 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Global Geometric Analysis of Maximal Coding Rate Reduction
Jun 04, 2024



The maximal coding rate reduction (MCR$^2$) objective for learning structured and compact deep representations is drawing increasing attention, especially after its recent usage in the derivation of fully explainable and highly effective deep network architectures. However, it lacks a complete theoretical justification: only the properties of its global optima are known, and its global landscape has not been studied. In this work, we give a complete characterization of the properties of all its local and global optima, as well as other types of critical points. Specifically, we show that each (local or global) maximizer of the MCR$^2$ problem corresponds to a low-dimensional, discriminative, and diverse representation, and furthermore, each critical point of the objective is either a local maximizer or a strict saddle point. Such a favorable landscape makes MCR$^2$ a natural choice of objective for learning diverse and discriminative representations via first-order optimization methods. To validate our theoretical findings, we conduct extensive experiments on both synthetic and real data sets.
MoDGS: Dynamic Gaussian Splatting from Causually-captured Monocular Videos
Jun 01, 2024



In this paper, we propose MoDGS, a new pipeline to render novel-view images in dynamic scenes using only casually captured monocular videos. Previous monocular dynamic NeRF or Gaussian Splatting methods strongly rely on the rapid movement of input cameras to construct multiview consistency but fail to reconstruct dynamic scenes on casually captured input videos whose cameras are static or move slowly. To address this challenging task, MoDGS adopts recent single-view depth estimation methods to guide the learning of the dynamic scene. Then, a novel 3D-aware initialization method is proposed to learn a reasonable deformation field and a new robust depth loss is proposed to guide the learning of dynamic scene geometry. Comprehensive experiments demonstrate that MoDGS is able to render high-quality novel view images of dynamic scenes from just a casually captured monocular video, which outperforms baseline methods by a significant margin.
A Full-duplex Speech Dialogue Scheme Based On Large Language Models
May 29, 2024



We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models
May 23, 2024Large language models (LLMs) need knowledge updates to meet the ever-growing world facts and correct the hallucinated responses, facilitating the methods of lifelong model editing. Where the updated knowledge resides in memories is a fundamental question for model editing. In this paper, we find that editing either long-term memory (direct model parameters) or working memory (non-parametric knowledge of neural network activations/representations by retrieval) will result in an impossible triangle -- reliability, generalization, and locality can not be realized together in the lifelong editing settings. For long-term memory, directly editing the parameters will cause conflicts with irrelevant pretrained knowledge or previous edits (poor reliability and locality). For working memory, retrieval-based activations can hardly make the model understand the edits and generalize (poor generalization). Therefore, we propose WISE to bridge the gap between memories. In WISE, we design a dual parametric memory scheme, which consists of the main memory for the pretrained knowledge and a side memory for the edited knowledge. We only edit the knowledge in the side memory and train a router to decide which memory to go through when given a query. For continual editing, we devise a knowledge-sharding mechanism where different sets of edits reside in distinct subspaces of parameters, and are subsequently merged into a shared memory without conflicts. Extensive experiments show that WISE can outperform previous model editing methods and overcome the impossible triangle under lifelong model editing of question answering, hallucination, and out-of-distribution settings across trending LLM architectures, e.g., GPT, LLaMA, and Mistral. Code will be released at https://github.com/zjunlp/EasyEdit.
RaFe: Ranking Feedback Improves Query Rewriting for RAG
May 23, 2024



As Large Language Models (LLMs) and Retrieval Augmentation Generation (RAG) techniques have evolved, query rewriting has been widely incorporated into the RAG system for downstream tasks like open-domain QA. Many works have attempted to utilize small models with reinforcement learning rather than costly LLMs to improve query rewriting. However, current methods require annotations (e.g., labeled relevant documents or downstream answers) or predesigned rewards for feedback, which lack generalization, and fail to utilize signals tailored for query rewriting. In this paper, we propose ours, a framework for training query rewriting models free of annotations. By leveraging a publicly available reranker, ours~provides feedback aligned well with the rewriting objectives. Experimental results demonstrate that ours~can obtain better performance than baselines.
Multi-Objective Optimization-Based Waveform Design for Multi-User and Multi-Target MIMO-ISAC Systems
May 22, 2024Integrated sensing and communication (ISAC) opens up new service possibilities for sixth-generation (6G) systems, where both communication and sensing (C&S) functionalities co-exist by sharing the same hardware platform and radio resource. In this paper, we investigate the waveform design problem in a downlink multi-user and multi-target ISAC system under different C&S performance preferences. The multi-user interference (MUI) may critically degrade the communication performance. To eliminate the MUI, we employ the constructive interference mechanism into the ISAC system, which saves the power budget for communication. However, due to the conflict between C&S metrics, it is intractable for the ISAC system to achieve the optimal performance of C&S objective simultaneously. Therefore, it is important to strike a tradeoff between C&S objectives. By virtue of the multi-objective optimization theory, we propose a weighted Tchebycheff-based transformation method to re-frame the C&S trade-off problem as a Pareto-optimal problem, thus effectively tackling the constraints in ISAC systems. Finally, simulation results reveal the trade-off relation between C&S performances, which provides insights for the flexible waveform design under different C&S performance preferences in MIMO-ISAC systems.
Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning
May 22, 2024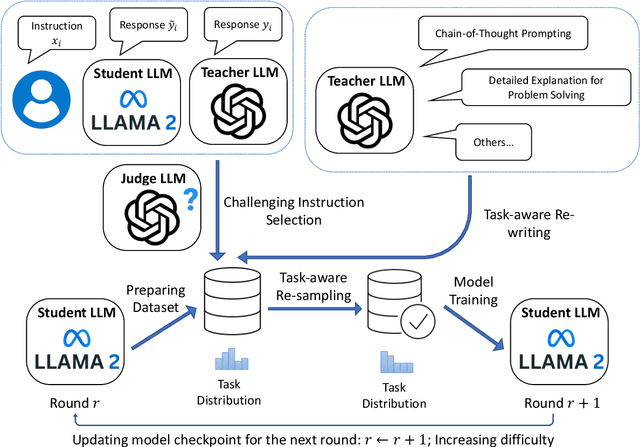

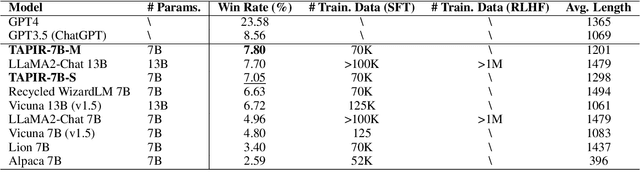
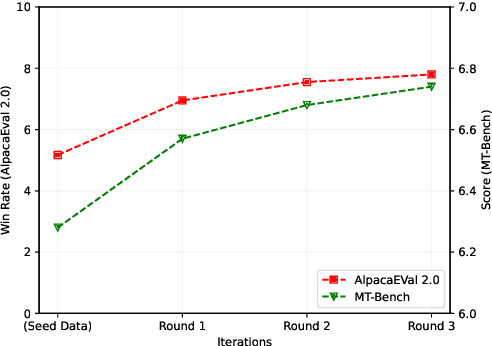
The process of instruction tuning aligns pre-trained large language models (LLMs) with open-domain instructions and human-preferred responses. While several studies have explored autonomous approaches to distilling and annotating instructions from more powerful proprietary LLMs, such as ChatGPT, they often neglect the impact of task distributions and the varying difficulty of instructions of the training sets. This oversight can lead to imbalanced knowledge capabilities and poor generalization powers of small student LLMs. To address this challenge, we introduce Task-Aware Curriculum Planning for Instruction Refinement (TAPIR), a multi-round distillation framework with balanced task distributions and dynamic difficulty adjustment. This approach utilizes an oracle LLM to select instructions that are difficult for a student LLM to follow and distill instructions with balanced task distributions. By incorporating curriculum planning, our approach systematically escalates the difficulty levels, progressively enhancing the student LLM's capabilities. We rigorously evaluate TAPIR using two widely recognized benchmarks, including AlpacaEval 2.0 and MT-Bench. The empirical results demonstrate that the student LLMs, trained with our method and less training data, outperform larger instruction-tuned models and strong distillation baselines. The improvement is particularly notable in complex tasks, such as logical reasoning and code generation.
C3L: Content Correlated Vision-Language Instruction Tuning Data Generation via Contrastive Learning
May 21, 2024Vision-Language Instruction Tuning (VLIT) is a critical training phase for Large Vision-Language Models (LVLMs). With the improving capabilities of open-source LVLMs, researchers have increasingly turned to generate VLIT data by using open-source LVLMs and achieved significant progress. However, such data generation approaches are bottlenecked by the following challenges: 1) Since multi-modal models tend to be influenced by prior language knowledge, directly using LVLMs to generate VLIT data would inevitably lead to low content relevance between generated data and images. 2) To improve the ability of the models to generate VLIT data, previous methods have incorporated an additional training phase to boost the generative capacity. This process hurts the generalization of the models to unseen inputs (i.e., "exposure bias" problem). In this paper, we propose a new Content Correlated VLIT data generation via Contrastive Learning (C3L). Specifically, we design a new content relevance module which enhances the content relevance between VLIT data and images by computing Image Instruction Correspondence Scores S(I2C). Moreover, a contrastive learning module is introduced to further boost the VLIT data generation capability of the LVLMs. A large number of automatic measures on four benchmarks show the effectiveness of our method.
Learning Social Graph for Inactive User Recommendation
May 08, 2024



Social relations have been widely incorporated into recommender systems to alleviate data sparsity problem. However, raw social relations don't always benefit recommendation due to their inferior quality and insufficient quantity, especially for inactive users, whose interacted items are limited. In this paper, we propose a novel social recommendation method called LSIR (\textbf{L}earning \textbf{S}ocial Graph for \textbf{I}nactive User \textbf{R}ecommendation) that learns an optimal social graph structure for social recommendation, especially for inactive users. LSIR recursively aggregates user and item embeddings to collaboratively encode item and user features. Then, graph structure learning (GSL) is employed to refine the raw user-user social graph, by removing noisy edges and adding new edges based on the enhanced embeddings. Meanwhile, mimic learning is implemented to guide active users in mimicking inactive users during model training, which improves the construction of new edges for inactive users. Extensive experiments on real-world datasets demonstrate that LSIR achieves significant improvements of up to 129.58\% on NDCG in inactive user recommendation. Our code is available at~\url{https://github.com/liun-online/LSIR}.
Towards Continual Knowledge Graph Embedding via Incremental Distillation
May 07, 2024



Traditional knowledge graph embedding (KGE) methods typically require preserving the entire knowledge graph (KG) with significant training costs when new knowledge emerges. To address this issue, the continual knowledge graph embedding (CKGE) task has been proposed to train the KGE model by learning emerging knowledge efficiently while simultaneously preserving decent old knowledge. However, the explicit graph structure in KGs, which is critical for the above goal, has been heavily ignored by existing CKGE methods. On the one hand, existing methods usually learn new triples in a random order, destroying the inner structure of new KGs. On the other hand, old triples are preserved with equal priority, failing to alleviate catastrophic forgetting effectively. In this paper, we propose a competitive method for CKGE based on incremental distillation (IncDE), which considers the full use of the explicit graph structure in KGs. First, to optimize the learning order, we introduce a hierarchical strategy, ranking new triples for layer-by-layer learning. By employing the inter- and intra-hierarchical orders together, new triples are grouped into layers based on the graph structure features. Secondly, to preserve the old knowledge effectively, we devise a novel incremental distillation mechanism, which facilitates the seamless transfer of entity representations from the previous layer to the next one, promoting old knowledge preservation. Finally, we adopt a two-stage training paradigm to avoid the over-corruption of old knowledge influenced by under-trained new knowledge. Experimental results demonstrate the superiority of IncDE over state-of-the-art baselines. Notably, the incremental distillation mechanism contributes to improvements of 0.2%-6.5% in the mean reciprocal rank (MRR) score.