 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Data Mixture for Large Language Models: A Comprehensive Survey and New Perspectives
May 27, 2025Training large language models with data collected from various domains can improve their performance on downstream tasks. However, given a fixed training budget, the sampling proportions of these different domains significantly impact the model's performance. How can we determine the domain weights across different data domains to train the best-performing model within constrained computational resources? In this paper, we provide a comprehensive overview of existing data mixture methods. First, we propose a fine-grained categorization of existing methods, extending beyond the previous offline and online classification. Offline methods are further grouped into heuristic-based, algorithm-based, and function fitting-based methods. For online methods, we categorize them into three groups: online min-max optimization, online mixing law, and other approaches by drawing connections with the optimization frameworks underlying offline methods. Second, we summarize the problem formulations, representative algorithms for each subtype of offline and online methods, and clarify the relationships and distinctions among them. Finally, we discuss the advantages and disadvantages of each method and highlight key challenges in the field of data mixture.
UniDS: A Unified Dialogue System for Chit-Chat and Task-oriented Dialogues
Oct 15, 2021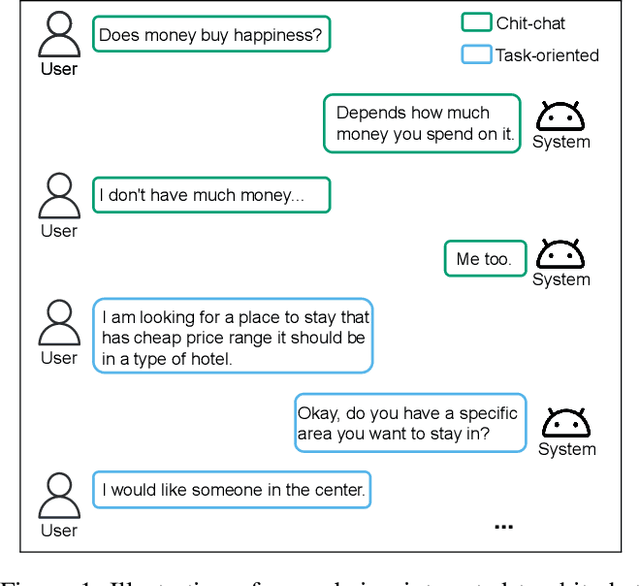

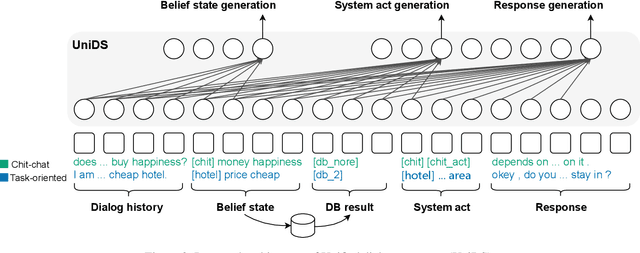
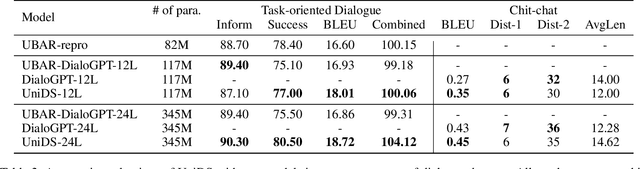
With the advances in deep learning, tremendous progress has been made with chit-chat dialogue systems and task-oriented dialogue systems. However, these two systems are often tackled separately in current methods. To achieve more natural interaction with humans, a dialogue agent needs to be capable of both chatting and accomplishing tasks. To this end, we propose a unified dialogue system (UniDS) with the two aforementioned skills. In particular, we design a unified dialogue data schema, compatible for both chit-chat and task-oriented dialogues, and we train UniDS with mixed dialogue data from a pretrained chit-chat dialogue model. Without adding extra parameters to SOTA baselines, UniDS can alternatively handle chit-chat and task-oriented dialogues in a unified framework. Experimental results demonstrate that the proposed UniDS works comparably well as the pure chit-chat system, and it outperforms state-of-the-art task-oriented dialogue systems. More importantly, UniDS achieves better robustness as it is able to smoothly switch between two types of dialogues. These results demonstrate the feasibility and potential of building an one-for-all dialogue system.