 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Q-Chunking
Dec 12, 2025



Temporal-difference (TD) methods learn state and action values efficiently by bootstrapping from their own future value predictions, but such a self-bootstrapping mechanism is prone to bootstrapping bias, where the errors in the value targets accumulate across steps and result in biased value estimates. Recent work has proposed to use chunked critics, which estimate the value of short action sequences ("chunks") rather than individual actions, speeding up value backup. However, extracting policies from chunked critics is challenging: policies must output the entire action chunk open-loop, which can be sub-optimal for environments that require policy reactivity and also challenging to model especially when the chunk length grows. Our key insight is to decouple the chunk length of the critic from that of the policy, allowing the policy to operate over shorter action chunks. We propose a novel algorithm that achieves this by optimizing the policy against a distilled critic for partial action chunks, constructed by optimistically backing up from the original chunked critic to approximate the maximum value achievable when a partial action chunk is extended to a complete one. This design retains the benefits of multi-step value propagation while sidestepping both the open-loop sub-optimality and the difficulty of learning action chunking policies for long action chunks. We evaluate our method on challenging, long-horizon offline goal-conditioned tasks and show that it reliably outperforms prior methods. Code: github.com/ColinQiyangLi/dqc.
Scalable Offline Model-Based RL with Action Chunks
Dec 08, 2025In this paper, we study whether model-based reinforcement learning (RL), in particular model-based value expansion, can provide a scalable recipe for tackling complex, long-horizon tasks in offline RL. Model-based value expansion fits an on-policy value function using length-n imaginary rollouts generated by the current policy and a learned dynamics model. While larger n reduces bias in value bootstrapping, it amplifies accumulated model errors over long horizons, degrading future predictions. We address this trade-off with an \emph{action-chunk} model that predicts a future state from a sequence of actions (an "action chunk") instead of a single action, which reduces compounding errors. In addition, instead of directly training a policy to maximize rewards, we employ rejection sampling from an expressive behavioral action-chunk policy, which prevents model exploitation from out-of-distribution actions. We call this recipe \textbf{Model-Based RL with Action Chunks (MAC)}. Through experiments on highly challenging tasks with large-scale datasets of up to 100M transitions, we show that MAC achieves the best performance among offline model-based RL algorithms, especially on challenging long-horizon tasks.
Transitive RL: Value Learning via Divide and Conquer
Oct 26, 2025



In this work, we present Transitive Reinforcement Learning (TRL), a new value learning algorithm based on a divide-and-conquer paradigm. TRL is designed for offline goal-conditioned reinforcement learning (GCRL) problems, where the aim is to find a policy that can reach any state from any other state in the smallest number of steps. TRL converts a triangle inequality structure present in GCRL into a practical divide-and-conquer value update rule. This has several advantages compared to alternative value learning paradigms. Compared to temporal difference (TD) methods, TRL suffers less from bias accumulation, as in principle it only requires $O(\log T)$ recursions (as opposed to $O(T)$ in TD learning) to handle a length-$T$ trajectory. Unlike Monte Carlo methods, TRL suffers less from high variance as it performs dynamic programming. Experimentally, we show that TRL achieves the best performance in highly challenging, long-horizon benchmark tasks compared to previous offline GCRL algorithms.
Intention-Conditioned Flow Occupancy Models
Jun 10, 2025Large-scale pre-training has fundamentally changed how machine learning research is done today: large foundation models are trained once, and then can be used by anyone in the community (including those without data or compute resources to train a model from scratch) to adapt and fine-tune to specific tasks. Applying this same framework to reinforcement learning (RL) is appealing because it offers compelling avenues for addressing core challenges in RL, including sample efficiency and robustness. However, there remains a fundamental challenge to pre-train large models in the context of RL: actions have long-term dependencies, so training a foundation model that reasons across time is important. Recent advances in generative AI have provided new tools for modeling highly complex distributions. In this paper, we build a probabilistic model to predict which states an agent will visit in the temporally distant future (i.e., an occupancy measure) using flow matching. As large datasets are often constructed by many distinct users performing distinct tasks, we include in our model a latent variable capturing the user intention. This intention increases the expressivity of our model, and enables adaptation with generalized policy improvement. We call our proposed method intention-conditioned flow occupancy models (InFOM). Comparing with alternative methods for pre-training, our experiments on $36$ state-based and $4$ image-based benchmark tasks demonstrate that the proposed method achieves $1.8 \times$ median improvement in returns and increases success rates by $36\%$. Website: https://chongyi-zheng.github.io/infom Code: https://github.com/chongyi-zheng/infom
Horizon Reduction Makes RL Scalable
Jun 08, 2025



In this work, we study the scalability of offline reinforcement learning (RL) algorithms. In principle, a truly scalable offline RL algorithm should be able to solve any given problem, regardless of its complexity, given sufficient data, compute, and model capacity. We investigate if and how current offline RL algorithms match up to this promise on diverse, challenging, previously unsolved tasks, using datasets up to 1000x larger than typical offline RL datasets. We observe that despite scaling up data, many existing offline RL algorithms exhibit poor scaling behavior, saturating well below the maximum performance. We hypothesize that the horizon is the main cause behind the poor scaling of offline RL. We empirically verify this hypothesis through several analysis experiments, showing that long horizons indeed present a fundamental barrier to scaling up offline RL. We then show that various horizon reduction techniques substantially enhance scalability on challenging tasks. Based on our insights, we also introduce a minimal yet scalable method named SHARSA that effectively reduces the horizon. SHARSA achieves the best asymptotic performance and scaling behavior among our evaluation methods, showing that explicitly reducing the horizon unlocks the scalability of offline RL. Code: https://github.com/seohongpark/horizon-reduction
Diffusion Guidance Is a Controllable Policy Improvement Operator
May 29, 2025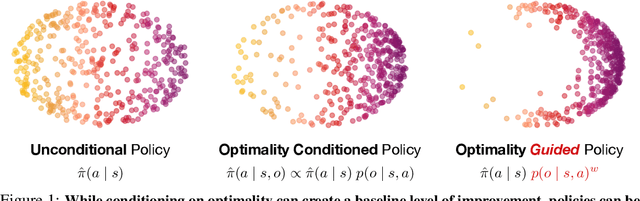
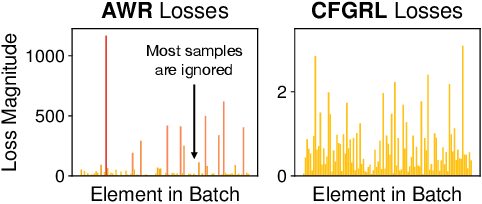
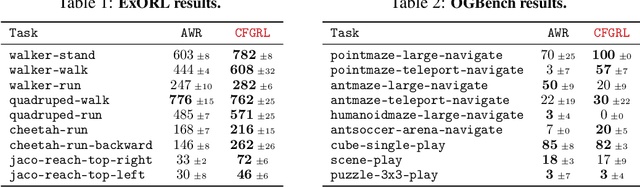
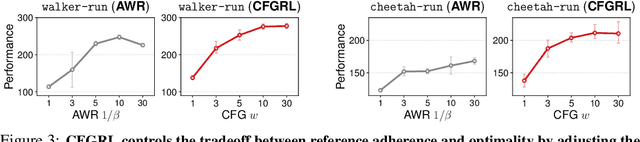
At the core of reinforcement learning is the idea of learning beyond the performance in the data. However, scaling such systems has proven notoriously tricky. In contrast, techniques from generative modeling have proven remarkably scalable and are simple to train. In this work, we combine these strengths, by deriving a direct relation between policy improvement and guidance of diffusion models. The resulting framework, CFGRL, is trained with the simplicity of supervised learning, yet can further improve on the policies in the data. On offline RL tasks, we observe a reliable trend -- increased guidance weighting leads to increased performance. Of particular importance, CFGRL can operate without explicitly learning a value function, allowing us to generalize simple supervised methods (e.g., goal-conditioned behavioral cloning) to further prioritize optimality, gaining performance for "free" across the board.
Flow Q-Learning
Feb 04, 2025We present flow Q-learning (FQL), a simple and performant offline reinforcement learning (RL) method that leverages an expressive flow-matching policy to model arbitrarily complex action distributions in data. Training a flow policy with RL is a tricky problem, due to the iterative nature of the action generation process. We address this challenge by training an expressive one-step policy with RL, rather than directly guiding an iterative flow policy to maximize values. This way, we can completely avoid unstable recursive backpropagation, eliminate costly iterative action generation at test time, yet still mostly maintain expressivity. We experimentally show that FQL leads to strong performance across 73 challenging state- and pixel-based OGBench and D4RL tasks in offline RL and offline-to-online RL. Project page: https://seohong.me/projects/fql/
GHIL-Glue: Hierarchical Control with Filtered Subgoal Images
Oct 26, 2024



Image and video generative models that are pre-trained on Internet-scale data can greatly increase the generalization capacity of robot learning systems. These models can function as high-level planners, generating intermediate subgoals for low-level goal-conditioned policies to reach. However, the performance of these systems can be greatly bottlenecked by the interface between generative models and low-level controllers. For example, generative models may predict photorealistic yet physically infeasible frames that confuse low-level policies. Low-level policies may also be sensitive to subtle visual artifacts in generated goal images. This paper addresses these two facets of generalization, providing an interface to effectively "glue together" language-conditioned image or video prediction models with low-level goal-conditioned policies. Our method, Generative Hierarchical Imitation Learning-Glue (GHIL-Glue), filters out subgoals that do not lead to task progress and improves the robustness of goal-conditioned policies to generated subgoals with harmful visual artifacts. We find in extensive experiments in both simulated and real environments that GHIL-Glue achieves a 25% improvement across several hierarchical models that leverage generative subgoals, achieving a new state-of-the-art on the CALVIN simulation benchmark for policies using observations from a single RGB camera. GHIL-Glue also outperforms other generalist robot policies across 3/4 language-conditioned manipulation tasks testing zero-shot generalization in physical experiments.
OGBench: Benchmarking Offline Goal-Conditioned RL
Oct 26, 2024Offline goal-conditioned reinforcement learning (GCRL) is a major problem in reinforcement learning (RL) because it provides a simple, unsupervised, and domain-agnostic way to acquire diverse behaviors and representations from unlabeled data without rewards. Despite the importance of this setting, we lack a standard benchmark that can systematically evaluate the capabilities of offline GCRL algorithms. In this work, we propose OGBench, a new, high-quality benchmark for algorithms research in offline goal-conditioned RL. OGBench consists of 8 types of environments, 85 datasets, and reference implementations of 6 representative offline GCRL algorithms. We have designed these challenging and realistic environments and datasets to directly probe different capabilities of algorithms, such as stitching, long-horizon reasoning, and the ability to handle high-dimensional inputs and stochasticity. While representative algorithms may rank similarly on prior benchmarks, our experiments reveal stark strengths and weaknesses in these different capabilities, providing a strong foundation for building new algorithms. Project page: https://seohong.me/projects/ogbench
Unsupervised-to-Online Reinforcement Learning
Aug 27, 2024Offline-to-online reinforcement learning (RL), a framework that trains a policy with offline RL and then further fine-tunes it with online RL, has been considered a promising recipe for data-driven decision-making. While sensible, this framework has drawbacks: it requires domain-specific offline RL pre-training for each task, and is often brittle in practice. In this work, we propose unsupervised-to-online RL (U2O RL), which replaces domain-specific supervised offline RL with unsupervised offline RL, as a better alternative to offline-to-online RL. U2O RL not only enables reusing a single pre-trained model for multiple downstream tasks, but also learns better representations, which often result in even better performance and stability than supervised offline-to-online RL. To instantiate U2O RL in practice, we propose a general recipe for U2O RL to bridge task-agnostic unsupervised offline skill-based policy pre-training and supervised online fine-tuning. Throughout our experiments in nine state-based and pixel-based environments, we empirically demonstrate that U2O RL achieves strong performance that matches or even outperforms previous offline-to-online RL approaches, while being able to reuse a single pre-trained model for a number of different downstream tasks.