 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebXSkill: Skill Learning for Autonomous Web Agents
Apr 14, 2026Autonomous web agents powered by large language models (LLMs) have shown promise in completing complex browser tasks, yet they still struggle with long-horizon workflows. A key bottleneck is the grounding gap in existing skill formulations: textual workflow skills provide natural language guidance but cannot be directly executed, while code-based skills are executable but opaque to the agent, offering no step-level understanding for error recovery or adaptation. We introduce WebXSkill, a framework that bridges this gap with executable skills, each pairing a parameterized action program with step-level natural language guidance, enabling both direct execution and agent-driven adaptation. WebXSkill operates in three stages: skill extraction mines reusable action subsequences from readily available synthetic agent trajectories and abstracts them into parameterized skills, skill organization indexes skills into a URL-based graph for context-aware retrieval, and skill deployment exposes two complementary modes, grounded mode for fully automated multi-step execution and guided mode where skills serve as step-by-step instructions that the agent follows with its native planning. On WebArena and WebVoyager, WebXSkill improves task success rate by up to 9.8 and 12.9 points over the baseline, respectively, demonstrating the effectiveness of executable skills for web agents. The code is publicly available at https://github.com/aiming-lab/WebXSkill.
ORACLE-SWE: Quantifying the Contribution of Oracle Information Signals on SWE Agents
Apr 09, 2026Recent advances in language model (LM) agents have significantly improved automated software engineering (SWE). Prior work has proposed various agentic workflows and training strategies as well as analyzed failure modes of agentic systems on SWE tasks, focusing on several contextual information signals: Reproduction Test, Regression Test, Edit Location, Execution Context, and API Usage. However, the individual contribution of each signal to overall success remains underexplored, particularly their ideal contribution when intermediate information is perfectly obtained. To address this gap, we introduce Oracle-SWE, a unified method to isolate and extract oracle information signals from SWE benchmarks and quantify the impact of each signal on agent performance. To further validate the pattern, we evaluate the performance gain of signals extracted by strong LMs when provided to a base agent, approximating real-world task-resolution settings. These evaluations aim to guide research prioritization for autonomous coding systems.
RepoLaunch: Automating Build&Test Pipeline of Code Repositories on ANY Language and ANY Platform
Mar 05, 2026Building software repositories typically requires significant manual effort. Recent advances in large language model (LLM) agents have accelerated automation in software engineering (SWE). We introduce RepoLaunch, the first agent capable of automatically resolving dependencies, compiling source code, and extracting test results for repositories across arbitrary programming languages and operating systems. To demonstrate its utility, we further propose a fully automated pipeline for SWE dataset creation, where task design is the only human intervention. RepoLaunch automates the remaining steps, enabling scalable benchmarking and training of coding agents and LLMs. Notably, several works on agentic benchmarking and training have recently adopted RepoLaunch for automated task generation.
GUI-360$^\circ$: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 10, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
GUI-360: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 06, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
SWE-bench Goes Live!
May 29, 2025The issue-resolving task, where a model generates patches to fix real-world bugs, has emerged as a critical benchmark for evaluating the capabilities of large language models (LLMs). While SWE-bench and its variants have become standard in this domain, they suffer from key limitations: they have not been updated since their initial releases, cover a narrow set of repositories, and depend heavily on manual effort for instance construction and environment setup. These factors hinder scalability and introduce risks of overfitting and data contamination. In this work, we present \textbf{SWE-bench-Live}, a \textit{live-updatable} benchmark designed to overcome these challenges. Our initial release consists of 1,319 tasks derived from real GitHub issues created since 2024, spanning 93 repositories. Each task is accompanied by a dedicated Docker image to ensure reproducible execution. Central to our benchmark is \method, an automated curation pipeline that streamlines the entire process from instance creation to environment setup, removing manual bottlenecks and enabling scalability and continuous updates. We evaluate a range of state-of-the-art agent frameworks and LLMs on SWE-bench-Live, revealing a substantial performance gap compared to static benchmarks like SWE-bench, even under controlled evaluation conditions. To better understand this discrepancy, we perform detailed analyses across repository origin, issue recency, and task difficulty. By providing a fresh, diverse, and executable benchmark grounded in live repository activity, SWE-bench-Live facilitates rigorous, contamination-resistant evaluation of LLMs and agents in dynamic, real-world software development settings.
Text2Grad: Reinforcement Learning from Natural Language Feedback
May 28, 2025Traditional RLHF optimizes language models with coarse, scalar rewards that mask the fine-grained reasons behind success or failure, leading to slow and opaque learning. Recent work augments RL with textual critiques through prompting or reflection, improving interpretability but leaving model parameters untouched. We introduce Text2Grad, a reinforcement-learning paradigm that turns free-form textual feedback into span-level gradients. Given human (or programmatic) critiques, Text2Grad aligns each feedback phrase with the relevant token spans, converts these alignments into differentiable reward signals, and performs gradient updates that directly refine the offending portions of the model's policy. This yields precise, feedback-conditioned adjustments instead of global nudges. Text2Grad is realized through three components: (1) a high-quality feedback-annotation pipeline that pairs critiques with token spans; (2) a fine-grained reward model that predicts span-level reward on answer while generating explanatory critiques; and (3) a span-level policy optimizer that back-propagates natural-language gradients. Across summarization, code generation, and question answering, Text2Grad consistently surpasses scalar-reward RL and prompt-only baselines, providing both higher task metrics and richer interpretability. Our results demonstrate that natural-language feedback, when converted to gradients, is a powerful signal for fine-grained policy optimization. The code for our method is available at https://github.com/microsoft/Text2Grad
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025

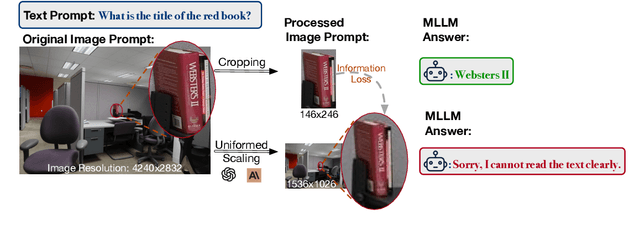
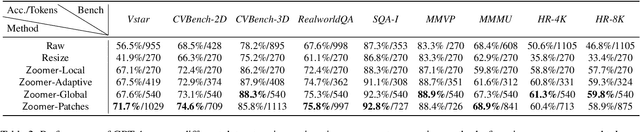
Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
UFO2: The Desktop AgentOS
Apr 20, 2025



Recent Computer-Using Agents (CUAs), powered by multimodal large language models (LLMs), offer a promising direction for automating complex desktop workflows through natural language. However, most existing CUAs remain conceptual prototypes, hindered by shallow OS integration, fragile screenshot-based interaction, and disruptive execution. We present UFO2, a multiagent AgentOS for Windows desktops that elevates CUAs into practical, system-level automation. UFO2 features a centralized HostAgent for task decomposition and coordination, alongside a collection of application-specialized AppAgent equipped with native APIs, domain-specific knowledge, and a unified GUI--API action layer. This architecture enables robust task execution while preserving modularity and extensibility. A hybrid control detection pipeline fuses Windows UI Automation (UIA) with vision-based parsing to support diverse interface styles. Runtime efficiency is further enhanced through speculative multi-action planning, reducing per-step LLM overhead. Finally, a Picture-in-Picture (PiP) interface enables automation within an isolated virtual desktop, allowing agents and users to operate concurrently without interference. We evaluate UFO2 across over 20 real-world Windows applications, demonstrating substantial improvements in robustness and execution accuracy over prior CUAs. Our results show that deep OS integration unlocks a scalable path toward reliable, user-aligned desktop automation.
API Agents vs. GUI Agents: Divergence and Convergence
Mar 14, 2025Large language models (LLMs) have evolved beyond simple text generation to power software agents that directly translate natural language commands into tangible actions. While API-based LLM agents initially rose to prominence for their robust automation capabilities and seamless integration with programmatic endpoints, recent progress in multimodal LLM research has enabled GUI-based LLM agents that interact with graphical user interfaces in a human-like manner. Although these two paradigms share the goal of enabling LLM-driven task automation, they diverge significantly in architectural complexity, development workflows, and user interaction models. This paper presents the first comprehensive comparative study of API-based and GUI-based LLM agents, systematically analyzing their divergence and potential convergence. We examine key dimensions and highlight scenarios in which hybrid approaches can harness their complementary strengths. By proposing clear decision criteria and illustrating practical use cases, we aim to guide practitioners and researchers in selecting, combining, or transitioning between these paradigms. Ultimately, we indicate that continuing innovations in LLM-based automation are poised to blur the lines between API- and GUI-driven agents, paving the way for more flexible, adaptive solutions in a wide range of real-world applications.