 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Consistent 3D Gaussian Splatting via Physical Defocus Modeling and Multi-View Geometric Supervision
Nov 13, 2025



Three-dimensional reconstruction in scenes with extreme depth variations remains challenging due to inconsistent supervisory signals between near-field and far-field regions. Existing methods fail to simultaneously address inaccurate depth estimation in distant areas and structural degradation in close-range regions. This paper proposes a novel computational framework that integrates depth-of-field supervision and multi-view consistency supervision to advance 3D Gaussian Splatting. Our approach comprises two core components: (1) Depth-of-field Supervision employs a scale-recovered monocular depth estimator (e.g., Metric3D) to generate depth priors, leverages defocus convolution to synthesize physically accurate defocused images, and enforces geometric consistency through a novel depth-of-field loss, thereby enhancing depth fidelity in both far-field and near-field regions; (2) Multi-View Consistency Supervision employing LoFTR-based semi-dense feature matching to minimize cross-view geometric errors and enforce depth consistency via least squares optimization of reliable matched points. By unifying defocus physics with multi-view geometric constraints, our method achieves superior depth fidelity, demonstrating a 0.8 dB PSNR improvement over the state-of-the-art method on the Waymo Open Dataset. This framework bridges physical imaging principles and learning-based depth regularization, offering a scalable solution for complex depth stratification in urban environments.
Metamon-GS: Enhancing Representability with Variance-Guided Densification and Light Encoding
Apr 20, 2025



The introduction of 3D Gaussian Splatting (3DGS) has advanced novel view synthesis by utilizing Gaussians to represent scenes. Encoding Gaussian point features with anchor embeddings has significantly enhanced the performance of newer 3DGS variants. While significant advances have been made, it is still challenging to boost rendering performance. Feature embeddings have difficulty accurately representing colors from different perspectives under varying lighting conditions, which leads to a washed-out appearance. Another reason is the lack of a proper densification strategy that prevents Gaussian point growth in thinly initialized areas, resulting in blurriness and needle-shaped artifacts. To address them, we propose Metamon-GS, from innovative viewpoints of variance-guided densification strategy and multi-level hash grid. The densification strategy guided by variance specifically targets Gaussians with high gradient variance in pixels and compensates for the importance of regions with extra Gaussians to improve reconstruction. The latter studies implicit global lighting conditions and accurately interprets color from different perspectives and feature embeddings. Our thorough experiments on publicly available datasets show that Metamon-GS surpasses its baseline model and previous versions, delivering superior quality in rendering novel views.
Toy-GS: Assembling Local Gaussians for Precisely Rendering Large-Scale Free Camera Trajectories
Dec 13, 2024



Currently, 3D rendering for large-scale free camera trajectories, namely, arbitrary input camera trajectories, poses significant challenges: 1) The distribution and observation angles of the cameras are irregular, and various types of scenes are included in the free trajectories; 2) Processing the entire point cloud and all images at once for large-scale scenes requires a substantial amount of GPU memory. This paper presents a Toy-GS method for accurately rendering large-scale free camera trajectories. Specifically, we propose an adaptive spatial division approach for free trajectories to divide cameras and the sparse point cloud of the entire scene into various regions according to camera poses. Training each local Gaussian in parallel for each area enables us to concentrate on texture details and minimize GPU memory usage. Next, we use the multi-view constraint and position-aware point adaptive control (PPAC) to improve the rendering quality of texture details. In addition, our regional fusion approach combines local and global Gaussians to enhance rendering quality with an increasing number of divided areas. Extensive experiments have been carried out to confirm the effectiveness and efficiency of Toy-GS, leading to state-of-the-art results on two public large-scale datasets as well as our SCUTic dataset. Our proposal demonstrates an enhancement of 1.19 dB in PSNR and conserves 7 G of GPU memory when compared to various benchmarks.
Efficient Globally-Optimal Correspondence-Less Visual Odometry for Planar Ground Vehicles
Mar 01, 2022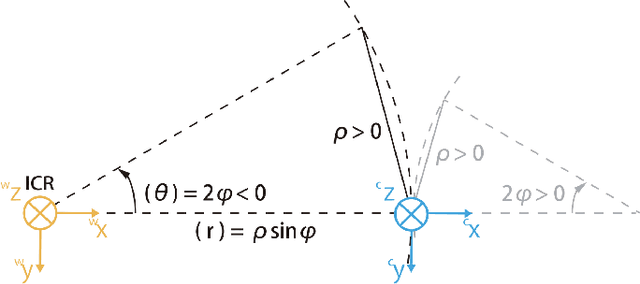
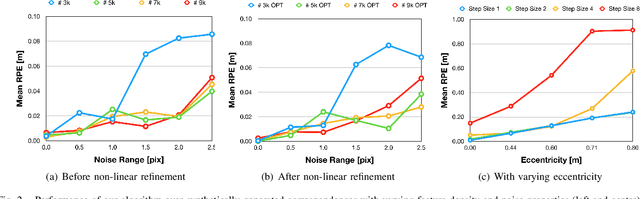
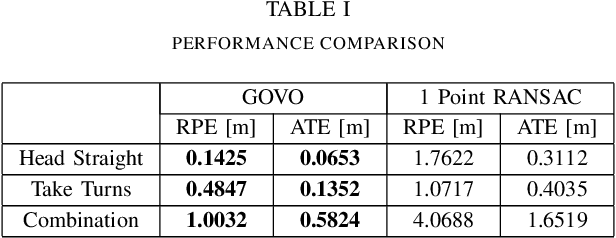
The motion of planar ground vehicles is often non-holonomic, and as a result may be modelled by the 2 DoF Ackermann steering model. We analyse the feasibility of estimating such motion with a downward facing camera that exerts fronto-parallel motion with respect to the ground plane. This turns the motion estimation into a simple image registration problem in which we only have to identify a 2-parameter planar homography. However, one difficulty that arises from this setup is that ground-plane features are indistinctive and thus hard to match between successive views. We encountered this difficulty by introducing the first globally-optimal, correspondence-less solution to plane-based Ackermann motion estimation. The solution relies on the branch-and-bound optimisation technique. Through the low-dimensional parametrisation, a derivation of tight bounds, and an efficient implementation, we demonstrate how this technique is eventually amenable to accurate real-time motion estimation. We prove its property of global optimality and analyse the impact of assuming a locally constant centre of rotation. Our results on real data finally demonstrate a significant advantage over the more traditional, correspondence-based hypothesise-and-test schemes.