 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePan More Gold from the Sand: Refining Open-domain Dialogue Training with Noisy Self-Retrieval Generation
Jan 27, 2022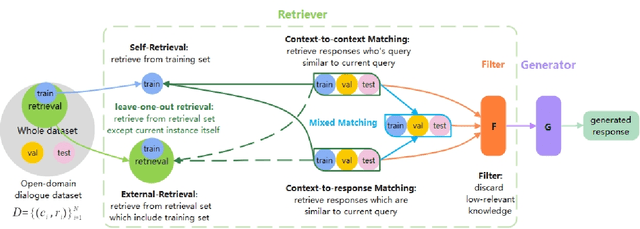
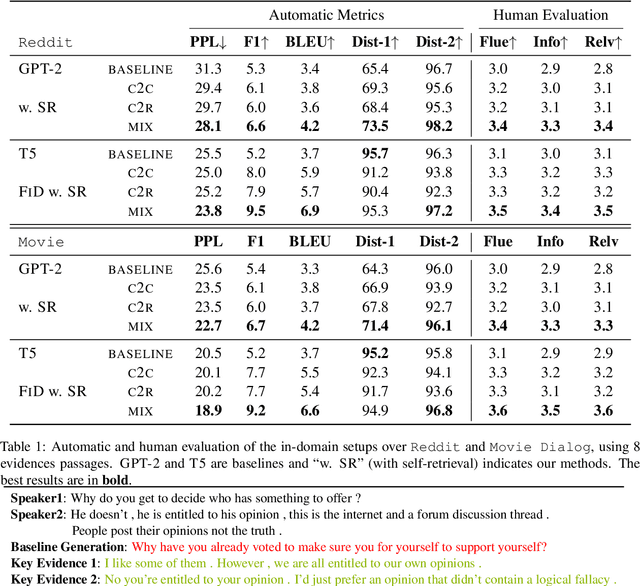
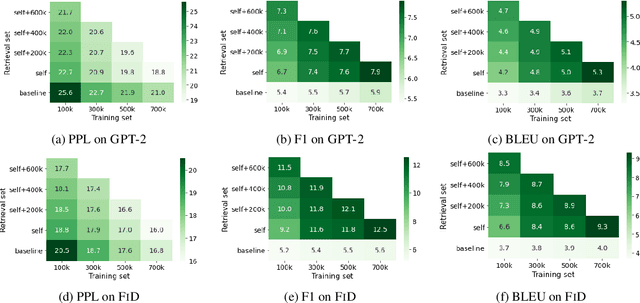
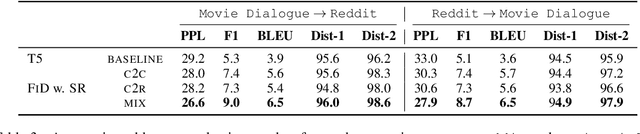
Real human conversation data are complicated, heterogeneous, and noisy, from whom building open-domain dialogue systems remains a challenging task. In fact, such dialogue data can still contain a wealth of information and knowledge, however, they are not fully explored. In this paper, we show existing open-domain dialogue generation methods by memorizing context-response paired data with causal or encode-decode language models underutilize the training data. Different from current approaches, using external knowledge, we explore a retrieval-generation training framework that can increase the usage of training data by directly considering the heterogeneous and noisy training data as the "evidence". Experiments over publicly available datasets demonstrate that our method can help models generate better responses, even such training data are usually impressed as low-quality data. Such performance gain is comparable with those improved by enlarging the training set, even better. We also found that the model performance has a positive correlation with the relevance of the retrieved evidence. Moreover, our method performed well on zero-shot experiments, which indicates that our method can be more robust to real-world data.
JABER and SABER: Junior and Senior Arabic BERt
Jan 09, 2022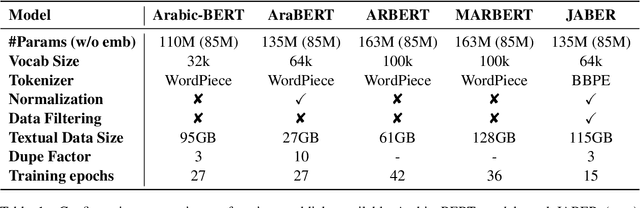
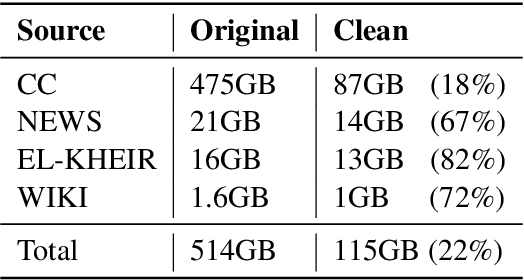
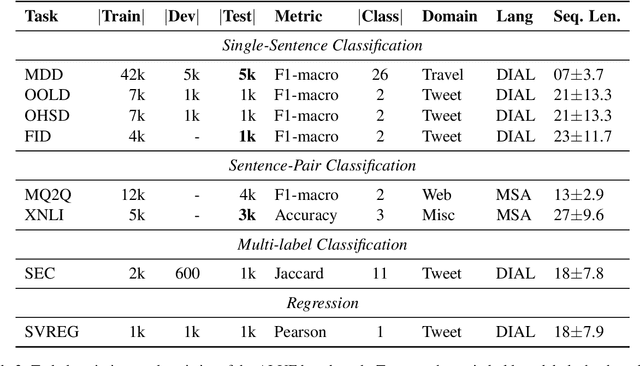
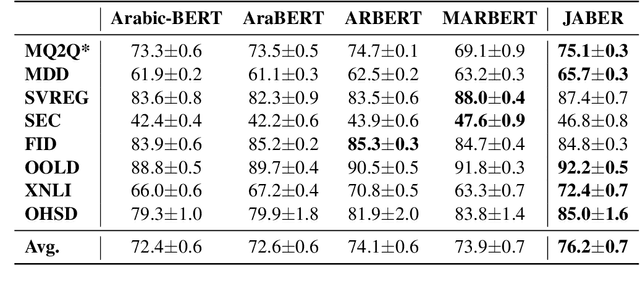
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.
LMTurk: Few-Shot Learners as Crowdsourcing Workers
Dec 14, 2021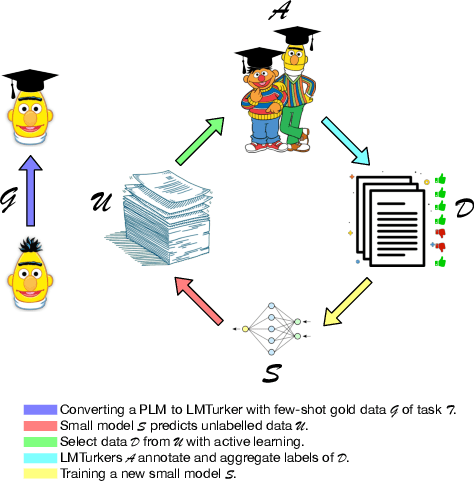
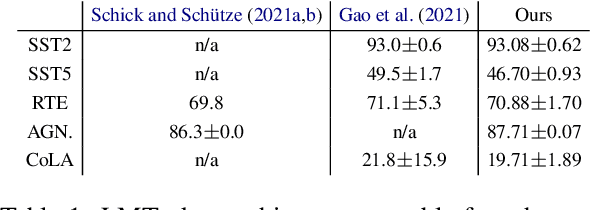
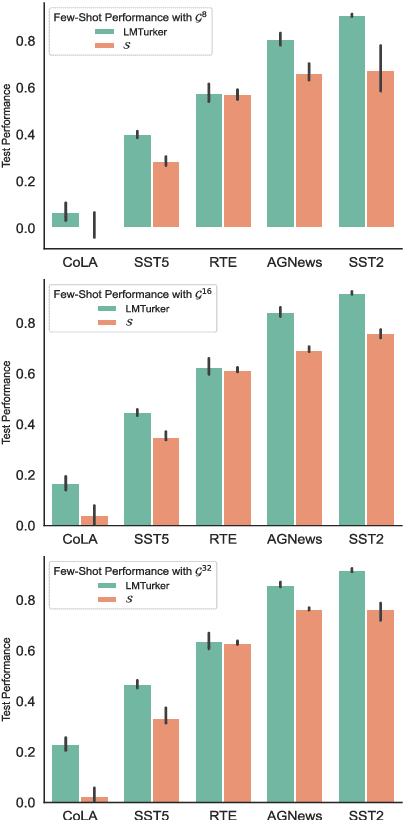
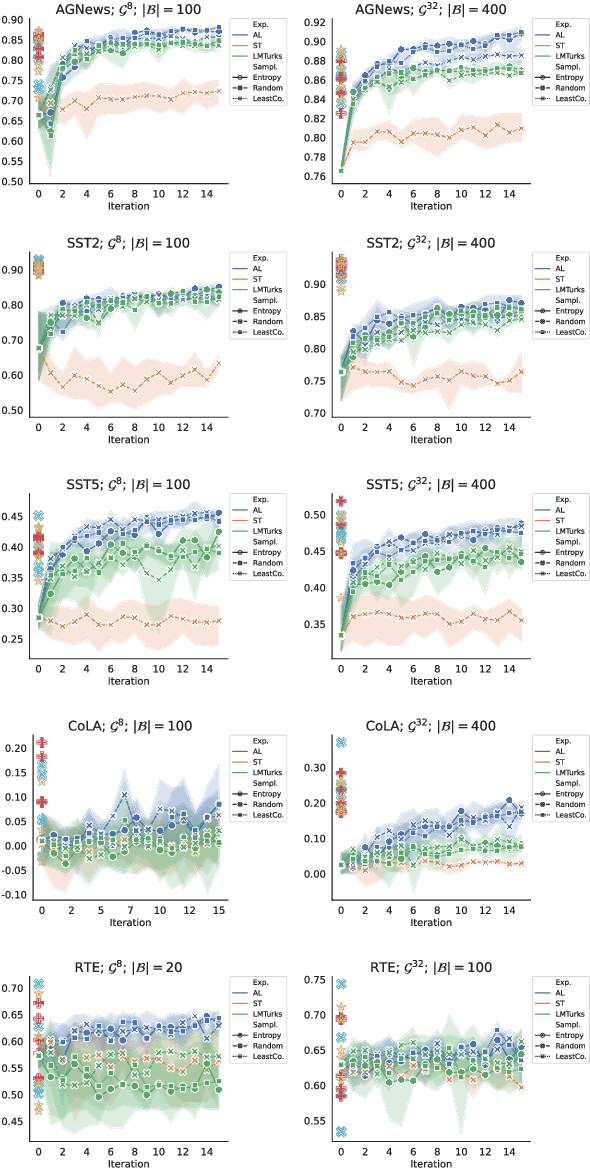
Vast efforts have been devoted to creating high-performance few-shot learners, i.e., models that perform well with little training data. Training large-scale pretrained language models (PLMs) has incurred significant cost, but utilizing PLM-based few-shot learners is still challenging due to their enormous size. This work focuses on a crucial question: How to make effective use of these few-shot learners? We propose LMTurk, a novel approach that treats few-shot learners as crowdsourcing workers. The rationale is that crowdsourcing workers are in fact few-shot learners: They are shown a few illustrative examples to learn about a task and then start annotating. LMTurk employs few-shot learners built upon PLMs as workers. We show that the resulting annotations can be utilized to train models that solve the task well and are small enough to be deployable in practical scenarios. Altogether, LMTurk is an important step towards making effective use of current PLM-based few-shot learners.
Towards Improving Embedding Based Models of Social Network Alignment via Pseudo Anchors
Nov 22, 2021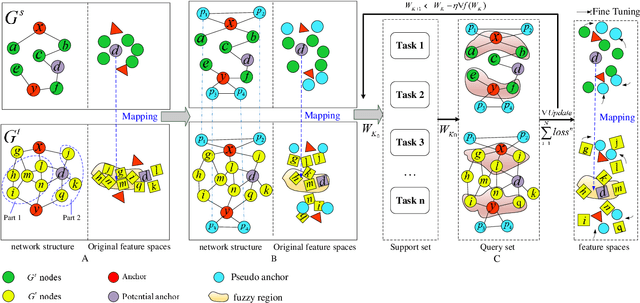
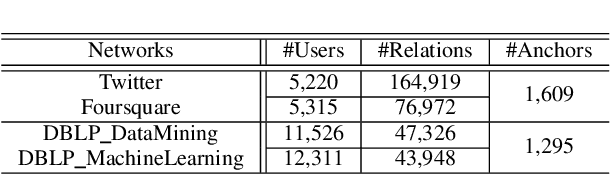
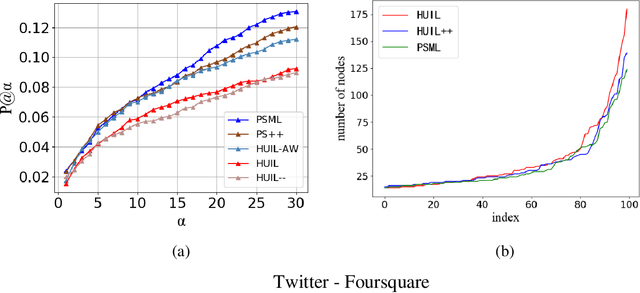
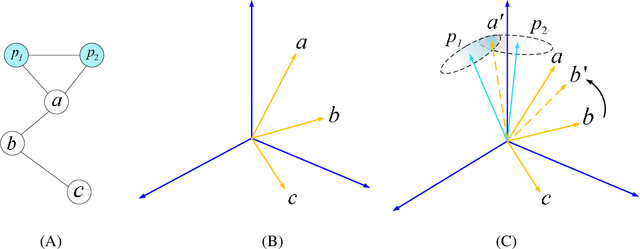
Social network alignment aims at aligning person identities across social networks. Embedding based models have been shown effective for the alignment where the structural proximity preserving objective is typically adopted for the model training. With the observation that ``overly-close'' user embeddings are unavoidable for such models causing alignment inaccuracy, we propose a novel learning framework which tries to enforce the resulting embeddings to be more widely apart among the users via the introduction of carefully implanted pseudo anchors. We further proposed a meta-learning algorithm to guide the updating of the pseudo anchor embeddings during the learning process. The proposed intervention via the use of pseudo anchors and meta-learning allows the learning framework to be applicable to a wide spectrum of network alignment methods. We have incorporated the proposed learning framework into several state-of-the-art models. Our experimental results demonstrate its efficacy where the methods with the pseudo anchors implanted can outperform their counterparts without pseudo anchors by a fairly large margin, especially when there only exist very few labeled anchors.
CCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis
Nov 16, 2021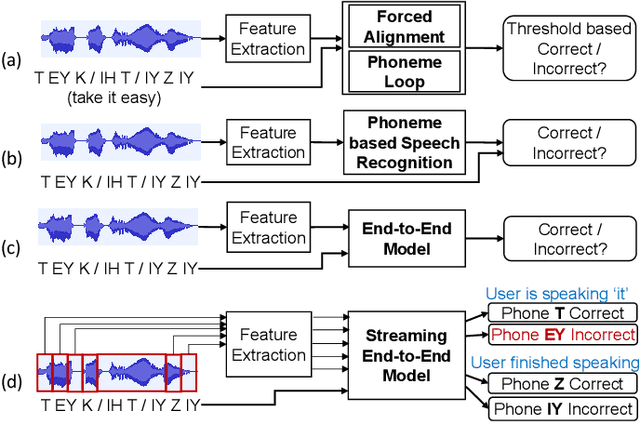
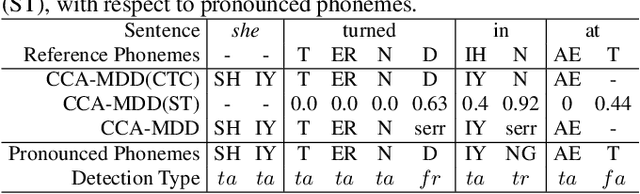
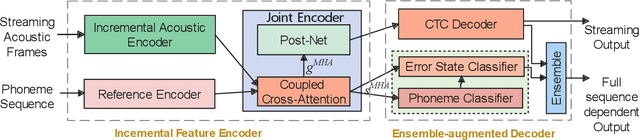

End-to-end models are becoming popular approaches for mispronunciation detection and diagnosis (MDD). A streaming MDD framework which is demanded by many practical applications still remains a challenge. This paper proposes a streaming end-to-end MDD framework called CCA-MDD. CCA-MDD supports online processing and is able to run strictly in real-time. The encoder of CCA-MDD consists of a conv-Transformer network based streaming acoustic encoder and an improved cross-attention named coupled cross-attention (CCA). The coupled cross-attention integrates encoded acoustic features with pre-encoded linguistic features. An ensemble of decoders trained from multi-task learning is applied for final MDD decision. Experiments on publicly available corpora demonstrate that CCA-MDD achieves comparable performance to published offline end-to-end MDD models.
UniDS: A Unified Dialogue System for Chit-Chat and Task-oriented Dialogues
Oct 15, 2021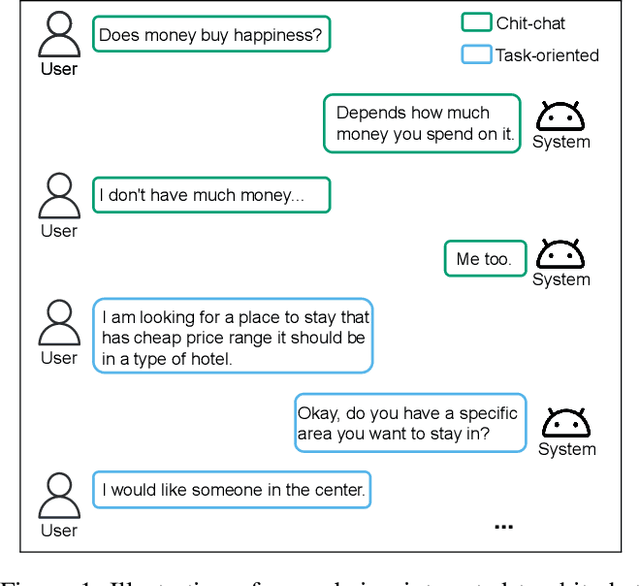

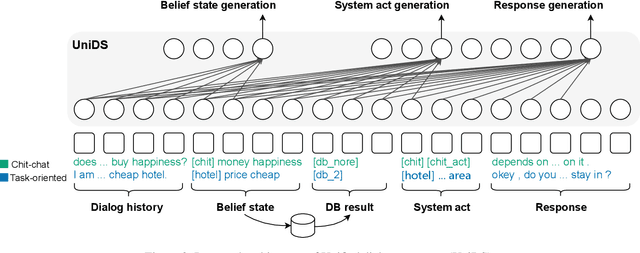
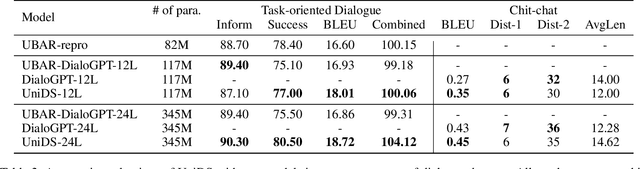
With the advances in deep learning, tremendous progress has been made with chit-chat dialogue systems and task-oriented dialogue systems. However, these two systems are often tackled separately in current methods. To achieve more natural interaction with humans, a dialogue agent needs to be capable of both chatting and accomplishing tasks. To this end, we propose a unified dialogue system (UniDS) with the two aforementioned skills. In particular, we design a unified dialogue data schema, compatible for both chit-chat and task-oriented dialogues, and we train UniDS with mixed dialogue data from a pretrained chit-chat dialogue model. Without adding extra parameters to SOTA baselines, UniDS can alternatively handle chit-chat and task-oriented dialogues in a unified framework. Experimental results demonstrate that the proposed UniDS works comparably well as the pure chit-chat system, and it outperforms state-of-the-art task-oriented dialogue systems. More importantly, UniDS achieves better robustness as it is able to smoothly switch between two types of dialogues. These results demonstrate the feasibility and potential of building an one-for-all dialogue system.
bert2BERT: Towards Reusable Pretrained Language Models
Oct 14, 2021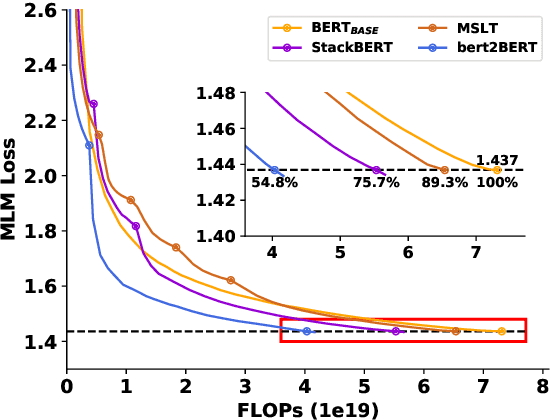
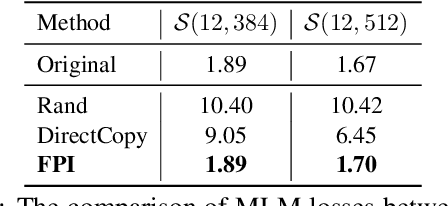
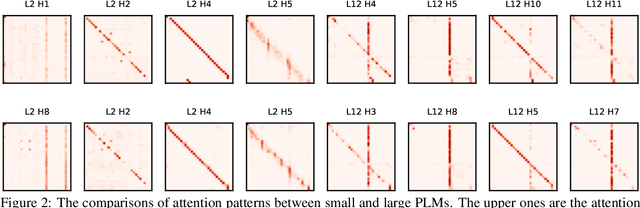
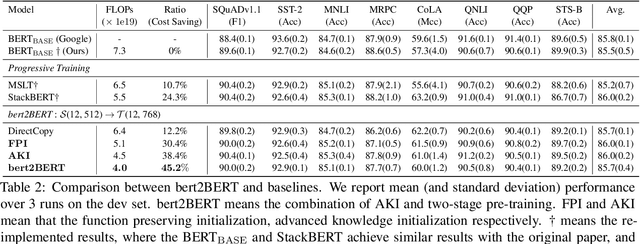
In recent years, researchers tend to pre-train ever-larger language models to explore the upper limit of deep models. However, large language model pre-training costs intensive computational resources and most of the models are trained from scratch without reusing the existing pre-trained models, which is wasteful. In this paper, we propose bert2BERT, which can effectively transfer the knowledge of an existing smaller pre-trained model (e.g., BERT_BASE) to a large model (e.g., BERT_LARGE) through parameter initialization and significantly improve the pre-training efficiency of the large model. Specifically, we extend the previous function-preserving on Transformer-based language model, and further improve it by proposing advanced knowledge for large model's initialization. In addition, a two-stage pre-training method is proposed to further accelerate the training process. We did extensive experiments on representative PLMs (e.g., BERT and GPT) and demonstrate that (1) our method can save a significant amount of training cost compared with baselines including learning from scratch, StackBERT and MSLT; (2) our method is generic and applicable to different types of pre-trained models. In particular, bert2BERT saves about 45% and 47% computational cost of pre-training BERT_BASE and GPT_BASE by reusing the models of almost their half sizes. The source code will be publicly available upon publication.
Multi-Semantic Image Recognition Model and Evaluating Index for explaining the deep learning models
Sep 28, 2021
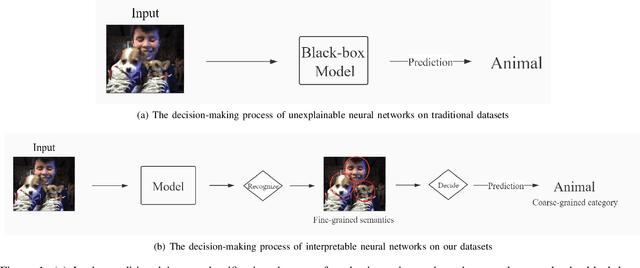
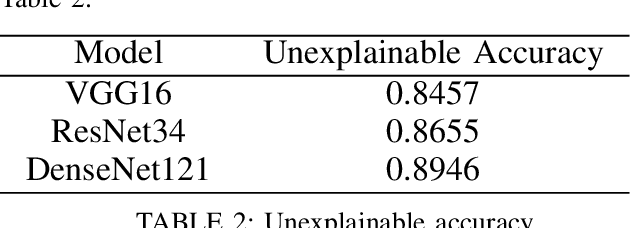
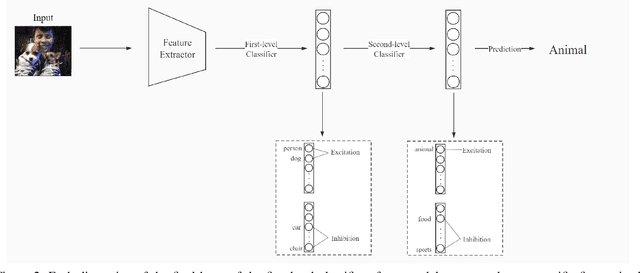
Although deep learning models are powerful among various applications, most deep learning models are still a black box, lacking verifiability and interpretability, which means the decision-making process that human beings cannot understand. Therefore, how to evaluate deep neural networks with explanations is still an urgent task. In this paper, we first propose a multi-semantic image recognition model, which enables human beings to understand the decision-making process of the neural network. Then, we presents a new evaluation index, which can quantitatively assess the model interpretability. We also comprehensively summarize the semantic information that affects the image classification results in the judgment process of neural networks. Finally, this paper also exhibits the relevant baseline performance with current state-of-the-art deep learning models.
DyLex: Incorporating Dynamic Lexicons into BERT for Sequence Labeling
Sep 22, 2021

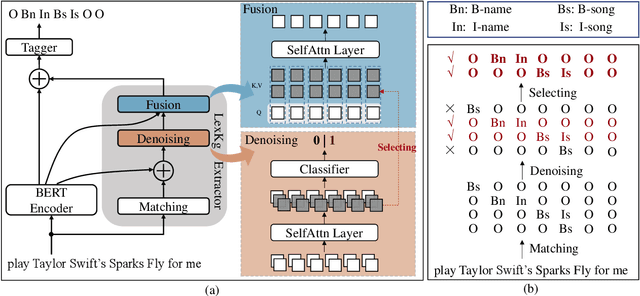
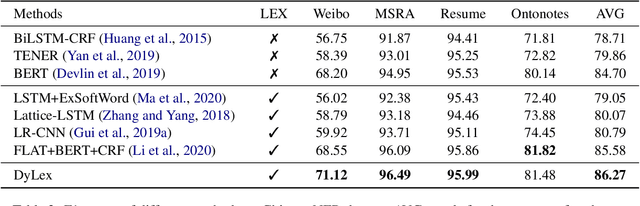
Incorporating lexical knowledge into deep learning models has been proved to be very effective for sequence labeling tasks. However, previous works commonly have difficulty dealing with large-scale dynamic lexicons which often cause excessive matching noise and problems of frequent updates. In this paper, we propose DyLex, a plug-in lexicon incorporation approach for BERT based sequence labeling tasks. Instead of leveraging embeddings of words in the lexicon as in conventional methods, we adopt word-agnostic tag embeddings to avoid re-training the representation while updating the lexicon. Moreover, we employ an effective supervised lexical knowledge denoising method to smooth out matching noise. Finally, we introduce a col-wise attention based knowledge fusion mechanism to guarantee the pluggability of the proposed framework. Experiments on ten datasets of three tasks show that the proposed framework achieves new SOTA, even with very large scale lexicons.
Improving Unsupervised Question Answering via Summarization-Informed Question Generation
Sep 16, 2021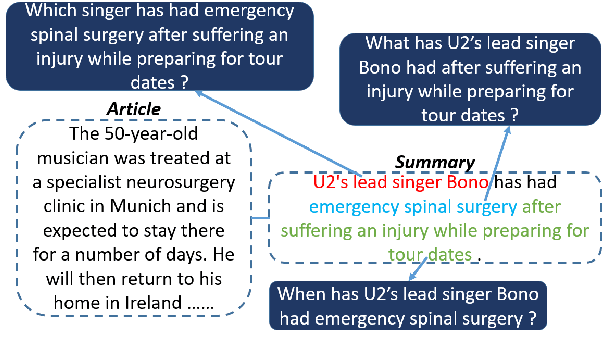
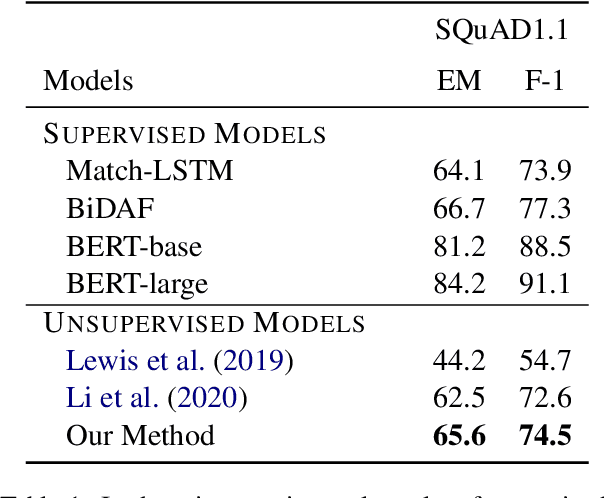
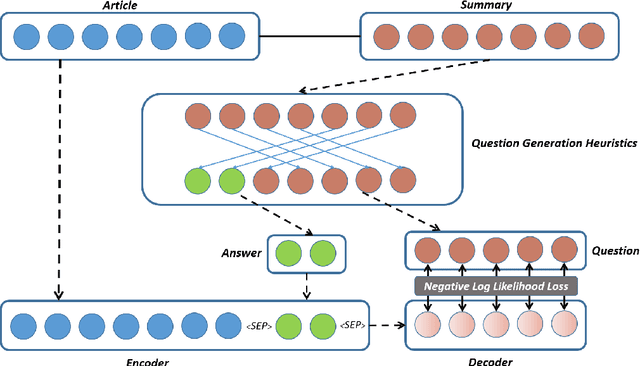
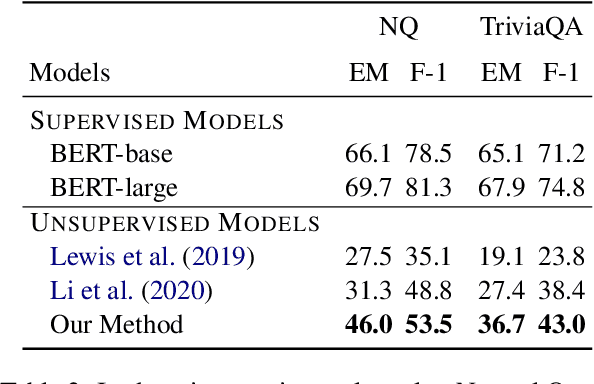
Question Generation (QG) is the task of generating a plausible question for a given <passage, answer> pair. Template-based QG uses linguistically-informed heuristics to transform declarative sentences into interrogatives, whereas supervised QG uses existing Question Answering (QA) datasets to train a system to generate a question given a passage and an answer. A disadvantage of the heuristic approach is that the generated questions are heavily tied to their declarative counterparts. A disadvantage of the supervised approach is that they are heavily tied to the domain/language of the QA dataset used as training data. In order to overcome these shortcomings, we propose an unsupervised QG method which uses questions generated heuristically from summaries as a source of training data for a QG system. We make use of freely available news summary data, transforming declarative summary sentences into appropriate questions using heuristics informed by dependency parsing, named entity recognition and semantic role labeling. The resulting questions are then combined with the original news articles to train an end-to-end neural QG model. We extrinsically evaluate our approach using unsupervised QA: our QG model is used to generate synthetic QA pairs for training a QA model. Experimental results show that, trained with only 20k English Wikipedia-based synthetic QA pairs, the QA model substantially outperforms previous unsupervised models on three in-domain datasets (SQuAD1.1, Natural Questions, TriviaQA) and three out-of-domain datasets (NewsQA, BioASQ, DuoRC), demonstrating the transferability of the approach.