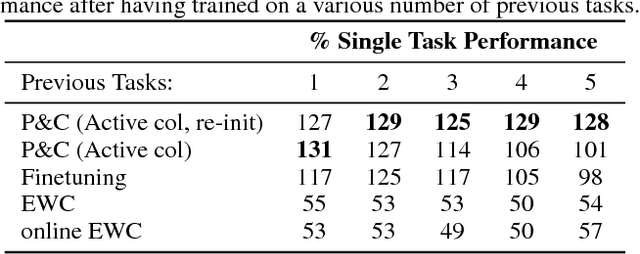
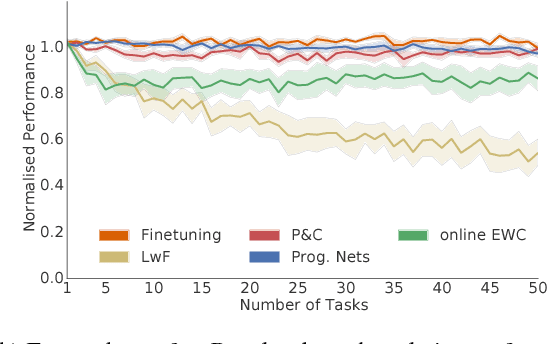
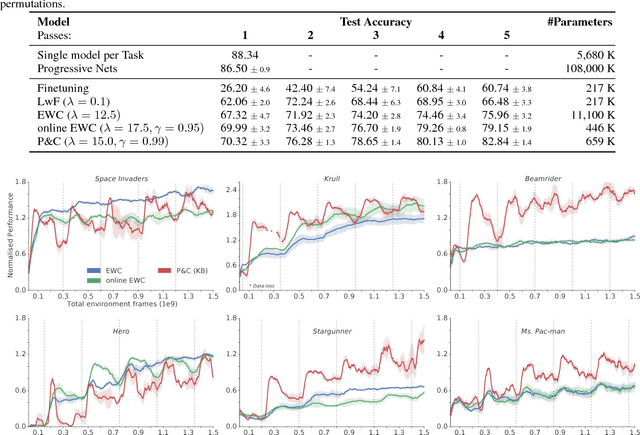
We introduce a conceptually simple and scalable framework for continual learning domains where tasks are learned sequentially. Our method is constant in the number of parameters and is designed to preserve performance on previously encountered tasks while accelerating learning progress on subsequent problems. This is achieved by training a network with two components: A knowledge base, capable of solving previously encountered problems, which is connected to an active column that is employed to efficiently learn the current task. After learning a new task, the active column is distilled into the knowledge base, taking care to protect any previously acquired skills. This cycle of active learning (progression) followed by consolidation (compression) requires no architecture growth, no access to or storing of previous data or tasks, and no task-specific parameters. We demonstrate the progress & compress approach on sequential classification of handwritten alphabets as well as two reinforcement learning domains: Atari games and 3D maze navigation.
Graph networks as learnable physics engines for inference and control
Jun 04, 2018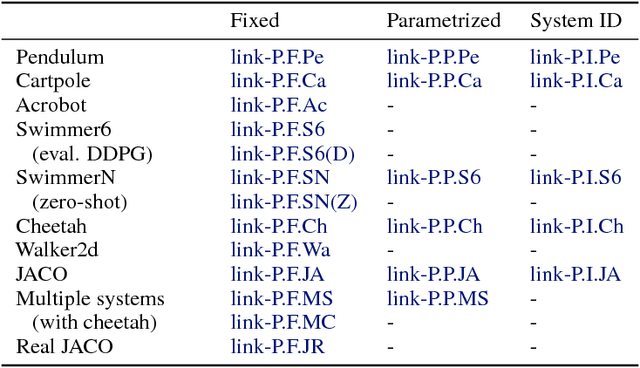
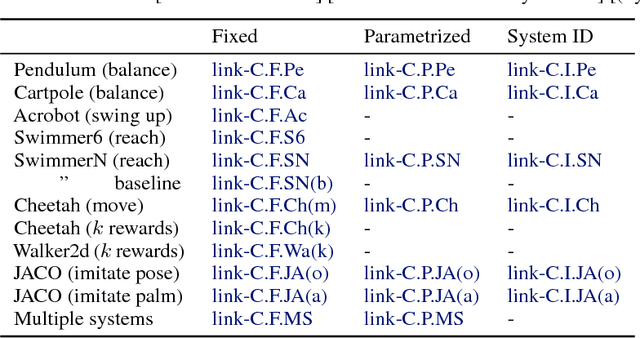
Understanding and interacting with everyday physical scenes requires rich knowledge about the structure of the world, represented either implicitly in a value or policy function, or explicitly in a transition model. Here we introduce a new class of learnable models--based on graph networks--which implement an inductive bias for object- and relation-centric representations of complex, dynamical systems. Our results show that as a forward model, our approach supports accurate predictions from real and simulated data, and surprisingly strong and efficient generalization, across eight distinct physical systems which we varied parametrically and structurally. We also found that our inference model can perform system identification. Our models are also differentiable, and support online planning via gradient-based trajectory optimization, as well as offline policy optimization. Our framework offers new opportunities for harnessing and exploiting rich knowledge about the world, and takes a key step toward building machines with more human-like representations of the world.
Reinforcement and Imitation Learning for Diverse Visuomotor Skills
May 27, 2018
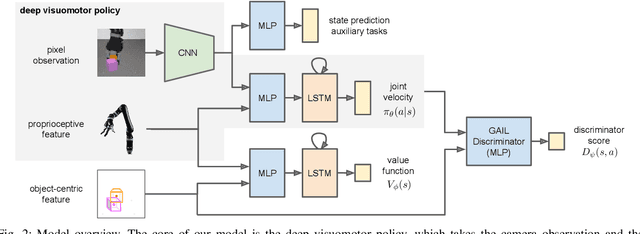
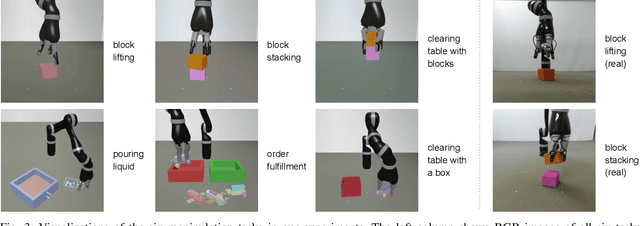
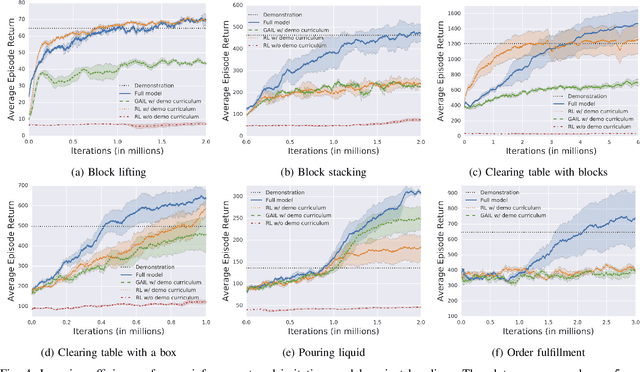
We propose a model-free deep reinforcement learning method that leverages a small amount of demonstration data to assist a reinforcement learning agent. We apply this approach to robotic manipulation tasks and train end-to-end visuomotor policies that map directly from RGB camera inputs to joint velocities. We demonstrate that our approach can solve a wide variety of visuomotor tasks, for which engineering a scripted controller would be laborious. In experiments, our reinforcement and imitation agent achieves significantly better performances than agents trained with reinforcement learning or imitation learning alone. We also illustrate that these policies, trained with large visual and dynamics variations, can achieve preliminary successes in zero-shot sim2real transfer. A brief visual description of this work can be viewed in https://youtu.be/EDl8SQUNjj0