 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChanges in Real Time: Online Scene Change Detection with Multi-View Fusion
Nov 15, 2025



Online Scene Change Detection (SCD) is an extremely challenging problem that requires an agent to detect relevant changes on the fly while observing the scene from unconstrained viewpoints. Existing online SCD methods are significantly less accurate than offline approaches. We present the first online SCD approach that is pose-agnostic, label-free, and ensures multi-view consistency, while operating at over 10 FPS and achieving new state-of-the-art performance, surpassing even the best offline approaches. Our method introduces a new self-supervised fusion loss to infer scene changes from multiple cues and observations, PnP-based fast pose estimation against the reference scene, and a fast change-guided update strategy for the 3D Gaussian Splatting scene representation. Extensive experiments on complex real-world datasets demonstrate that our approach outperforms both online and offline baselines.
Multi-Modal 3D Scene Graph Updater for Shared and Dynamic Environments
Nov 05, 2024

The advent of generalist Large Language Models (LLMs) and Large Vision Models (VLMs) have streamlined the construction of semantically enriched maps that can enable robots to ground high-level reasoning and planning into their representations. One of the most widely used semantic map formats is the 3D Scene Graph, which captures both metric (low-level) and semantic (high-level) information. However, these maps often assume a static world, while real environments, like homes and offices, are dynamic. Even small changes in these spaces can significantly impact task performance. To integrate robots into dynamic environments, they must detect changes and update the scene graph in real-time. This update process is inherently multimodal, requiring input from various sources, such as human agents, the robot's own perception system, time, and its actions. This work proposes a framework that leverages these multimodal inputs to maintain the consistency of scene graphs during real-time operation, presenting promising initial results and outlining a roadmap for future research.
Physically Embodied Gaussian Splatting: A Realtime Correctable World Model for Robotics
Jun 16, 2024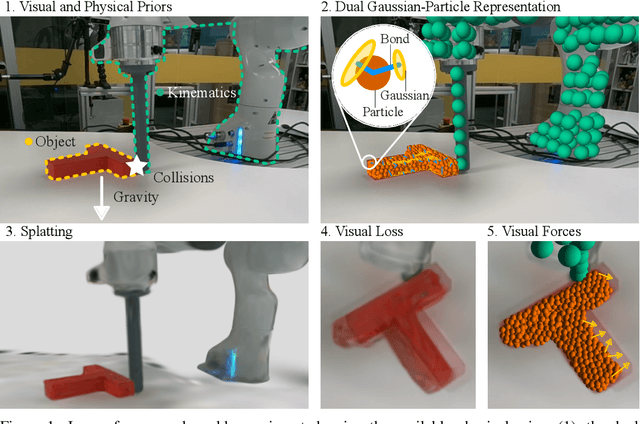
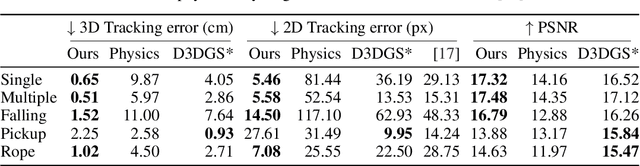


For robots to robustly understand and interact with the physical world, it is highly beneficial to have a comprehensive representation - modelling geometry, physics, and visual observations - that informs perception, planning, and control algorithms. We propose a novel dual Gaussian-Particle representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates visual forces that correct the particle positions while respecting known physical constraints. By integrating predictive physical modelling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality. Our system runs in realtime at 30Hz using only 3 cameras. We validate our approach on 2D and 3D tracking tasks as well as photometric reconstruction quality. Videos are found at https://embodied-gaussians.github.io/.
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation
May 09, 2024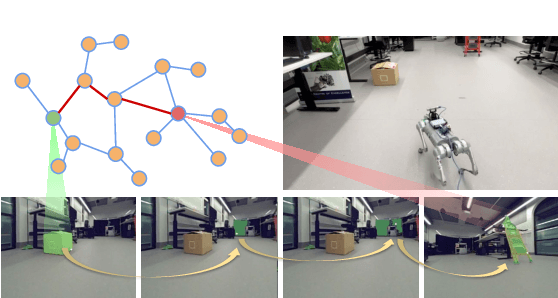
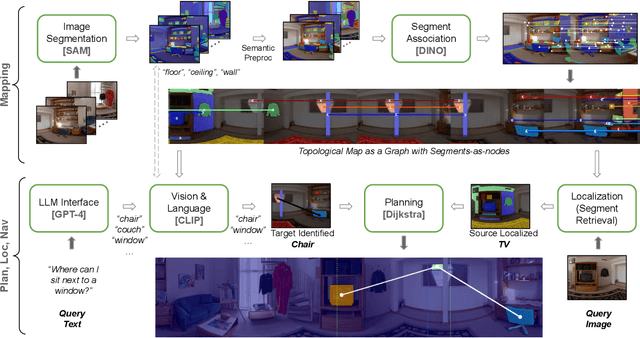
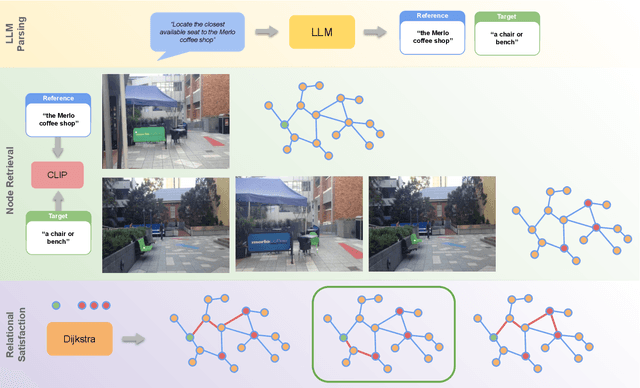

Mapping is crucial for spatial reasoning, planning and robot navigation. Existing approaches range from metric, which require precise geometry-based optimization, to purely topological, where image-as-node based graphs lack explicit object-level reasoning and interconnectivity. In this paper, we propose a novel topological representation of an environment based on "image segments", which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a "continuous sense of a place", defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval. Using real-world data, we show how our proposed map representation can be used to i) generate navigation plans in the form of "hops over segments" and ii) search for target objects using natural language queries describing spatial relations of objects. Furthermore, we quantitatively analyze data association at the segment level, which underpins inter-image connectivity during mapping and segment-level localization when revisiting the same place. Finally, we show preliminary trials on segment-level `hopping' based zero-shot real-world navigation. Project page with supplementary details: oravus.github.io/RoboHop/
Open-Set Recognition in the Age of Vision-Language Models
Mar 25, 2024



Are vision-language models (VLMs) open-set models because they are trained on internet-scale datasets? We answer this question with a clear no - VLMs introduce closed-set assumptions via their finite query set, making them vulnerable to open-set conditions. We systematically evaluate VLMs for open-set recognition and find they frequently misclassify objects not contained in their query set, leading to alarmingly low precision when tuned for high recall and vice versa. We show that naively increasing the size of the query set to contain more and more classes does not mitigate this problem, but instead causes diminishing task performance and open-set performance. We establish a revised definition of the open-set problem for the age of VLMs, define a new benchmark and evaluation protocol to facilitate standardised evaluation and research in this important area, and evaluate promising baseline approaches based on predictive uncertainty and dedicated negative embeddings on a range of VLM classifiers and object detectors.
LHManip: A Dataset for Long-Horizon Language-Grounded Manipulation Tasks in Cluttered Tabletop Environments
Dec 20, 2023



Instructing a robot to complete an everyday task within our homes has been a long-standing challenge for robotics. While recent progress in language-conditioned imitation learning and offline reinforcement learning has demonstrated impressive performance across a wide range of tasks, they are typically limited to short-horizon tasks -- not reflective of those a home robot would be expected to complete. While existing architectures have the potential to learn these desired behaviours, the lack of the necessary long-horizon, multi-step datasets for real robotic systems poses a significant challenge. To this end, we present the Long-Horizon Manipulation (LHManip) dataset comprising 200 episodes, demonstrating 20 different manipulation tasks via real robot teleoperation. The tasks entail multiple sub-tasks, including grasping, pushing, stacking and throwing objects in highly cluttered environments. Each task is paired with a natural language instruction and multi-camera viewpoints for point-cloud or NeRF reconstruction. In total, the dataset comprises 176,278 observation-action pairs which form part of the Open X-Embodiment dataset. The full LHManip dataset is made publicly available at https://github.com/fedeceola/LHManip.
Contrastive Language, Action, and State Pre-training for Robot Learning
Apr 21, 2023In this paper, we introduce a method for unifying language, action, and state information in a shared embedding space to facilitate a range of downstream tasks in robot learning. Our method, Contrastive Language, Action, and State Pre-training (CLASP), extends the CLIP formulation by incorporating distributional learning, capturing the inherent complexities and one-to-many relationships in behaviour-text alignment. By employing distributional outputs for both text and behaviour encoders, our model effectively associates diverse textual commands with a single behaviour and vice-versa. We demonstrate the utility of our method for the following downstream tasks: zero-shot text-behaviour retrieval, captioning unseen robot behaviours, and learning a behaviour prior for language-conditioned reinforcement learning. Our distributional encoders exhibit superior retrieval and captioning performance on unseen datasets, and the ability to generate meaningful exploratory behaviours from textual commands, capturing the intricate relationships between language, action, and state. This work represents an initial step towards developing a unified pre-trained model for robotics, with the potential to generalise to a broad range of downstream tasks.
Addressing the Challenges of Open-World Object Detection
Mar 27, 2023We address the challenging problem of open world object detection (OWOD), where object detectors must identify objects from known classes while also identifying and continually learning to detect novel objects. Prior work has resulted in detectors that have a relatively low ability to detect novel objects, and a high likelihood of classifying a novel object as one of the known classes. We approach the problem by identifying the three main challenges that OWOD presents and introduce OW-RCNN, an open world object detector that addresses each of these three challenges. OW-RCNN establishes a new state of the art using the open-world evaluation protocol on MS-COCO, showing a drastically increased ability to detect novel objects (16-21% absolute increase in U-Recall), to avoid their misclassification as one of the known classes (up to 52% reduction in A-OSE), and to incrementally learn to detect them while maintaining performance on previously known classes (1-6% absolute increase in mAP).
ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic Scenes
Nov 11, 2022



Neural Radiance Fields (NeRFs) learn implicit representations of - typically static - environments from images. Our paper extends NeRFs to handle dynamic scenes in an online fashion. We propose ParticleNeRF that adapts to changes in the geometry of the environment as they occur, learning a new up-to-date representation every 350 ms. ParticleNeRF can represent the current state of dynamic environments with much higher fidelity as other NeRF frameworks. To achieve this, we introduce a new particle-based parametric encoding, which allows the intermediate NeRF features - now coupled to particles in space - to move with the dynamic geometry. This is possible by backpropagating the photometric reconstruction loss into the position of the particles. The position gradients are interpreted as particle velocities and integrated into positions using a position-based dynamics (PBS) physics system. Introducing PBS into the NeRF formulation allows us to add collision constraints to the particle motion and creates future opportunities to add other movement priors into the system, such as rigid and deformable body
Residual Skill Policies: Learning an Adaptable Skill-based Action Space for Reinforcement Learning for Robotics
Nov 04, 2022



Skill-based reinforcement learning (RL) has emerged as a promising strategy to leverage prior knowledge for accelerated robot learning. Skills are typically extracted from expert demonstrations and are embedded into a latent space from which they can be sampled as actions by a high-level RL agent. However, this skill space is expansive, and not all skills are relevant for a given robot state, making exploration difficult. Furthermore, the downstream RL agent is limited to learning structurally similar tasks to those used to construct the skill space. We firstly propose accelerating exploration in the skill space using state-conditioned generative models to directly bias the high-level agent towards only sampling skills relevant to a given state based on prior experience. Next, we propose a low-level residual policy for fine-grained skill adaptation enabling downstream RL agents to adapt to unseen task variations. Finally, we validate our approach across four challenging manipulation tasks that differ from those used to build the skill space, demonstrating our ability to learn across task variations while significantly accelerating exploration, outperforming prior works. Code and videos are available on our project website: https://krishanrana.github.io/reskill.