 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-centric 3D Motion Field for Robot Learning from Human Videos
Jun 04, 2025Learning robot control policies from human videos is a promising direction for scaling up robot learning. However, how to extract action knowledge (or action representations) from videos for policy learning remains a key challenge. Existing action representations such as video frames, pixelflow, and pointcloud flow have inherent limitations such as modeling complexity or loss of information. In this paper, we propose to use object-centric 3D motion field to represent actions for robot learning from human videos, and present a novel framework for extracting this representation from videos for zero-shot control. We introduce two novel components in its implementation. First, a novel training pipeline for training a ''denoising'' 3D motion field estimator to extract fine object 3D motions from human videos with noisy depth robustly. Second, a dense object-centric 3D motion field prediction architecture that favors both cross-embodiment transfer and policy generalization to background. We evaluate the system in real world setups. Experiments show that our method reduces 3D motion estimation error by over 50% compared to the latest method, achieve 55% average success rate in diverse tasks where prior approaches fail~($\lesssim 10$\%), and can even acquire fine-grained manipulation skills like insertion.
Diffusion Guidance Is a Controllable Policy Improvement Operator
May 29, 2025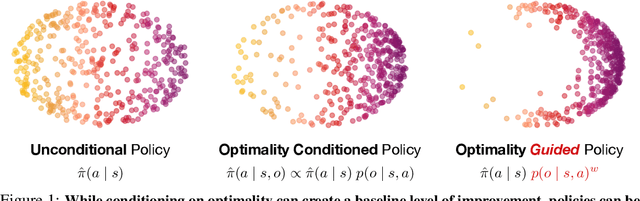
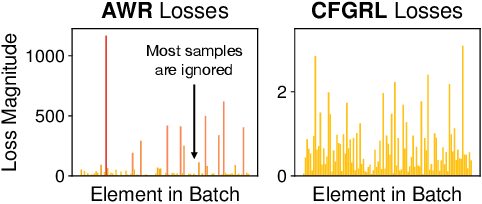
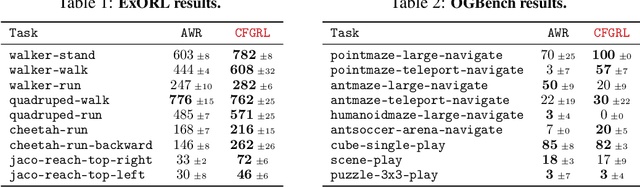
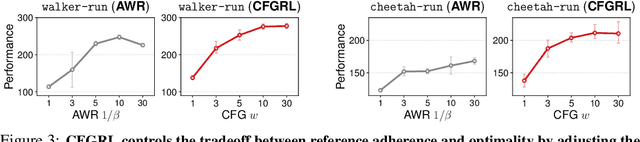
At the core of reinforcement learning is the idea of learning beyond the performance in the data. However, scaling such systems has proven notoriously tricky. In contrast, techniques from generative modeling have proven remarkably scalable and are simple to train. In this work, we combine these strengths, by deriving a direct relation between policy improvement and guidance of diffusion models. The resulting framework, CFGRL, is trained with the simplicity of supervised learning, yet can further improve on the policies in the data. On offline RL tasks, we observe a reliable trend -- increased guidance weighting leads to increased performance. Of particular importance, CFGRL can operate without explicitly learning a value function, allowing us to generalize simple supervised methods (e.g., goal-conditioned behavioral cloning) to further prioritize optimality, gaining performance for "free" across the board.
Bigger, Regularized, Categorical: High-Capacity Value Functions are Efficient Multi-Task Learners
May 29, 2025Recent advances in language modeling and vision stem from training large models on diverse, multi-task data. This paradigm has had limited impact in value-based reinforcement learning (RL), where improvements are often driven by small models trained in a single-task context. This is because in multi-task RL sparse rewards and gradient conflicts make optimization of temporal difference brittle. Practical workflows for generalist policies therefore avoid online training, instead cloning expert trajectories or distilling collections of single-task policies into one agent. In this work, we show that the use of high-capacity value models trained via cross-entropy and conditioned on learnable task embeddings addresses the problem of task interference in online RL, allowing for robust and scalable multi-task training. We test our approach on 7 multi-task benchmarks with over 280 unique tasks, spanning high degree-of-freedom humanoid control and discrete vision-based RL. We find that, despite its simplicity, the proposed approach leads to state-of-the-art single and multi-task performance, as well as sample-efficient transfer to new tasks.
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control
May 29, 2025Reinforcement learning (RL) has driven significant progress in robotics, but its complexity and long training times remain major bottlenecks. In this report, we introduce FastTD3, a simple, fast, and capable RL algorithm that significantly speeds up training for humanoid robots in popular suites such as HumanoidBench, IsaacLab, and MuJoCo Playground. Our recipe is remarkably simple: we train an off-policy TD3 agent with several modifications -- parallel simulation, large-batch updates, a distributional critic, and carefully tuned hyperparameters. FastTD3 solves a range of HumanoidBench tasks in under 3 hours on a single A100 GPU, while remaining stable during training. We also provide a lightweight and easy-to-use implementation of FastTD3 to accelerate RL research in robotics.
EgoZero: Robot Learning from Smart Glasses
May 26, 2025



Despite recent progress in general purpose robotics, robot policies still lag far behind basic human capabilities in the real world. Humans interact constantly with the physical world, yet this rich data resource remains largely untapped in robot learning. We propose EgoZero, a minimal system that learns robust manipulation policies from human demonstrations captured with Project Aria smart glasses, $\textbf{and zero robot data}$. EgoZero enables: (1) extraction of complete, robot-executable actions from in-the-wild, egocentric, human demonstrations, (2) compression of human visual observations into morphology-agnostic state representations, and (3) closed-loop policy learning that generalizes morphologically, spatially, and semantically. We deploy EgoZero policies on a gripper Franka Panda robot and demonstrate zero-shot transfer with 70% success rate over 7 manipulation tasks and only 20 minutes of data collection per task. Our results suggest that in-the-wild human data can serve as a scalable foundation for real-world robot learning - paving the way toward a future of abundant, diverse, and naturalistic training data for robots. Code and videos are available at https://egozero-robot.github.io.
DexGarmentLab: Dexterous Garment Manipulation Environment with Generalizable Policy
May 19, 2025Garment manipulation is a critical challenge due to the diversity in garment categories, geometries, and deformations. Despite this, humans can effortlessly handle garments, thanks to the dexterity of our hands. However, existing research in the field has struggled to replicate this level of dexterity, primarily hindered by the lack of realistic simulations of dexterous garment manipulation. Therefore, we propose DexGarmentLab, the first environment specifically designed for dexterous (especially bimanual) garment manipulation, which features large-scale high-quality 3D assets for 15 task scenarios, and refines simulation techniques tailored for garment modeling to reduce the sim-to-real gap. Previous data collection typically relies on teleoperation or training expert reinforcement learning (RL) policies, which are labor-intensive and inefficient. In this paper, we leverage garment structural correspondence to automatically generate a dataset with diverse trajectories using only a single expert demonstration, significantly reducing manual intervention. However, even extensive demonstrations cannot cover the infinite states of garments, which necessitates the exploration of new algorithms. To improve generalization across diverse garment shapes and deformations, we propose a Hierarchical gArment-manipuLation pOlicy (HALO). It first identifies transferable affordance points to accurately locate the manipulation area, then generates generalizable trajectories to complete the task. Through extensive experiments and detailed analysis of our method and baseline, we demonstrate that HALO consistently outperforms existing methods, successfully generalizing to previously unseen instances even with significant variations in shape and deformation where others fail. Our project page is available at: https://wayrise.github.io/DexGarmentLab/.
Visual Imitation Enables Contextual Humanoid Control
May 07, 2025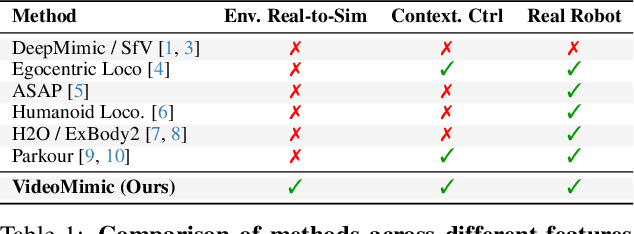
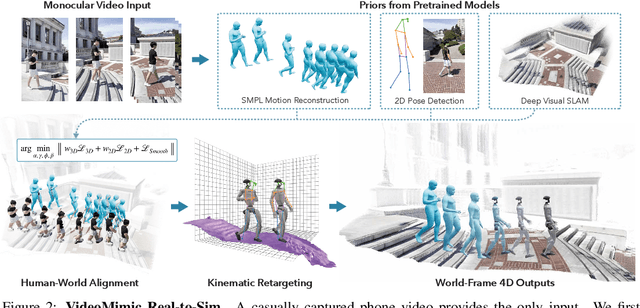


How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
ViTaMIn: Learning Contact-Rich Tasks Through Robot-Free Visuo-Tactile Manipulation Interface
Apr 08, 2025Tactile information plays a crucial role for humans and robots to interact effectively with their environment, particularly for tasks requiring the understanding of contact properties. Solving such dexterous manipulation tasks often relies on imitation learning from demonstration datasets, which are typically collected via teleoperation systems and often demand substantial time and effort. To address these challenges, we present ViTaMIn, an embodiment-free manipulation interface that seamlessly integrates visual and tactile sensing into a hand-held gripper, enabling data collection without the need for teleoperation. Our design employs a compliant Fin Ray gripper with tactile sensing, allowing operators to perceive force feedback during manipulation for more intuitive operation. Additionally, we propose a multimodal representation learning strategy to obtain pre-trained tactile representations, improving data efficiency and policy robustness. Experiments on seven contact-rich manipulation tasks demonstrate that ViTaMIn significantly outperforms baseline methods, demonstrating its effectiveness for complex manipulation tasks.
Intrinsically-Motivated Humans and Agents in Open-World Exploration
Mar 31, 2025What drives exploration? Understanding intrinsic motivation is a long-standing challenge in both cognitive science and artificial intelligence; numerous objectives have been proposed and used to train agents, yet there remains a gap between human and agent exploration. We directly compare adults, children, and AI agents in a complex open-ended environment, Crafter, and study how common intrinsic objectives: Entropy, Information Gain, and Empowerment, relate to their behavior. We find that only Entropy and Empowerment are consistently positively correlated with human exploration progress, indicating that these objectives may better inform intrinsic reward design for agents. Furthermore, across agents and humans we observe that Entropy initially increases rapidly, then plateaus, while Empowerment increases continuously, suggesting that state diversity may provide more signal in early exploration, while advanced exploration should prioritize control. Finally, we find preliminary evidence that private speech utterances, and particularly goal verbalizations, may aid exploration in children.