 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEM: Environment-Free Exploration for Training GUI Agent with Value Environment Model
Feb 26, 2025



Training Vision-Language Models (VLMs) for Graphical User Interfaces (GUI) agents via Reinforcement Learning (RL) faces critical challenges: environment-based RL requires costly interactions, while environment-free methods struggle with distribution shift and reward generalization. We propose an environment-free RL framework that decouples value estimation from policy optimization by leveraging a pretrained Value Environment Model (VEM). VEM predicts state-action values directly from offline data, distilling human-like priors about GUI interaction outcomes without requiring next-state prediction or environmental feedback. This avoids compounding errors and enhances resilience to UI changes by focusing on semantic reasoning (e.g., Does this action advance the user's goal?). The framework operates in two stages: (1) pretraining VEM to estimate long-term action utilities and (2) guiding policy exploration with frozen VEM signals, enabling layout-agnostic GUI automation. Evaluated on Android-in-the-Wild benchmarks, VEM achieves state-of-the-art performance in both offline and online settings, outperforming environment-free baselines significantly and matching environment-based approaches without interaction costs. Importantly, VEM demonstrates that semantic-aware value estimation can achieve comparable performance with online-trained methods.
LM2D: Lyrics- and Music-Driven Dance Synthesis
Mar 14, 2024



Dance typically involves professional choreography with complex movements that follow a musical rhythm and can also be influenced by lyrical content. The integration of lyrics in addition to the auditory dimension, enriches the foundational tone and makes motion generation more amenable to its semantic meanings. However, existing dance synthesis methods tend to model motions only conditioned on audio signals. In this work, we make two contributions to bridge this gap. First, we propose LM2D, a novel probabilistic architecture that incorporates a multimodal diffusion model with consistency distillation, designed to create dance conditioned on both music and lyrics in one diffusion generation step. Second, we introduce the first 3D dance-motion dataset that encompasses both music and lyrics, obtained with pose estimation technologies. We evaluate our model against music-only baseline models with objective metrics and human evaluations, including dancers and choreographers. The results demonstrate LM2D is able to produce realistic and diverse dance matching both lyrics and music. A video summary can be accessed at: https://youtu.be/4XCgvYookvA.
Scalable Motion Style Transfer with Constrained Diffusion Generation
Dec 12, 2023Current training of motion style transfer systems relies on consistency losses across style domains to preserve contents, hindering its scalable application to a large number of domains and private data. Recent image transfer works show the potential of independent training on each domain by leveraging implicit bridging between diffusion models, with the content preservation, however, limited to simple data patterns. We address this by imposing biased sampling in backward diffusion while maintaining the domain independence in the training stage. We construct the bias from the source domain keyframes and apply them as the gradient of content constraints, yielding a framework with keyframe manifold constraint gradients (KMCGs). Our validation demonstrates the success of training separate models to transfer between as many as ten dance motion styles. Comprehensive experiments find a significant improvement in preserving motion contents in comparison to baseline and ablative diffusion-based style transfer models. In addition, we perform a human study for a subjective assessment of the quality of generated dance motions. The results validate the competitiveness of KMCGs.
Music- and Lyrics-driven Dance Synthesis
Sep 30, 2023

Lyrics often convey information about the songs that are beyond the auditory dimension, enriching the semantic meaning of movements and musical themes. Such insights are important in the dance choreography domain. However, most existing dance synthesis methods mainly focus on music-to-dance generation, without considering the semantic information. To complement it, we introduce JustLMD, a new multimodal dataset of 3D dance motion with music and lyrics. To the best of our knowledge, this is the first dataset with triplet information including dance motion, music, and lyrics. Additionally, we showcase a cross-modal diffusion-based network designed to generate 3D dance motion conditioned on music and lyrics. The proposed JustLMD dataset encompasses 4.6 hours of 3D dance motion in 1867 sequences, accompanied by musical tracks and their corresponding English lyrics.
Controllable Motion Synthesis and Reconstruction with Autoregressive Diffusion Models
Apr 03, 2023



Data-driven and controllable human motion synthesis and prediction are active research areas with various applications in interactive media and social robotics. Challenges remain in these fields for generating diverse motions given past observations and dealing with imperfect poses. This paper introduces MoDiff, an autoregressive probabilistic diffusion model over motion sequences conditioned on control contexts of other modalities. Our model integrates a cross-modal Transformer encoder and a Transformer-based decoder, which are found effective in capturing temporal correlations in motion and control modalities. We also introduce a new data dropout method based on the diffusion forward process to provide richer data representations and robust generation. We demonstrate the superior performance of MoDiff in controllable motion synthesis for locomotion with respect to two baselines and show the benefits of diffusion data dropout for robust synthesis and reconstruction of high-fidelity motion close to recorded data.
SemEval-2023 Task 10: Explainable Detection of Online Sexism
Mar 07, 2023



Online sexism is a widespread and harmful phenomenon. Automated tools can assist the detection of sexism at scale. Binary detection, however, disregards the diversity of sexist content, and fails to provide clear explanations for why something is sexist. To address this issue, we introduce SemEval Task 10 on the Explainable Detection of Online Sexism (EDOS). We make three main contributions: i) a novel hierarchical taxonomy of sexist content, which includes granular vectors of sexism to aid explainability; ii) a new dataset of 20,000 social media comments with fine-grained labels, along with larger unlabelled datasets for model adaptation; and iii) baseline models as well as an analysis of the methods, results and errors for participant submissions to our task.
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Jan 10, 2023



Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
Dance Style Transfer with Cross-modal Transformer
Aug 22, 2022
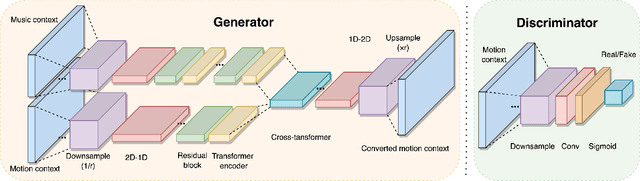
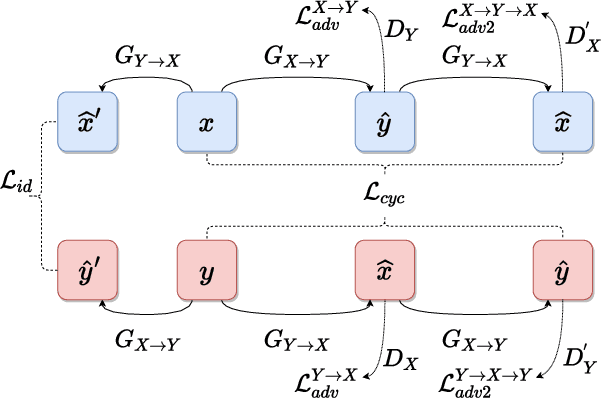

We present CycleDance, a dance style transfer system to transform an existing motion clip in one dance style to a motion clip in another dance style while attempting to preserve motion context of the dance. Our method extends an existing CycleGAN architecture for modeling audio sequences and integrates multimodal transformer encoders to account for music context. We adopt sequence length-based curriculum learning to stabilize training. Our approach captures rich and long-term intra-relations between motion frames, which is a common challenge in motion transfer and synthesis work. We further introduce new metrics for gauging transfer strength and content preservation in the context of dance movements. We perform an extensive ablation study as well as a human study including 30 participants with 5 or more years of dance experience. The results demonstrate that CycleDance generates realistic movements with the target style, significantly outperforming the baseline CycleGAN on naturalness, transfer strength, and content preservation.
Hidden behind the obvious: misleading keywords and implicitly abusive language on social media
May 03, 2022
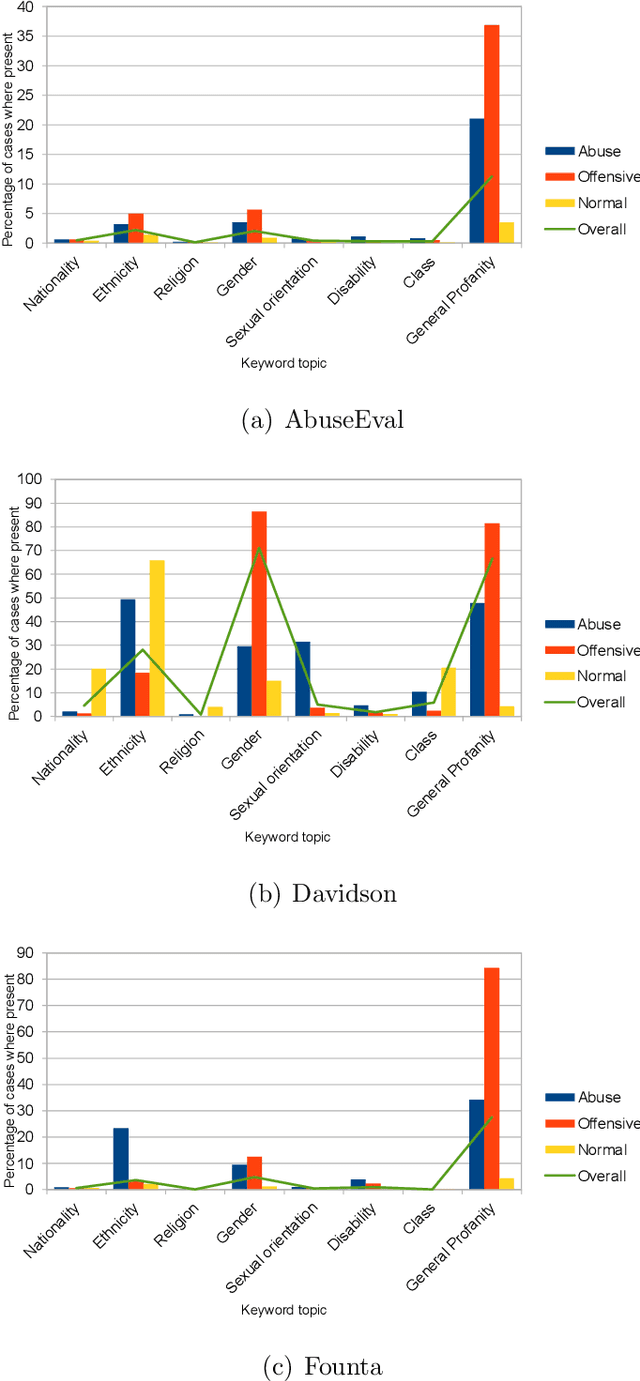
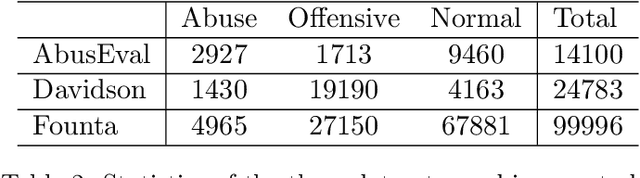
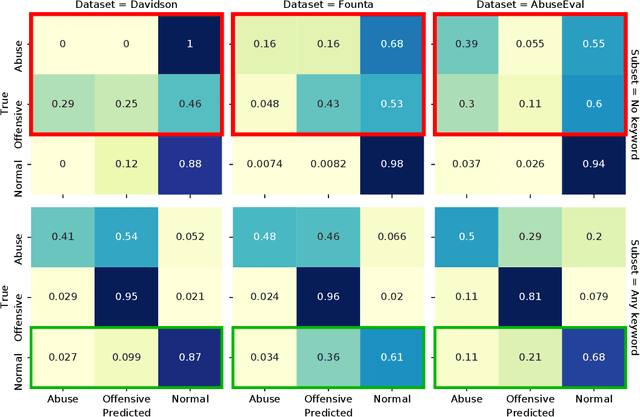
While social media offers freedom of self-expression, abusive language carry significant negative social impact. Driven by the importance of the issue, research in the automated detection of abusive language has witnessed growth and improvement. However, these detection models display a reliance on strongly indicative keywords, such as slurs and profanity. This means that they can falsely (1a) miss abuse without such keywords or (1b) flag non-abuse with such keywords, and that (2) they perform poorly on unseen data. Despite the recognition of these problems, gaps and inconsistencies remain in the literature. In this study, we analyse the impact of keywords from dataset construction to model behaviour in detail, with a focus on how models make mistakes on (1a) and (1b), and how (1a) and (1b) interact with (2). Through the analysis, we provide suggestions for future research to address all three problems.
The emojification of sentiment on social media: Collection and analysis of a longitudinal Twitter sentiment dataset
Aug 31, 2021
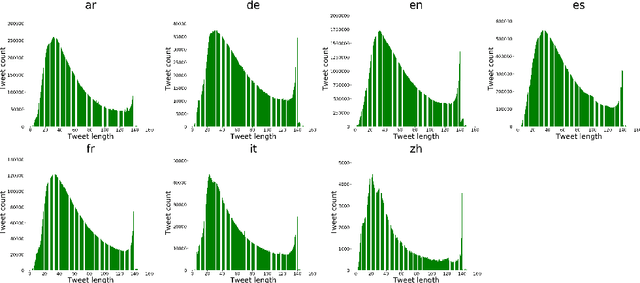
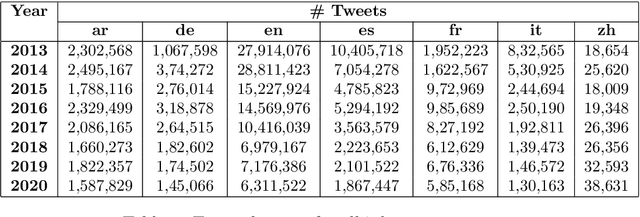
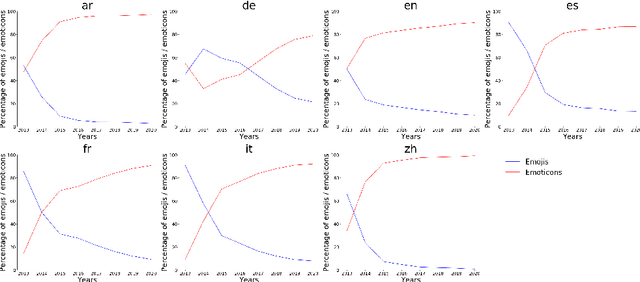
Social media, as a means for computer-mediated communication, has been extensively used to study the sentiment expressed by users around events or topics. There is however a gap in the longitudinal study of how sentiment evolved in social media over the years. To fill this gap, we develop TM-Senti, a new large-scale, distantly supervised Twitter sentiment dataset with over 184 million tweets and covering a time period of over seven years. We describe and assess our methodology to put together a large-scale, emoticon- and emoji-based labelled sentiment analysis dataset, along with an analysis of the resulting dataset. Our analysis highlights interesting temporal changes, among others in the increasing use of emojis over emoticons. We publicly release the dataset for further research in tasks including sentiment analysis and text classification of tweets. The dataset can be fully rehydrated including tweet metadata and without missing tweets thanks to the archive of tweets publicly available on the Internet Archive, which the dataset is based on.