 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEDN: A Hard-Easy Dual Network with Task Difficulty Assessment for EEG Emotion Recognition
Nov 10, 2025Multi-source domain adaptation represents an effective approach to addressing individual differences in cross-subject EEG emotion recognition. However, existing methods treat all source domains equally, neglecting the varying transfer difficulties between different source domains and the target domain. This oversight can lead to suboptimal adaptation. To address this challenge, we propose a novel Hard-Easy Dual Network (HEDN), which dynamically identifies "Hard Source" and "Easy Source" through a Task Difficulty Assessment (TDA) mechanism and establishes two specialized knowledge adaptation branches. Specifically, the Hard Network is dedicated to handling "Hard Source" with higher transfer difficulty by aligning marginal distribution differences between source and target domains. Conversely, the Easy Network focuses on "Easy Source" with low transfer difficulty, utilizing a prototype classifier to model intra-class clustering structures while generating reliable pseudo-labels for the target domain through a prototype-guided label propagation algorithm. Extensive experiments on two benchmark datasets, SEED and SEED-IV, demonstrate that HEDN achieves state-of-the-art performance in cross-subject EEG emotion recognition, with average accuracies of 93.58\% on SEED and 79.82\% on SEED-IV, respectively. These results confirm the effectiveness and generalizability of HEDN in cross-subject EEG emotion recognition.
SIM-Assisted End-to-End Co-Frequency Co-Time Full-Duplex System
Oct 31, 2025



To further suppress the inherent self-interference (SI) in co-frequency and co-time full-duplex (CCFD) systems, we propose integrating a stacked intelligent metasurface (SIM) into the RF front-end to enhance signal processing in the wave domain. Furthermore, an end-to-end (E2E) learning-based signal processing method is adopted to control the metasurface. Specifically, the real metasurface is abstracted as hidden layers of a network, thereby constructing an electromagnetic neural network (EMNN) to enable driving control of the real communication system. Traditional communication tasks, such as channel coding, modulation, precoding, combining, demodulation, and channel decoding, are synchronously carried out during the electromagnetic (EM) forward propagation through the metasurface. Simulation results show that, benefiting from the additional wave-domain processing capability of the SIM, the SIM-assisted CCFD system achieves significantly reduced bit error rate (BER) compared with conventional CCFD systems. Our study fully demonstrates the potential applications of EMNN and SIM-assisted E2E CCFD systems in next-generation transceiver design.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
PA-HOI: A Physics-Aware Human and Object Interaction Dataset
Aug 08, 2025



The Human-Object Interaction (HOI) task explores the dynamic interactions between humans and objects in physical environments, providing essential biomechanical and cognitive-behavioral foundations for fields such as robotics, virtual reality, and human-computer interaction. However, existing HOI data sets focus on details of affordance, often neglecting the influence of physical properties of objects on human long-term motion. To bridge this gap, we introduce the PA-HOI Motion Capture dataset, which highlights the impact of objects' physical attributes on human motion dynamics, including human posture, moving velocity, and other motion characteristics. The dataset comprises 562 motion sequences of human-object interactions, with each sequence performed by subjects of different genders interacting with 35 3D objects that vary in size, shape, and weight. This dataset stands out by significantly extending the scope of existing ones for understanding how the physical attributes of different objects influence human posture, speed, motion scale, and interacting strategies. We further demonstrate the applicability of the PA-HOI dataset by integrating it with existing motion generation methods, validating its capacity to transfer realistic physical awareness.
FantasyPortrait: Enhancing Multi-Character Portrait Animation with Expression-Augmented Diffusion Transformers
Jul 17, 2025Producing expressive facial animations from static images is a challenging task. Prior methods relying on explicit geometric priors (e.g., facial landmarks or 3DMM) often suffer from artifacts in cross reenactment and struggle to capture subtle emotions. Furthermore, existing approaches lack support for multi-character animation, as driving features from different individuals frequently interfere with one another, complicating the task. To address these challenges, we propose FantasyPortrait, a diffusion transformer based framework capable of generating high-fidelity and emotion-rich animations for both single- and multi-character scenarios. Our method introduces an expression-augmented learning strategy that utilizes implicit representations to capture identity-agnostic facial dynamics, enhancing the model's ability to render fine-grained emotions. For multi-character control, we design a masked cross-attention mechanism that ensures independent yet coordinated expression generation, effectively preventing feature interference. To advance research in this area, we propose the Multi-Expr dataset and ExprBench, which are specifically designed datasets and benchmarks for training and evaluating multi-character portrait animations. Extensive experiments demonstrate that FantasyPortrait significantly outperforms state-of-the-art methods in both quantitative metrics and qualitative evaluations, excelling particularly in challenging cross reenactment and multi-character contexts. Our project page is https://fantasy-amap.github.io/fantasy-portrait/.
RA-NeRF: Robust Neural Radiance Field Reconstruction with Accurate Camera Pose Estimation under Complex Trajectories
Jun 18, 2025



Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have emerged as powerful tools for 3D reconstruction and SLAM tasks. However, their performance depends heavily on accurate camera pose priors. Existing approaches attempt to address this issue by introducing external constraints but fall short of achieving satisfactory accuracy, particularly when camera trajectories are complex. In this paper, we propose a novel method, RA-NeRF, capable of predicting highly accurate camera poses even with complex camera trajectories. Following the incremental pipeline, RA-NeRF reconstructs the scene using NeRF with photometric consistency and incorporates flow-driven pose regulation to enhance robustness during initialization and localization. Additionally, RA-NeRF employs an implicit pose filter to capture the camera movement pattern and eliminate the noise for pose estimation. To validate our method, we conduct extensive experiments on the Tanks\&Temple dataset for standard evaluation, as well as the NeRFBuster dataset, which presents challenging camera pose trajectories. On both datasets, RA-NeRF achieves state-of-the-art results in both camera pose estimation and visual quality, demonstrating its effectiveness and robustness in scene reconstruction under complex pose trajectories.
OneRec Technical Report
Jun 16, 2025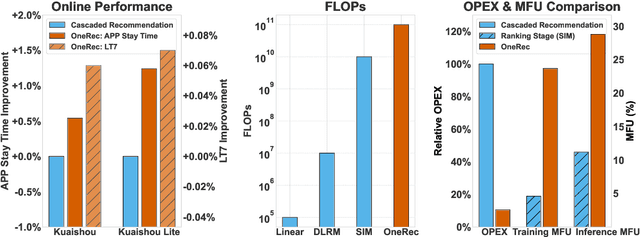

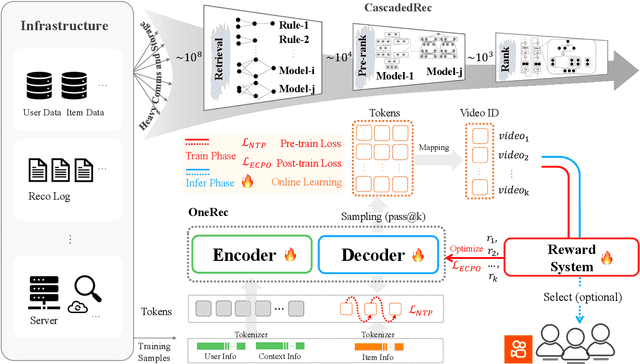
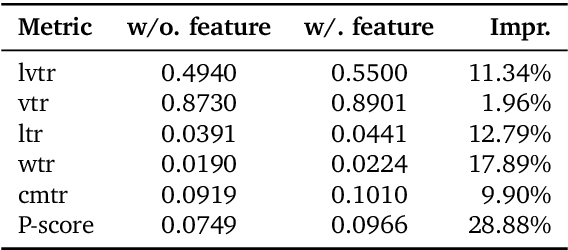
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Boosting Domain Incremental Learning: Selecting the Optimal Parameters is All You Need
May 29, 2025Deep neural networks (DNNs) often underperform in real-world, dynamic settings where data distributions change over time. Domain Incremental Learning (DIL) offers a solution by enabling continual model adaptation, with Parameter-Isolation DIL (PIDIL) emerging as a promising paradigm to reduce knowledge conflicts. However, existing PIDIL methods struggle with parameter selection accuracy, especially as the number of domains and corresponding classes grows. To address this, we propose SOYO, a lightweight framework that improves domain selection in PIDIL. SOYO introduces a Gaussian Mixture Compressor (GMC) and Domain Feature Resampler (DFR) to store and balance prior domain data efficiently, while a Multi-level Domain Feature Fusion Network (MDFN) enhances domain feature extraction. Our framework supports multiple Parameter-Efficient Fine-Tuning (PEFT) methods and is validated across tasks such as image classification, object detection, and speech enhancement. Experimental results on six benchmarks demonstrate SOYO's consistent superiority over existing baselines, showcasing its robustness and adaptability in complex, evolving environments. The codes will be released in https://github.com/qwangcv/SOYO.
Learning A Robust RGB-Thermal Detector for Extreme Modality Imbalance
May 28, 2025RGB-Thermal (RGB-T) object detection utilizes thermal infrared (TIR) images to complement RGB data, improving robustness in challenging conditions. Traditional RGB-T detectors assume balanced training data, where both modalities contribute equally. However, in real-world scenarios, modality degradation-due to environmental factors or technical issues-can lead to extreme modality imbalance, causing out-of-distribution (OOD) issues during testing and disrupting model convergence during training. This paper addresses these challenges by proposing a novel base-and-auxiliary detector architecture. We introduce a modality interaction module to adaptively weigh modalities based on their quality and handle imbalanced samples effectively. Additionally, we leverage modality pseudo-degradation to simulate real-world imbalances in training data. The base detector, trained on high-quality pairs, provides a consistency constraint for the auxiliary detector, which receives degraded samples. This framework enhances model robustness, ensuring reliable performance even under severe modality degradation. Experimental results demonstrate the effectiveness of our method in handling extreme modality imbalances~(decreasing the Missing Rate by 55%) and improving performance across various baseline detectors.
Dual-Polarization Stacked Intelligent Metasurfaces for Holographic MIMO
May 27, 2025To address the limited wave domain signal processing capabilities of traditional single-polarized stacked intelligent metasurfaces (SIMs) in holographic multiple-input multiple-output (HMIMO) systems, which stems from limited integration space, this paper proposes a dual-polarized SIM (DPSIM) architecture. By stacking dual-polarized reconfigurable intelligent surfaces (DPRIS), DPSIM can independently process signals of two orthogonal polarizations in the wave domain, thereby effectively suppressing polarization cross-interference (PCI) and inter-stream interference (ISI). We introduce a layer-by-layer gradient descent with water-filling (LGD-WF) algorithm to enhance end-to-end performance. Simulation results show that, under the same number of metasurface layers and unit size, the DPSIM-aided HMIMO system can support more simultaneous data streams for ISI-free parallel transmission compared to traditional SIM-aided systems. Furthermore, under different polarization imperfection conditions, both the spectral efficiency (SE) and energy efficiency (EE) of the DPSIM-aided HMIMO system are significantly improved, approaching the theoretical upper bound.