 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempo as the Stable Cue: Hierarchical Mixture of Tempo and Beat Experts for Music to 3D Dance Generation
Dec 21, 2025Music to 3D dance generation aims to synthesize realistic and rhythmically synchronized human dance from music. While existing methods often rely on additional genre labels to further improve dance generation, such labels are typically noisy, coarse, unavailable, or insufficient to capture the diversity of real-world music, which can result in rhythm misalignment or stylistic drift. In contrast, we observe that tempo, a core property reflecting musical rhythm and pace, remains relatively consistent across datasets and genres, typically ranging from 60 to 200 BPM. Based on this finding, we propose TempoMoE, a hierarchical tempo-aware Mixture-of-Experts module that enhances the diffusion model and its rhythm perception. TempoMoE organizes motion experts into tempo-structured groups for different tempo ranges, with multi-scale beat experts capturing fine- and long-range rhythmic dynamics. A Hierarchical Rhythm-Adaptive Routing dynamically selects and fuses experts from music features, enabling flexible, rhythm-aligned generation without manual genre labels. Extensive experiments demonstrate that TempoMoE achieves state-of-the-art results in dance quality and rhythm alignment.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
Dec 19, 2025Vision-Language-Action (VLA) models are driving a revolution in robotics, enabling machines to understand instructions and interact with the physical world. This field is exploding with new models and datasets, making it both exciting and challenging to keep pace with. This survey offers a clear and structured guide to the VLA landscape. We design it to follow the natural learning path of a researcher: we start with the basic Modules of any VLA model, trace the history through key Milestones, and then dive deep into the core Challenges that define recent research frontier. Our main contribution is a detailed breakdown of the five biggest challenges in: (1) Representation, (2) Execution, (3) Generalization, (4) Safety, and (5) Dataset and Evaluation. This structure mirrors the developmental roadmap of a generalist agent: establishing the fundamental perception-action loop, scaling capabilities across diverse embodiments and environments, and finally ensuring trustworthy deployment-all supported by the essential data infrastructure. For each of them, we review existing approaches and highlight future opportunities. We position this paper as both a foundational guide for newcomers and a strategic roadmap for experienced researchers, with the dual aim of accelerating learning and inspiring new ideas in embodied intelligence. A live version of this survey, with continuous updates, is maintained on our \href{https://suyuz1.github.io/VLA-Survey-Anatomy/}{project page}.
Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning
Nov 18, 2025Large Language Models (LLMs) are increasingly being explored for building Agents capable of active environmental interaction (e.g., via tool use) to solve complex problems. Reinforcement Learning (RL) is considered a key technology with significant potential for training such Agents; however, the effective application of RL to LLM Agents is still in its nascent stages and faces considerable challenges. Currently, this emerging field lacks in-depth exploration into RL approaches specifically tailored for the LLM Agent context, alongside a scarcity of flexible and easily extensible training frameworks designed for this purpose. To help advance this area, this paper first revisits and clarifies Reinforcement Learning methodologies for LLM Agents by systematically extending the Markov Decision Process (MDP) framework to comprehensively define the key components of an LLM Agent. Secondly, we introduce Agent-R1, a modular, flexible, and user-friendly training framework for RL-based LLM Agents, designed for straightforward adaptation across diverse task scenarios and interactive environments. We conducted experiments on Multihop QA benchmark tasks, providing initial validation for the effectiveness of our proposed methods and framework.
Melodia: Training-Free Music Editing Guided by Attention Probing in Diffusion Models
Nov 18, 2025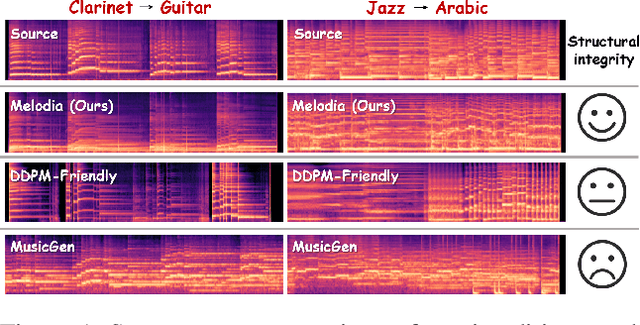
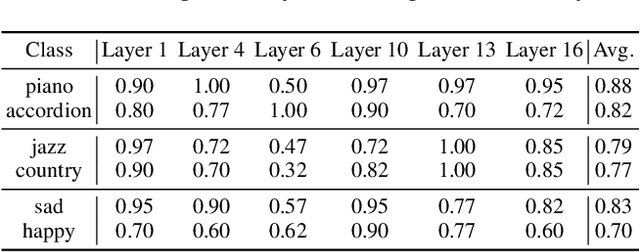
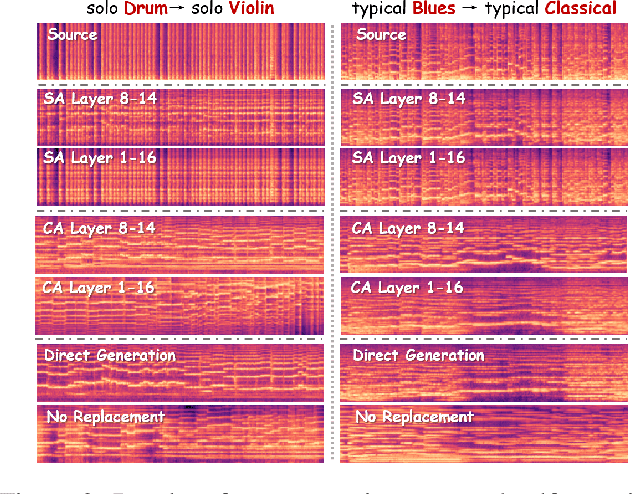
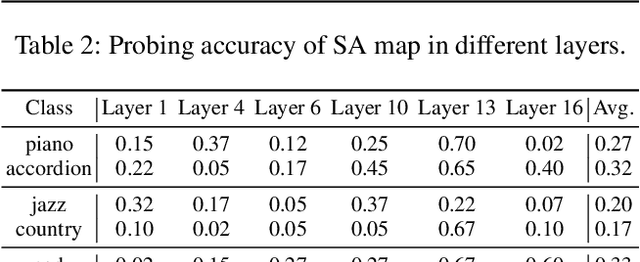
Text-to-music generation technology is progressing rapidly, creating new opportunities for musical composition and editing. However, existing music editing methods often fail to preserve the source music's temporal structure, including melody and rhythm, when altering particular attributes like instrument, genre, and mood. To address this challenge, this paper conducts an in-depth probing analysis on attention maps within AudioLDM 2, a diffusion-based model commonly used as the backbone for existing music editing methods. We reveal a key finding: cross-attention maps encompass details regarding distinct musical characteristics, and interventions on these maps frequently result in ineffective modifications. In contrast, self-attention maps are essential for preserving the temporal structure of the source music during its conversion into the target music. Building upon this understanding, we present Melodia, a training-free technique that selectively manipulates self-attention maps in particular layers during the denoising process and leverages an attention repository to store source music information, achieving accurate modification of musical characteristics while preserving the original structure without requiring textual descriptions of the source music. Additionally, we propose two novel metrics to better evaluate music editing methods. Both objective and subjective experiments demonstrate that our approach achieves superior results in terms of textual adherence and structural integrity across various datasets. This research enhances comprehension of internal mechanisms within music generation models and provides improved control for music creation.
Towards Stable and Structured Time Series Generation with Perturbation-Aware Flow Matching
Nov 18, 2025



Time series generation is critical for a wide range of applications, which greatly supports downstream analytical and decision-making tasks. However, the inherent temporal heterogeneous induced by localized perturbations present significant challenges for generating structurally consistent time series. While flow matching provides a promising paradigm by modeling temporal dynamics through trajectory-level supervision, it fails to adequately capture abrupt transitions in perturbed time series, as the use of globally shared parameters constrains the velocity field to a unified representation. To address these limitations, we introduce \textbf{PAFM}, a \textbf{P}erturbation-\textbf{A}ware \textbf{F}low \textbf{M}atching framework that models perturbed trajectories to ensure stable and structurally consistent time series generation. The framework incorporates perturbation-guided training to simulate localized disturbances and leverages a dual-path velocity field to capture trajectory deviations under perturbation, enabling refined modeling of perturbed behavior to enhance the structural coherence. In order to further improve sensitivity to trajectory perturbations while enhancing expressiveness, a mixture-of-experts decoder with flow routing dynamically allocates modeling capacity in response to different trajectory dynamics. Extensive experiments on both unconditional and conditional generation tasks demonstrate that PAFM consistently outperforms strong baselines. Code is available at https://anonymous.4open.science/r/PAFM-03B2.
Look As You Think: Unifying Reasoning and Visual Evidence Attribution for Verifiable Document RAG via Reinforcement Learning
Nov 15, 2025Aiming to identify precise evidence sources from visual documents, visual evidence attribution for visual document retrieval-augmented generation (VD-RAG) ensures reliable and verifiable predictions from vision-language models (VLMs) in multimodal question answering. Most existing methods adopt end-to-end training to facilitate intuitive answer verification. However, they lack fine-grained supervision and progressive traceability throughout the reasoning process. In this paper, we introduce the Chain-of-Evidence (CoE) paradigm for VD-RAG. CoE unifies Chain-of-Thought (CoT) reasoning and visual evidence attribution by grounding reference elements in reasoning steps to specific regions with bounding boxes and page indexes. To enable VLMs to generate such evidence-grounded reasoning, we propose Look As You Think (LAT), a reinforcement learning framework that trains models to produce verifiable reasoning paths with consistent attribution. During training, LAT evaluates the attribution consistency of each evidence region and provides rewards only when the CoE trajectory yields correct answers, encouraging process-level self-verification. Experiments on vanilla Qwen2.5-VL-7B-Instruct with Paper- and Wiki-VISA benchmarks show that LAT consistently improves the vanilla model in both single- and multi-image settings, yielding average gains of 8.23% in soft exact match (EM) and 47.0% in IoU@0.5. Meanwhile, LAT not only outperforms the supervised fine-tuning baseline, which is trained to directly produce answers with attribution, but also exhibits stronger generalization across domains.
MMDCP: A Distribution-free Approach to Outlier Detection and Classification with Coverage Guarantees and SCW-FDR Control
Nov 15, 2025We propose the Modified Mahalanobis Distance Conformal Prediction (MMDCP), a unified framework for multi-class classification and outlier detection under label shift, where the training and test distributions may differ. In such settings, many existing methods construct nonconformity scores based on empirical cumulative or density functions combined with data-splitting strategies. However, these approaches are often computationally expensive due to their heavy reliance on resampling procedures and tend to produce overly conservative prediction sets with unstable coverage, especially in small samples. To address these challenges, MMDCP combines class-specific distance measures with full conformal prediction to construct a score function, thereby producing adaptive prediction sets that effectively capture both inlier and outlier structures. Under mild regularity conditions, we establish convergence rates for the resulting sets and provide the first theoretical characterization of the gap between oracle and empirical conformal $p$-values, which ensures valid coverage and effective control of the class-wise false discovery rate (CW-FDR). We further introduce the Summarized Class-Wise FDR (SCW-FDR), a novel global error metric aggregating false discoveries across classes, and show that it can be effectively controlled within the MMDCP framework. Extensive simulations and two real-data applications support our theoretical findings and demonstrate the advantages of the proposed method.
Depth-Consistent 3D Gaussian Splatting via Physical Defocus Modeling and Multi-View Geometric Supervision
Nov 13, 2025



Three-dimensional reconstruction in scenes with extreme depth variations remains challenging due to inconsistent supervisory signals between near-field and far-field regions. Existing methods fail to simultaneously address inaccurate depth estimation in distant areas and structural degradation in close-range regions. This paper proposes a novel computational framework that integrates depth-of-field supervision and multi-view consistency supervision to advance 3D Gaussian Splatting. Our approach comprises two core components: (1) Depth-of-field Supervision employs a scale-recovered monocular depth estimator (e.g., Metric3D) to generate depth priors, leverages defocus convolution to synthesize physically accurate defocused images, and enforces geometric consistency through a novel depth-of-field loss, thereby enhancing depth fidelity in both far-field and near-field regions; (2) Multi-View Consistency Supervision employing LoFTR-based semi-dense feature matching to minimize cross-view geometric errors and enforce depth consistency via least squares optimization of reliable matched points. By unifying defocus physics with multi-view geometric constraints, our method achieves superior depth fidelity, demonstrating a 0.8 dB PSNR improvement over the state-of-the-art method on the Waymo Open Dataset. This framework bridges physical imaging principles and learning-based depth regularization, offering a scalable solution for complex depth stratification in urban environments.
Temporal Action Selection for Action Chunking
Nov 06, 2025Action chunking is a widely adopted approach in Learning from Demonstration (LfD). By modeling multi-step action chunks rather than single-step actions, action chunking significantly enhances modeling capabilities for human expert policies. However, the reduced decision frequency restricts the utilization of recent observations, degrading reactivity - particularly evident in the inadequate adaptation to sensor noise and dynamic environmental changes. Existing efforts to address this issue have primarily resorted to trading off reactivity against decision consistency, without achieving both. To address this limitation, we propose a novel algorithm, Temporal Action Selector (TAS), which caches predicted action chunks from multiple timesteps and dynamically selects the optimal action through a lightweight selector network. TAS achieves balanced optimization across three critical dimensions: reactivity, decision consistency, and motion coherence. Experiments across multiple tasks with diverse base policies show that TAS significantly improves success rates - yielding an absolute gain of up to 73.3%. Furthermore, integrating TAS as a base policy with residual reinforcement learning (RL) substantially enhances training efficiency and elevates the performance plateau. Experiments in both simulation and physical robots confirm the method's efficacy.