 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Production-Ready Probes For Gemini
Jan 16, 2026Frontier language model capabilities are improving rapidly. We thus need stronger mitigations against bad actors misusing increasingly powerful systems. Prior work has shown that activation probes may be a promising misuse mitigation technique, but we identify a key remaining challenge: probes fail to generalize under important production distribution shifts. In particular, we find that the shift from short-context to long-context inputs is difficult for existing probe architectures. We propose several new probe architecture that handle this long-context distribution shift. We evaluate these probes in the cyber-offensive domain, testing their robustness against various production-relevant shifts, including multi-turn conversations, static jailbreaks, and adaptive red teaming. Our results demonstrate that while multimax addresses context length, a combination of architecture choice and training on diverse distributions is required for broad generalization. Additionally, we show that pairing probes with prompted classifiers achieves optimal accuracy at a low cost due to the computational efficiency of probes. These findings have informed the successful deployment of misuse mitigation probes in user-facing instances of Gemini, Google's frontier language model. Finally, we find early positive results using AlphaEvolve to automate improvements in both probe architecture search and adaptive red teaming, showing that automating some AI safety research is already possible.
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Aug 09, 2024



Sparse autoencoders (SAEs) are an unsupervised method for learning a sparse decomposition of a neural network's latent representations into seemingly interpretable features. Despite recent excitement about their potential, research applications outside of industry are limited by the high cost of training a comprehensive suite of SAEs. In this work, we introduce Gemma Scope, an open suite of JumpReLU SAEs trained on all layers and sub-layers of Gemma 2 2B and 9B and select layers of Gemma 2 27B base models. We primarily train SAEs on the Gemma 2 pre-trained models, but additionally release SAEs trained on instruction-tuned Gemma 2 9B for comparison. We evaluate the quality of each SAE on standard metrics and release these results. We hope that by releasing these SAE weights, we can help make more ambitious safety and interpretability research easier for the community. Weights and a tutorial can be found at https://huggingface.co/google/gemma-scope and an interactive demo can be found at https://www.neuronpedia.org/gemma-scope
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Jul 19, 2024



Sparse autoencoders (SAEs) are a promising unsupervised approach for identifying causally relevant and interpretable linear features in a language model's (LM) activations. To be useful for downstream tasks, SAEs need to decompose LM activations faithfully; yet to be interpretable the decomposition must be sparse -- two objectives that are in tension. In this paper, we introduce JumpReLU SAEs, which achieve state-of-the-art reconstruction fidelity at a given sparsity level on Gemma 2 9B activations, compared to other recent advances such as Gated and TopK SAEs. We also show that this improvement does not come at the cost of interpretability through manual and automated interpretability studies. JumpReLU SAEs are a simple modification of vanilla (ReLU) SAEs -- where we replace the ReLU with a discontinuous JumpReLU activation function -- and are similarly efficient to train and run. By utilising straight-through-estimators (STEs) in a principled manner, we show how it is possible to train JumpReLU SAEs effectively despite the discontinuous JumpReLU function introduced in the SAE's forward pass. Similarly, we use STEs to directly train L0 to be sparse, instead of training on proxies such as L1, avoiding problems like shrinkage.
On scalable oversight with weak LLMs judging strong LLMs
Jul 05, 2024



Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a judge; consultancy, where a single AI tries to convince a judge that asks questions; and compare to a baseline of direct question-answering, where the judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
Improving Dictionary Learning with Gated Sparse Autoencoders
Apr 30, 2024



Recent work has found that sparse autoencoders (SAEs) are an effective technique for unsupervised discovery of interpretable features in language models' (LMs) activations, by finding sparse, linear reconstructions of LM activations. We introduce the Gated Sparse Autoencoder (Gated SAE), which achieves a Pareto improvement over training with prevailing methods. In SAEs, the L1 penalty used to encourage sparsity introduces many undesirable biases, such as shrinkage -- systematic underestimation of feature activations. The key insight of Gated SAEs is to separate the functionality of (a) determining which directions to use and (b) estimating the magnitudes of those directions: this enables us to apply the L1 penalty only to the former, limiting the scope of undesirable side effects. Through training SAEs on LMs of up to 7B parameters we find that, in typical hyper-parameter ranges, Gated SAEs solve shrinkage, are similarly interpretable, and require half as many firing features to achieve comparable reconstruction fidelity.
AtP*: An efficient and scalable method for localizing LLM behaviour to components
Mar 01, 2024



Activation Patching is a method of directly computing causal attributions of behavior to model components. However, applying it exhaustively requires a sweep with cost scaling linearly in the number of model components, which can be prohibitively expensive for SoTA Large Language Models (LLMs). We investigate Attribution Patching (AtP), a fast gradient-based approximation to Activation Patching and find two classes of failure modes of AtP which lead to significant false negatives. We propose a variant of AtP called AtP*, with two changes to address these failure modes while retaining scalability. We present the first systematic study of AtP and alternative methods for faster activation patching and show that AtP significantly outperforms all other investigated methods, with AtP* providing further significant improvement. Finally, we provide a method to bound the probability of remaining false negatives of AtP* estimates.
Explaining grokking through circuit efficiency
Sep 05, 2023



One of the most surprising puzzles in neural network generalisation is grokking: a network with perfect training accuracy but poor generalisation will, upon further training, transition to perfect generalisation. We propose that grokking occurs when the task admits a generalising solution and a memorising solution, where the generalising solution is slower to learn but more efficient, producing larger logits with the same parameter norm. We hypothesise that memorising circuits become more inefficient with larger training datasets while generalising circuits do not, suggesting there is a critical dataset size at which memorisation and generalisation are equally efficient. We make and confirm four novel predictions about grokking, providing significant evidence in favour of our explanation. Most strikingly, we demonstrate two novel and surprising behaviours: ungrokking, in which a network regresses from perfect to low test accuracy, and semi-grokking, in which a network shows delayed generalisation to partial rather than perfect test accuracy.
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla
Jul 24, 2023



\emph{Circuit analysis} is a promising technique for understanding the internal mechanisms of language models. However, existing analyses are done in small models far from the state of the art. To address this, we present a case study of circuit analysis in the 70B Chinchilla model, aiming to test the scalability of circuit analysis. In particular, we study multiple-choice question answering, and investigate Chinchilla's capability to identify the correct answer \emph{label} given knowledge of the correct answer \emph{text}. We find that the existing techniques of logit attribution, attention pattern visualization, and activation patching naturally scale to Chinchilla, allowing us to identify and categorize a small set of `output nodes' (attention heads and MLPs). We further study the `correct letter' category of attention heads aiming to understand the semantics of their features, with mixed results. For normal multiple-choice question answers, we significantly compress the query, key and value subspaces of the head without loss of performance when operating on the answer labels for multiple-choice questions, and we show that the query and key subspaces represent an `Nth item in an enumeration' feature to at least some extent. However, when we attempt to use this explanation to understand the heads' behaviour on a more general distribution including randomized answer labels, we find that it is only a partial explanation, suggesting there is more to learn about the operation of `correct letter' heads on multiple choice question answering.
Tracr: Compiled Transformers as a Laboratory for Interpretability
Jan 12, 2023Interpretability research aims to build tools for understanding machine learning (ML) models. However, such tools are inherently hard to evaluate because we do not have ground truth information about how ML models actually work. In this work, we propose to build transformer models manually as a testbed for interpretability research. We introduce Tracr, a "compiler" for translating human-readable programs into weights of a transformer model. Tracr takes code written in RASP, a domain-specific language (Weiss et al. 2021), and translates it into weights for a standard, decoder-only, GPT-like transformer architecture. We use Tracr to create a range of ground truth transformers that implement programs including computing token frequencies, sorting, and Dyck-n parenthesis checking, among others. To enable the broader research community to explore and use compiled models, we provide an open-source implementation of Tracr at https://github.com/deepmind/tracr.
Learning to Play No-Press Diplomacy with Best Response Policy Iteration
Jun 17, 2020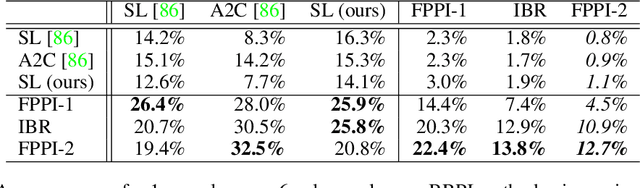
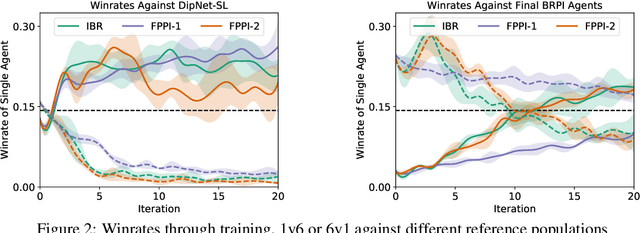
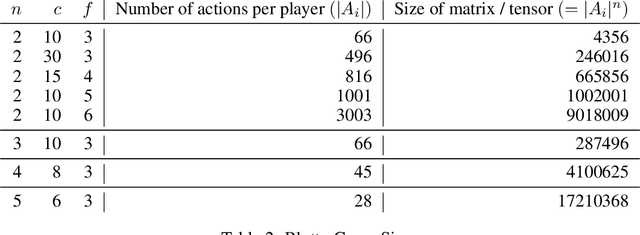
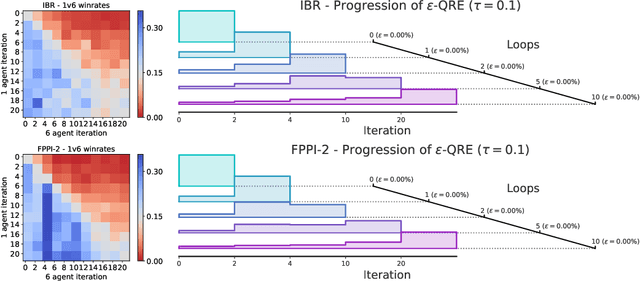
Recent advances in deep reinforcement learning (RL) have led to considerable progress in many 2-player zero-sum games, such as Go, Poker and Starcraft. The purely adversarial nature of such games allows for conceptually simple and principled application of RL methods. However real-world settings are many-agent, and agent interactions are complex mixtures of common-interest and competitive aspects. We consider Diplomacy, a 7-player board game designed to accentuate dilemmas resulting from many-agent interactions. It also features a large combinatorial action space and simultaneous moves, which are challenging for RL algorithms. We propose a simple yet effective approximate best response operator, designed to handle large combinatorial action spaces and simultaneous moves. We also introduce a family of policy iteration methods that approximate fictitious play. With these methods, we successfully apply RL to Diplomacy: we show that our agents convincingly outperform the previous state-of-the-art, and game theoretic equilibrium analysis shows that the new process yields consistent improvements.