 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Forgetting Learning: Memory-free Continual Learning
Mar 07, 2025



Continual Learning (CL) remains a central challenge in deep learning, where models must sequentially acquire new knowledge while mitigating Catastrophic Forgetting (CF) of prior tasks. Existing approaches often struggle with efficiency and scalability, requiring extensive memory or model buffers. This work introduces ``No Forgetting Learning" (NFL), a memory-free CL framework that leverages knowledge distillation to maintain stability while preserving plasticity. Memory-free means the NFL does not rely on any memory buffer. Through extensive evaluations of three benchmark datasets, we demonstrate that NFL achieves competitive performance while utilizing approximately 14.75 times less memory than state-of-the-art methods. Furthermore, we introduce a new metric to better assess CL's plasticity-stability trade-off.
Better Process Supervision with Bi-directional Rewarding Signals
Mar 06, 2025Process supervision, i.e., evaluating each step, is critical for complex large language model (LLM) reasoning and test-time searching with increased inference compute. Existing approaches, represented by process reward models (PRMs), primarily focus on rewarding signals up to the current step, exhibiting a one-directional nature and lacking a mechanism to model the distance to the final target. To address this problem, we draw inspiration from the A* algorithm, which states that an effective supervisory signal should simultaneously consider the incurred cost and the estimated cost for reaching the target. Building on this key insight, we introduce BiRM, a novel process supervision model that not only evaluates the correctness of previous steps but also models the probability of future success. We conduct extensive experiments on mathematical reasoning tasks and demonstrate that BiRM provides more precise evaluations of LLM reasoning steps, achieving an improvement of 3.1% on Gaokao2023 over PRM under the Best-of-N sampling method. Besides, in search-based strategies, BiRM provides more comprehensive guidance and outperforms ORM by 5.0% and PRM by 3.8% respectively on MATH-500.
MindSimulator: Exploring Brain Concept Localization via Synthetic FMRI
Mar 04, 2025



Concept-selective regions within the human cerebral cortex exhibit significant activation in response to specific visual stimuli associated with particular concepts. Precisely localizing these regions stands as a crucial long-term goal in neuroscience to grasp essential brain functions and mechanisms. Conventional experiment-driven approaches hinge on manually constructed visual stimulus collections and corresponding brain activity recordings, constraining the support and coverage of concept localization. Additionally, these stimuli often consist of concept objects in unnatural contexts and are potentially biased by subjective preferences, thus prompting concerns about the validity and generalizability of the identified regions. To address these limitations, we propose a data-driven exploration approach. By synthesizing extensive brain activity recordings, we statistically localize various concept-selective regions. Our proposed MindSimulator leverages advanced generative technologies to learn the probability distribution of brain activity conditioned on concept-oriented visual stimuli. This enables the creation of simulated brain recordings that reflect real neural response patterns. Using the synthetic recordings, we successfully localize several well-studied concept-selective regions and validate them against empirical findings, achieving promising prediction accuracy. The feasibility opens avenues for exploring novel concept-selective regions and provides prior hypotheses for future neuroscience research.
PASemiQA: Plan-Assisted Agent for Question Answering on Semi-Structured Data with Text and Relational Information
Feb 28, 2025Large language models (LLMs) have shown impressive abilities in answering questions across various domains, but they often encounter hallucination issues on questions that require professional and up-to-date knowledge. To address this limitation, retrieval-augmented generation (RAG) techniques have been proposed, which retrieve relevant information from external sources to inform their responses. However, existing RAG methods typically focus on a single type of external data, such as vectorized text database or knowledge graphs, and cannot well handle real-world questions on semi-structured data containing both text and relational information. To bridge this gap, we introduce PASemiQA, a novel approach that jointly leverages text and relational information in semi-structured data to answer questions. PASemiQA first generates a plan to identify relevant text and relational information to answer the question in semi-structured data, and then uses an LLM agent to traverse the semi-structured data and extract necessary information. Our empirical results demonstrate the effectiveness of PASemiQA across different semi-structured datasets from various domains, showcasing its potential to improve the accuracy and reliability of question answering systems on semi-structured data.
Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones?
Feb 26, 2025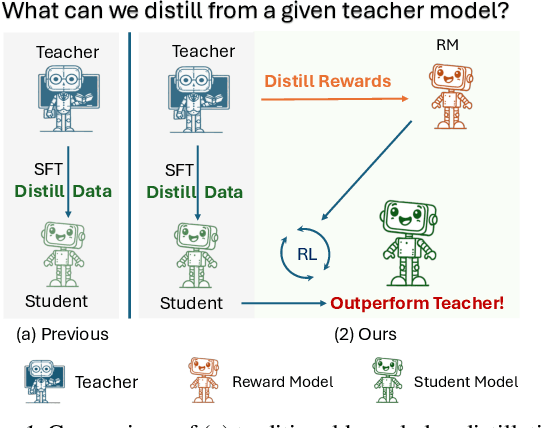

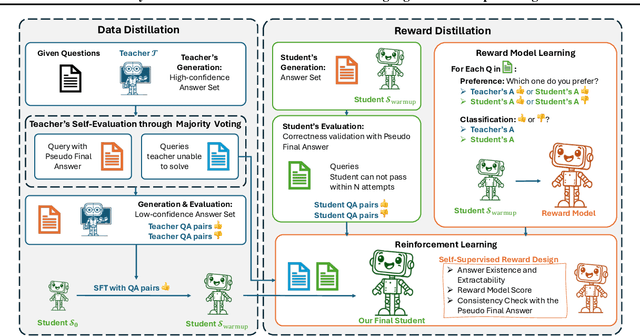
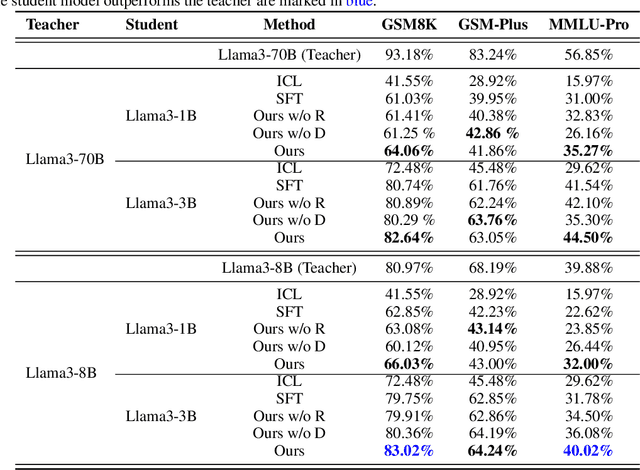
Distilling large language models (LLMs) typically involves transferring the teacher model's responses through supervised fine-tuning (SFT). However, this approach neglects the potential to distill both data (output content) and reward signals (quality evaluations). Extracting reliable reward signals directly from teacher models is challenging, as LLMs are optimized for generation rather than evaluation, often resulting in biased or inconsistent assessments. To address this limitation, we propose a novel distillation pipeline that transfers both responses and rewards. Our method generates pseudo-rewards through a self-supervised mechanism that leverages the inherent structure of both teacher and student responses, enabling reward learning without explicit external evaluation. The reward model subsequently guides reinforcement learning (RL), allowing iterative refinement of the student model after an SFT warm-up phase. Experiments on GSM8K and MMLU-PRO demonstrate that our method consistently outperforms traditional SFT-based approaches, enabling student models to surpass the performance of their teachers. This work highlights the potential for scalable, efficient distillation through structured self-supervised reward learning, reducing dependence on external reward supervision.
VEM: Environment-Free Exploration for Training GUI Agent with Value Environment Model
Feb 26, 2025



Training Vision-Language Models (VLMs) for Graphical User Interfaces (GUI) agents via Reinforcement Learning (RL) faces critical challenges: environment-based RL requires costly interactions, while environment-free methods struggle with distribution shift and reward generalization. We propose an environment-free RL framework that decouples value estimation from policy optimization by leveraging a pretrained Value Environment Model (VEM). VEM predicts state-action values directly from offline data, distilling human-like priors about GUI interaction outcomes without requiring next-state prediction or environmental feedback. This avoids compounding errors and enhances resilience to UI changes by focusing on semantic reasoning (e.g., Does this action advance the user's goal?). The framework operates in two stages: (1) pretraining VEM to estimate long-term action utilities and (2) guiding policy exploration with frozen VEM signals, enabling layout-agnostic GUI automation. Evaluated on Android-in-the-Wild benchmarks, VEM achieves state-of-the-art performance in both offline and online settings, outperforming environment-free baselines significantly and matching environment-based approaches without interaction costs. Importantly, VEM demonstrates that semantic-aware value estimation can achieve comparable performance with online-trained methods.
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric
Feb 25, 2025



Data diversity is crucial for the instruction tuning of large language models. Existing studies have explored various diversity-aware data selection methods to construct high-quality datasets and enhance model performance. However, the fundamental problem of precisely defining and measuring data diversity remains underexplored, limiting clear guidance for data engineering. To address this, we systematically analyze 11 existing diversity measurement methods by evaluating their correlation with model performance through extensive fine-tuning experiments. Our results indicate that a reliable diversity measure should properly account for both inter-sample differences and the information distribution in the sample space. Building on this, we propose NovelSum, a new diversity metric based on sample-level "novelty." Experiments on both simulated and real-world data show that NovelSum accurately captures diversity variations and achieves a 0.97 correlation with instruction-tuned model performance, highlighting its value in guiding data engineering practices. With NovelSum as an optimization objective, we further develop a greedy, diversity-oriented data selection strategy that outperforms existing approaches, validating both the effectiveness and practical significance of our metric.
Lean and Mean: Decoupled Value Policy Optimization with Global Value Guidance
Feb 24, 2025Proximal Policy Optimization (PPO)-based Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human preferences. It requires joint training of an actor and critic with a pretrained, fixed reward model for guidance. This approach increases computational complexity and instability due to actor-critic interdependence. Additionally, PPO lacks access to true environment rewards in LLM tasks, limiting its adaptability. Under such conditions, pretraining a value model or a reward model becomes equivalent, as both provide fixed supervisory signals without new ground-truth feedback. To address these issues, we propose \textbf{Decoupled Value Policy Optimization (DVPO)}, a lean framework that replaces traditional reward modeling with a pretrained \emph{global value model (GVM)}. The GVM is conditioned on policy trajectories and predicts token-level return-to-go estimates. By decoupling value model from policy training (via frozen GVM-driven RL objectives), DVPO eliminates actor-critic interdependence, reducing GPU memory usage by 40\% and training time by 35\% compared to conventional RLHF. Experiments across benchmarks show DVPO outperforms efficient RLHF methods (e.g., DPO) while matching state-of-the-art PPO in performance.
Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs
Feb 20, 2025Multi-head Latent Attention (MLA) is an innovative architecture proposed by DeepSeek, designed to ensure efficient and economical inference by significantly compressing the Key-Value (KV) cache into a latent vector. Compared to MLA, standard LLMs employing Multi-Head Attention (MHA) and its variants such as Grouped-Query Attention (GQA) exhibit significant cost disadvantages. Enabling well-trained LLMs (e.g., Llama) to rapidly adapt to MLA without pre-training from scratch is both meaningful and challenging. This paper proposes the first data-efficient fine-tuning method for transitioning from MHA to MLA (MHA2MLA), which includes two key components: for partial-RoPE, we remove RoPE from dimensions of queries and keys that contribute less to the attention scores, for low-rank approximation, we introduce joint SVD approximations based on the pre-trained parameters of keys and values. These carefully designed strategies enable MHA2MLA to recover performance using only a small fraction (0.3% to 0.6%) of the data, significantly reducing inference costs while seamlessly integrating with compression techniques such as KV cache quantization. For example, the KV cache size of Llama2-7B is reduced by 92.19%, with only a 0.5% drop in LongBench performance.
Unsupervised CP-UNet Framework for Denoising DAS Data with Decay Noise
Feb 19, 2025



Distributed acoustic sensor (DAS) technology leverages optical fiber cables to detect acoustic signals, providing cost-effective and dense monitoring capabilities. It offers several advantages including resistance to extreme conditions, immunity to electromagnetic interference, and accurate detection. However, DAS typically exhibits a lower signal-to-noise ratio (S/N) compared to geophones and is susceptible to various noise types, such as random noise, erratic noise, level noise, and long-period noise. This reduced S/N can negatively impact data analyses containing inversion and interpretation. While artificial intelligence has demonstrated excellent denoising capabilities, most existing methods rely on supervised learning with labeled data, which imposes stringent requirements on the quality of the labels. To address this issue, we develop a label-free unsupervised learning (UL) network model based on Context-Pyramid-UNet (CP-UNet) to suppress erratic and random noises in DAS data. The CP-UNet utilizes the Context Pyramid Module in the encoding and decoding process to extract features and reconstruct the DAS data. To enhance the connectivity between shallow and deep features, we add a Connected Module (CM) to both encoding and decoding section. Layer Normalization (LN) is utilized to replace the commonly employed Batch Normalization (BN), accelerating the convergence of the model and preventing gradient explosion during training. Huber-loss is adopted as our loss function whose parameters are experimentally determined. We apply the network to both the 2-D synthetic and filed data. Comparing to traditional denoising methods and the latest UL framework, our proposed method demonstrates superior noise reduction performance.