 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholarQuest: A Taxonomy-Guided Benchmark for Agentic Academic Paper Search in Open Literature Environments
Jun 18, 2026Academic paper search is a core step in scientific research, and LLM-based search agents are emerging as a promising paradigm for iterative, intent-driven literature exploration. However, existing benchmarks are insufficient for systematically evaluating agentic academic search under realistic open literature environments. We propose ScholarQuest, a large-scale, taxonomy-guided benchmark for agentic academic paper search. ScholarQuest is constructed from over 1,000 computer science topics and four representative research intents, including method-oriented, setting-anchored, comparison-based, and scope-controlled queries. It further provides scalable answer construction and a shared retrieval backend ScholarBase for reproducible evaluation. Benchmarking results show that agentic methods outperform single-shot retrieval baselines, yet the best-performing agent only achieves 0.314 Recall@100 and 0.355 Recall@All, indicating substantial room for improvement. In addition, analyses of search efficiency, intent-level robustness, and failure cases further highlight the benchmark's ability to provide multi-dimensional evaluation signals for academic paper search agents.
TabClaw: An Interactive and Self-Evolving Agent for Spreadsheet Manipulation and Table Reasoning
Jun 09, 2026Spreadsheets and tables are widely used representations for structured data analysis, but effective analysis still requires substantial manual effort and domain expertise. Recent large language model (LLM) agents can automate parts of this process, but they often provide limited transparency into intermediate decisions, rely on implicit assumptions, struggle with multi-table comparison, and repeat similar workflows without adapting to a user's preferences. This paper presents TabClaw, an open-source interactive AI agent for spreadsheet manipulation and table reasoning. Users upload CSV or Excel files and issue natural-language requests; TabClaw clarifies ambiguous intent, exposes an editable execution plan, streams a ReAct-style tool-using analysis loop, dispatches specialist agents for parallel multi-table reasoning, and synthesizes findings with explicit consensus and uncertainty markers. Beyond one-off analysis, TabClaw records completed workflows, extracts persistent user memory, distills reusable skills from repeated tool-use patterns, supports package-style skill import, and upgrades skills from negative feedback. Experiments on spreadsheet manipulation and table reasoning benchmarks show that TabClaw improves executable task completion and reasoning performance while preserving an inspectable user workflow. This paper shows how TabClaw turns spreadsheets and tables into inspectable analytical workflows while gradually personalizing itself to recurring data-analysis tasks. Our code is available.
Claw-R1: A Step-Level Data Middleware System for Agentic Reinforcement Learning
Jun 08, 2026Agentic reinforcement learning (RL) has become an important post-training paradigm for turning LLMs from static chatbots into interactive agents, giving rise to representative applications such as OpenClaw. Existing work mainly focuses on policy optimization algorithms and training frameworks, but pays less attention to the full data lifecycle of agent-environment interactions, from data production to training consumption. To bridge this gap, we present Claw-R1, an interactive step-level data middleware system for agentic RL. Claw-R1 connects heterogeneous agent runtimes with RL training backends through two core components: a Gateway Server and a Data Pool. The Gateway Server captures multi-turn interaction steps through a unified LLM API entry point, while the Data Pool organizes them into step-level records consisting of prompt IDs, response IDs, rewards and other metadata. In our demo, users can interactively inspect live trajectories, examine the state, action, and reward of each step, curate data by quality and readiness, and configure training-ready batches for different downstream RL algorithms. Overall, Claw-R1 treats agent interaction traces as managed data assets rather than temporary runtime logs. Through this demonstration, we hope to encourage the community to recognize the importance of data management in agentic RL. Our code is available at https://github.com/AgentR1/Claw-R1 and the demonstration video can be found at link https://youtu.be/Pw47dAOw6B0.
StepPO: Step-Aligned Policy Optimization for Agentic Reinforcement Learning
Apr 20, 2026General agents have given rise to phenomenal applications such as OpenClaw and Claude Code. As these agent systems (a.k.a. Harnesses) strive for bolder goals, they demand increasingly stronger agentic capabilities from foundation Large Language Models (LLMs). Agentic Reinforcement Learning (RL) is emerging as a central post-training paradigm for empowering LLMs with these capabilities and is playing an increasingly pivotal role in agent training. Unlike single-turn token-level alignment or reasoning enhancement, as in RLHF and RLVR, Agentic RL targets multi-turn interactive settings, where the goal is to optimize core agentic capabilities such as decision making and tool use while addressing new challenges including delayed and sparse rewards, as well as long and variable context. As a result, the token-centric modeling and optimization paradigm inherited from traditional LLM RL is becoming increasingly inadequate for capturing real LLM agent behavior. In this paper, we present StepPO as a position on step-level Agentic RL. We argue that the conventional token-level Markov Decision Process (MDP) should be advanced to a step-level MDP formulation, and that the step, rather than the token, should be regarded as the proper action representation for LLM agents. We then propose step-level credit assignment as the natural optimization counterpart of this formulation, thereby aligning policy optimization and reward propagation with the granularity of agent decisions. Finally, we discuss the key systems designs required to realize step-level Agentic RL in practice and preliminary experiments provide initial evidence for the effectiveness of this perspective. We hope that the step-aligned, step-level paradigm embodied in StepPO offers the Agentic RL community a useful lens for understanding agent behavior and helps advance LLMs toward stronger general-agent capabilities.
CoGenCast: A Coupled Autoregressive-Flow Generative Framework for Time Series Forecasting
Feb 03, 2026Time series forecasting can be viewed as a generative problem that requires both semantic understanding over contextual conditions and stochastic modeling of continuous temporal dynamics. Existing approaches typically rely on either autoregressive large language models (LLMs) for semantic context modeling or diffusion-like models for continuous probabilistic generation. However, neither method alone can adequately model both aspects simultaneously. In this work, we propose CoGenCast, a hybrid generative framework that couples pre-trained LLMs with flow-matching mechanism for effective time series forecasting. Specifically, we reconfigure pre-trained decoder-only LLMs into a native forecasting encoder-decoder backbone by modifying only the attention topology, enabling bidirectional context encoding and causal representation generation. Building on this, a flow-matching mechanism is further integrated to model temporal evolution, capturing continuous stochastic dynamics conditioned on the autoregressively generated representation. Notably, CoGenCast naturally supports multimodal forecasting and cross-domain unified training. Extensive experiments on multiple benchmarks show that CoGenCast consistently outperforms previous compared baselines. Code is available at https://github.com/liuyaguo/_CoGenCast.
Mind2Report: A Cognitive Deep Research Agent for Expert-Level Commercial Report Synthesis
Jan 08, 2026Synthesizing informative commercial reports from massive and noisy web sources is critical for high-stakes business decisions. Although current deep research agents achieve notable progress, their reports still remain limited in terms of quality, reliability, and coverage. In this work, we propose Mind2Report, a cognitive deep research agent that emulates the commercial analyst to synthesize expert-level reports. Specifically, it first probes fine-grained intent, then searches web sources and records distilled information on the fly, and subsequently iteratively synthesizes the report. We design Mind2Report as a training-free agentic workflow that augments general large language models (LLMs) with dynamic memory to support these long-form cognitive processes. To rigorously evaluate Mind2Report, we further construct QRC-Eval comprising 200 real-world commercial tasks and establish a holistic evaluation strategy to assess report quality, reliability, and coverage. Experiments demonstrate that Mind2Report outperforms leading baselines, including OpenAI and Gemini deep research agents. Although this is a preliminary study, we expect it to serve as a foundation for advancing the future design of commercial deep research agents. Our code and data are available at https://github.com/Melmaphother/Mind2Report.
Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning
Nov 18, 2025Large Language Models (LLMs) are increasingly being explored for building Agents capable of active environmental interaction (e.g., via tool use) to solve complex problems. Reinforcement Learning (RL) is considered a key technology with significant potential for training such Agents; however, the effective application of RL to LLM Agents is still in its nascent stages and faces considerable challenges. Currently, this emerging field lacks in-depth exploration into RL approaches specifically tailored for the LLM Agent context, alongside a scarcity of flexible and easily extensible training frameworks designed for this purpose. To help advance this area, this paper first revisits and clarifies Reinforcement Learning methodologies for LLM Agents by systematically extending the Markov Decision Process (MDP) framework to comprehensively define the key components of an LLM Agent. Secondly, we introduce Agent-R1, a modular, flexible, and user-friendly training framework for RL-based LLM Agents, designed for straightforward adaptation across diverse task scenarios and interactive environments. We conducted experiments on Multihop QA benchmark tasks, providing initial validation for the effectiveness of our proposed methods and framework.
MemWeaver: A Hierarchical Memory from Textual Interactive Behaviors for Personalized Generation
Oct 09, 2025



The primary form of user-internet engagement is shifting from leveraging implicit feedback signals, such as browsing and clicks, to harnessing the rich explicit feedback provided by textual interactive behaviors. This shift unlocks a rich source of user textual history, presenting a profound opportunity for a deeper form of personalization. However, prevailing approaches offer only a shallow form of personalization, as they treat user history as a flat list of texts for retrieval and fail to model the rich temporal and semantic structures reflecting dynamic nature of user interests. In this work, we propose \textbf{MemWeaver}, a framework that weaves the user's entire textual history into a hierarchical memory to power deeply personalized generation. The core innovation of our memory lies in its ability to capture both the temporal evolution of interests and the semantic relationships between different activities. To achieve this, MemWeaver builds two complementary memory components that both integrate temporal and semantic information, but at different levels of abstraction: behavioral memory, which captures specific user actions, and cognitive memory, which represents long-term preferences. This dual-component memory serves as a unified representation of the user, allowing large language models (LLMs) to reason over both concrete behaviors and abstracted traits. Experiments on the Language Model Personalization (LaMP) benchmark validate the efficacy of MemWeaver. Our code is available\footnote{https://github.com/fishsure/MemWeaver}.
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Jun 12, 2025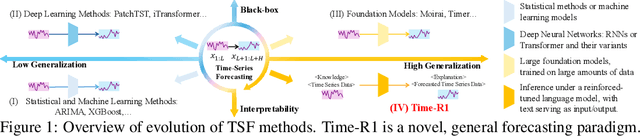

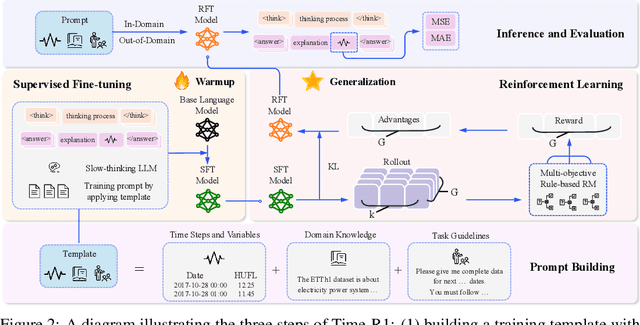
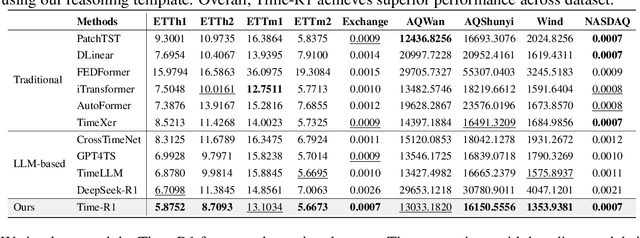
To advance time series forecasting (TSF), various methods have been proposed to improve prediction accuracy, evolving from statistical techniques to data-driven deep learning architectures. Despite their effectiveness, most existing methods still adhere to a fast thinking paradigm-relying on extracting historical patterns and mapping them to future values as their core modeling philosophy, lacking an explicit thinking process that incorporates intermediate time series reasoning. Meanwhile, emerging slow-thinking LLMs (e.g., OpenAI-o1) have shown remarkable multi-step reasoning capabilities, offering an alternative way to overcome these issues. However, prompt engineering alone presents several limitations - including high computational cost, privacy risks, and limited capacity for in-depth domain-specific time series reasoning. To address these limitations, a more promising approach is to train LLMs to develop slow thinking capabilities and acquire strong time series reasoning skills. For this purpose, we propose Time-R1, a two-stage reinforcement fine-tuning framework designed to enhance multi-step reasoning ability of LLMs for time series forecasting. Specifically, the first stage conducts supervised fine-tuning for warmup adaptation, while the second stage employs reinforcement learning to improve the model's generalization ability. Particularly, we design a fine-grained multi-objective reward specifically for time series forecasting, and then introduce GRIP (group-based relative importance for policy optimization), which leverages non-uniform sampling to further encourage and optimize the model's exploration of effective reasoning paths. Experiments demonstrate that Time-R1 significantly improves forecast performance across diverse datasets.
FDF: Flexible Decoupled Framework for Time Series Forecasting with Conditional Denoising and Polynomial Modeling
Oct 17, 2024



Time series forecasting is vital in numerous web applications, influencing critical decision-making across industries. While diffusion models have recently gained increasing popularity for this task, we argue they suffer from a significant drawback: indiscriminate noise addition to the original time series followed by denoising, which can obscure underlying dynamic evolving trend and complicate forecasting. To address this limitation, we propose a novel flexible decoupled framework (FDF) that learns high-quality time series representations for enhanced forecasting performance. A key characteristic of our approach leverages the inherent inductive bias of time series data by decomposing it into trend and seasonal components, each modeled separately to enable decoupled analysis and modeling. Specifically, we propose an innovative Conditional Denoising Seasonal Module (CDSM) within the diffusion model, which leverages statistical information from the historical window to conditionally model the complex seasonal component. Notably, we incorporate a Polynomial Trend Module (PTM) to effectively capture the smooth trend component, thereby enhancing the model's ability to represent temporal dependencies. Extensive experiments validate the effectiveness of our framework, demonstrating superior performance over existing methods and higlighting its flexibility in time series forecasting. We hope our work can bring a new perspective for time series forecasting. We intend to make our code publicly available as open-source in the future.