 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData augmentation for efficient learning from parametric experts
May 23, 2022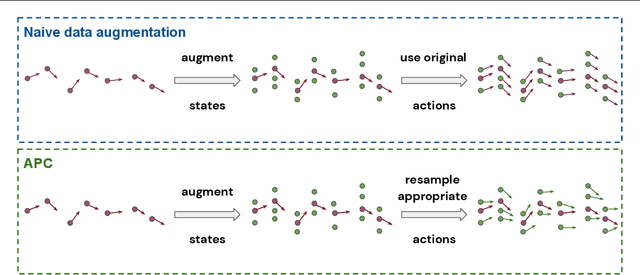
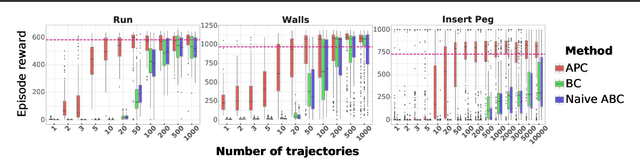
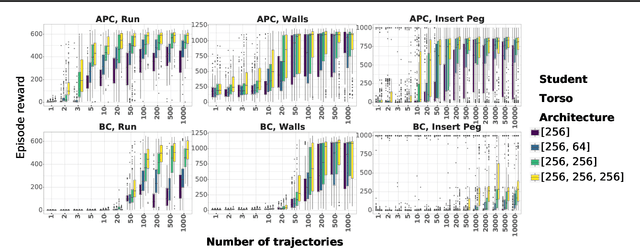
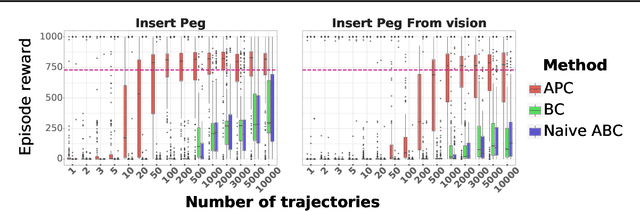
We present a simple, yet powerful data-augmentation technique to enable data-efficient learning from parametric experts for reinforcement and imitation learning. We focus on what we call the policy cloning setting, in which we use online or offline queries of an expert or expert policy to inform the behavior of a student policy. This setting arises naturally in a number of problems, for instance as variants of behavior cloning, or as a component of other algorithms such as DAGGER, policy distillation or KL-regularized RL. Our approach, augmented policy cloning (APC), uses synthetic states to induce feedback-sensitivity in a region around sampled trajectories, thus dramatically reducing the environment interactions required for successful cloning of the expert. We achieve highly data-efficient transfer of behavior from an expert to a student policy for high-degrees-of-freedom control problems. We demonstrate the benefit of our method in the context of several existing and widely used algorithms that include policy cloning as a constituent part. Moreover, we highlight the benefits of our approach in two practically relevant settings (a) expert compression, i.e. transfer to a student with fewer parameters; and (b) transfer from privileged experts, i.e. where the expert has a different observation space than the student, usually including access to privileged information.
A Generalist Agent
May 19, 2022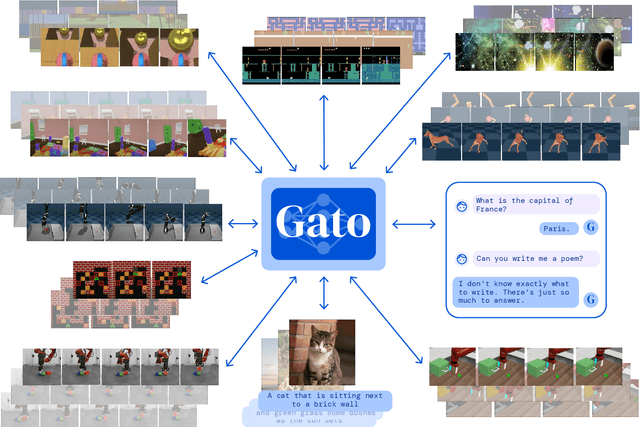
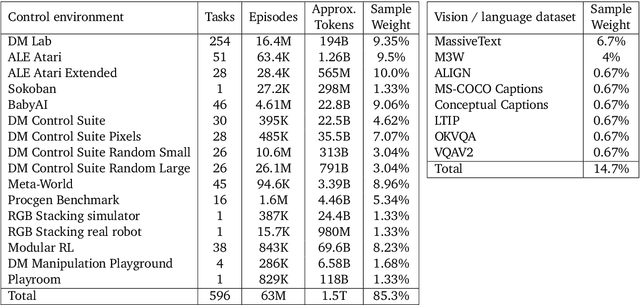
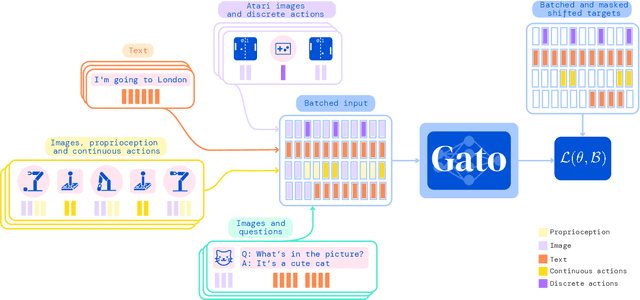

Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
Revisiting Gaussian mixture critics in off-policy reinforcement learning: a sample-based approach
Apr 22, 2022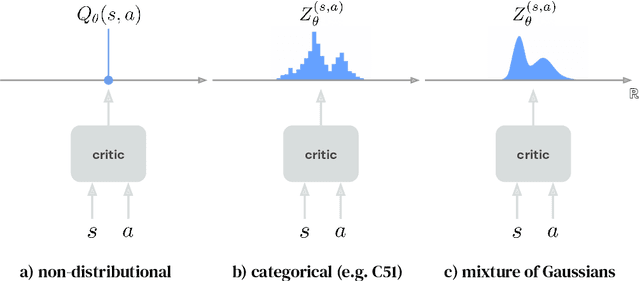
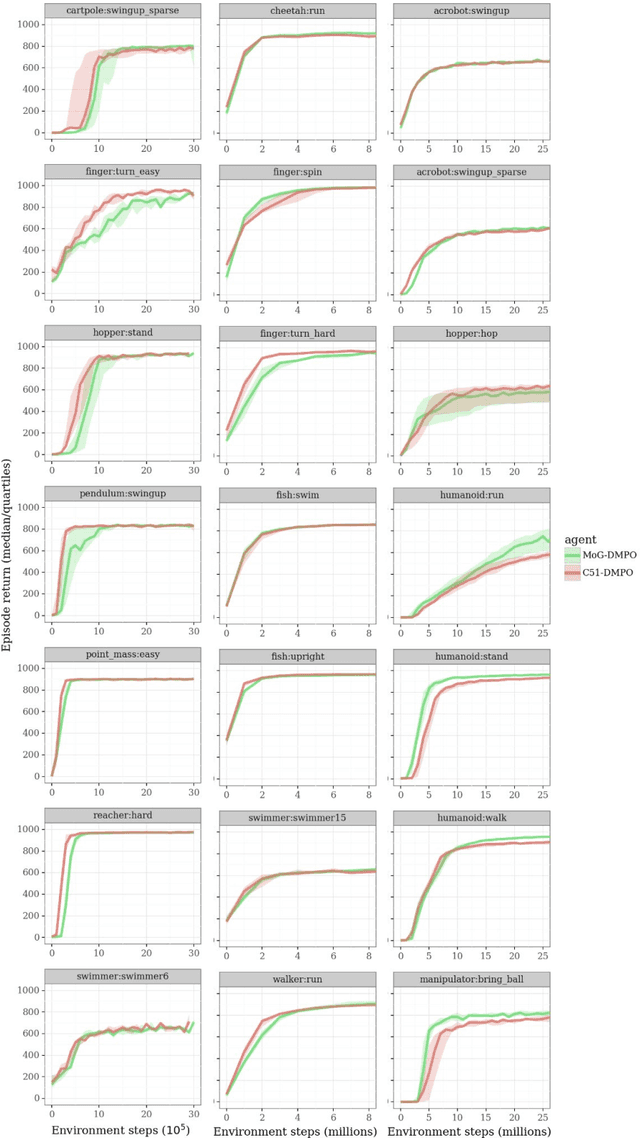
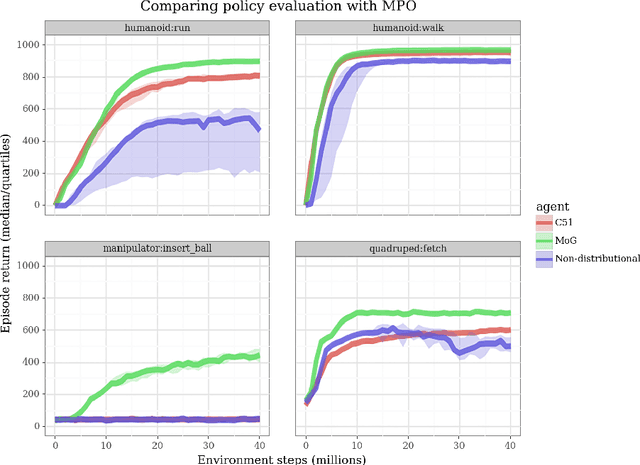
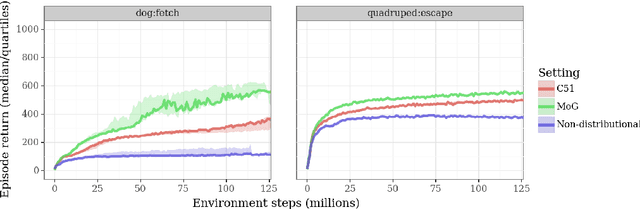
Actor-critic algorithms that make use of distributional policy evaluation have frequently been shown to outperform their non-distributional counterparts on many challenging control tasks. Examples of this behavior include the D4PG and DMPO algorithms as compared to DDPG and MPO, respectively [Barth-Maron et al., 2018; Hoffman et al., 2020]. However, both agents rely on the C51 critic for value estimation.One major drawback of the C51 approach is its requirement of prior knowledge about the minimum andmaximum values a policy can attain as well as the number of bins used, which fixes the resolution ofthe distributional estimate. While the DeepMind control suite of tasks utilizes standardized rewards and episode lengths, thus enabling the entire suite to be solved with a single setting of these hyperparameters, this is often not the case. This paper revisits a natural alternative that removes this requirement, namelya mixture of Gaussians, and a simple sample-based loss function to train it in an off-policy regime. We empirically evaluate its performance on a broad range of continuous control tasks and demonstrate that it eliminates the need for these distributional hyperparameters and achieves state-of-the-art performance on a variety of challenging tasks (e.g. the humanoid, dog, quadruped, and manipulator domains). Finallywe provide an implementation in the Acme agent repository.
COptiDICE: Offline Constrained Reinforcement Learning via Stationary Distribution Correction Estimation
Apr 19, 2022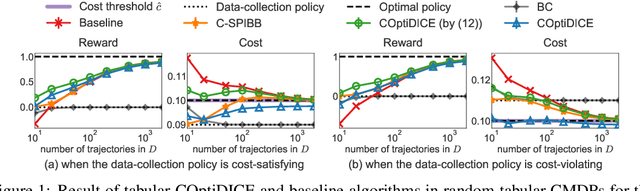
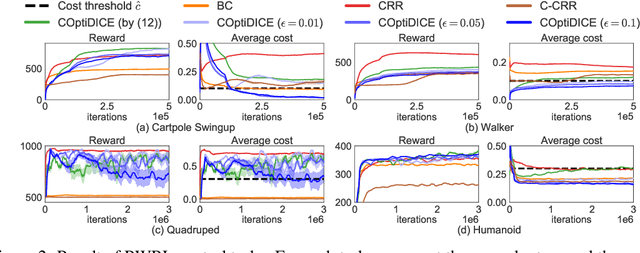
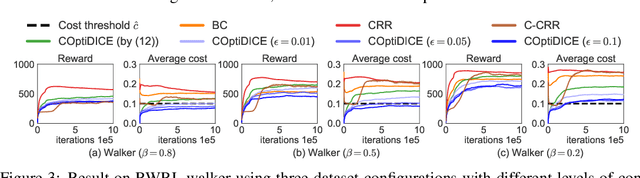
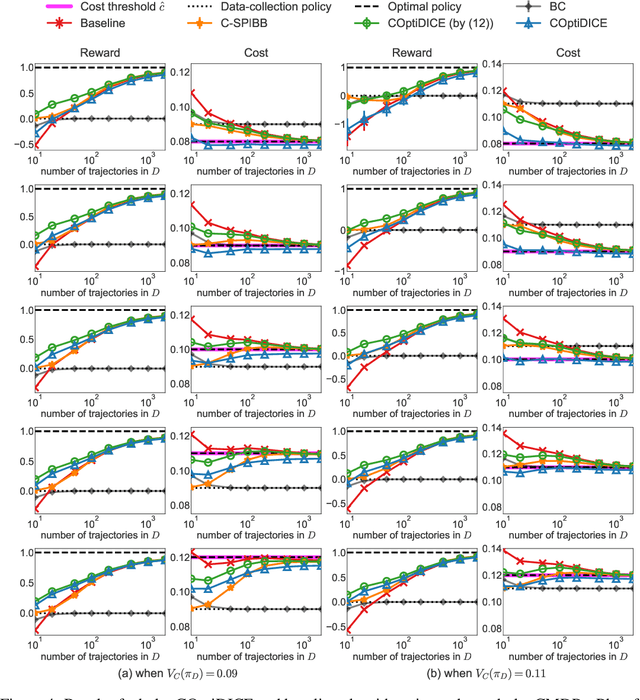
We consider the offline constrained reinforcement learning (RL) problem, in which the agent aims to compute a policy that maximizes expected return while satisfying given cost constraints, learning only from a pre-collected dataset. This problem setting is appealing in many real-world scenarios, where direct interaction with the environment is costly or risky, and where the resulting policy should comply with safety constraints. However, it is challenging to compute a policy that guarantees satisfying the cost constraints in the offline RL setting, since the off-policy evaluation inherently has an estimation error. In this paper, we present an offline constrained RL algorithm that optimizes the policy in the space of the stationary distribution. Our algorithm, COptiDICE, directly estimates the stationary distribution corrections of the optimal policy with respect to returns, while constraining the cost upper bound, with the goal of yielding a cost-conservative policy for actual constraint satisfaction. Experimental results show that COptiDICE attains better policies in terms of constraint satisfaction and return-maximization, outperforming baseline algorithms.
Offline Distillation for Robot Lifelong Learning with Imbalanced Experience
Apr 12, 2022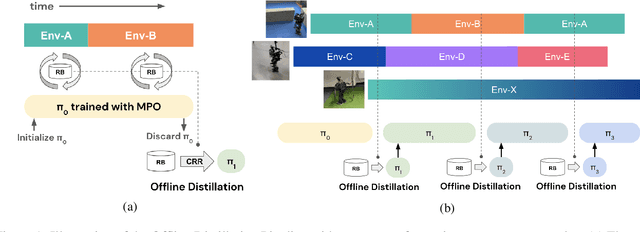
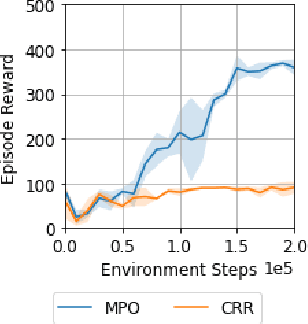
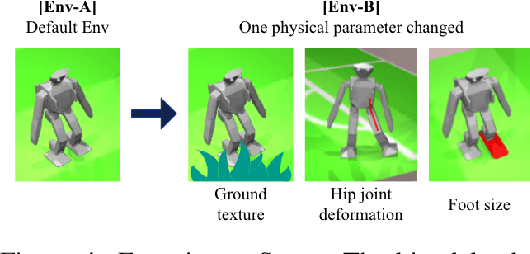
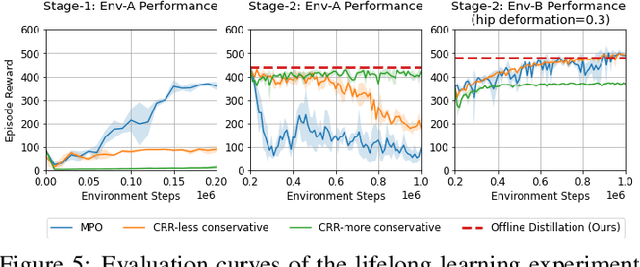
Robots will experience non-stationary environment dynamics throughout their lifetime: the robot dynamics can change due to wear and tear, or its surroundings may change over time. Eventually, the robots should perform well in all of the environment variations it has encountered. At the same time, it should still be able to learn fast in a new environment. We investigate two challenges in such a lifelong learning setting: first, existing off-policy algorithms struggle with the trade-off between being conservative to maintain good performance in the old environment and learning efficiently in the new environment. We propose the Offline Distillation Pipeline to break this trade-off by separating the training procedure into interleaved phases of online interaction and offline distillation. Second, training with the combined datasets from multiple environments across the lifetime might create a significant performance drop compared to training on the datasets individually. Our hypothesis is that both the imbalanced quality and size of the datasets exacerbate the extrapolation error of the Q-function during offline training over the "weaker" dataset. We propose a simple fix to the issue by keeping the policy closer to the dataset during the distillation phase. In the experiments, we demonstrate these challenges and the proposed solutions with a simulated bipedal robot walking task across various environment changes. We show that the Offline Distillation Pipeline achieves better performance across all the encountered environments without affecting data collection. We also provide a comprehensive empirical study to support our hypothesis on the data imbalance issue.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022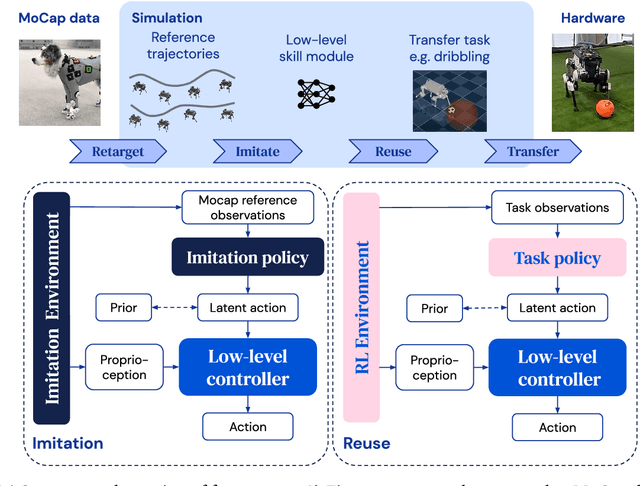

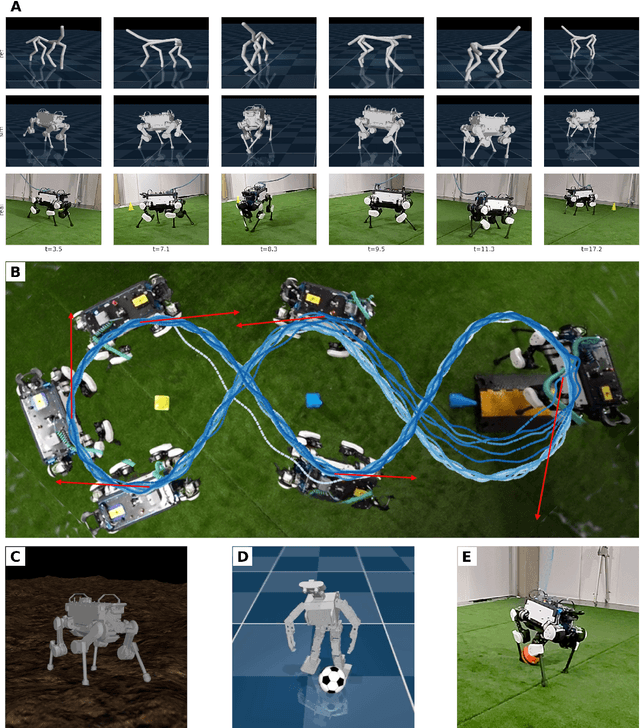
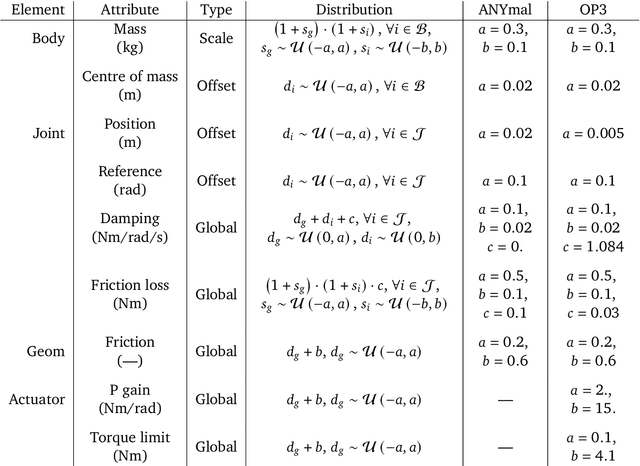
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.
Retrieval-Augmented Reinforcement Learning
Mar 09, 2022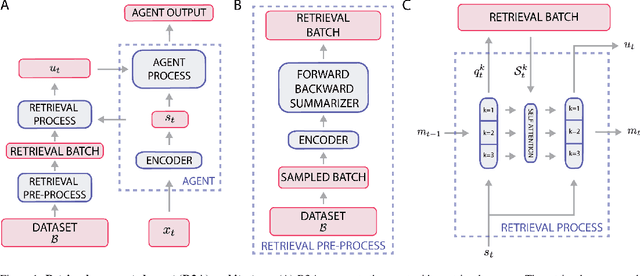

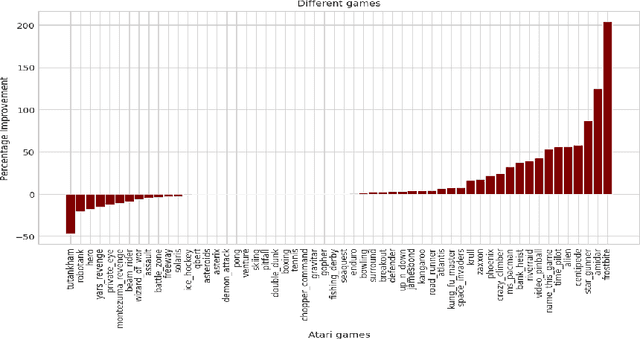
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.
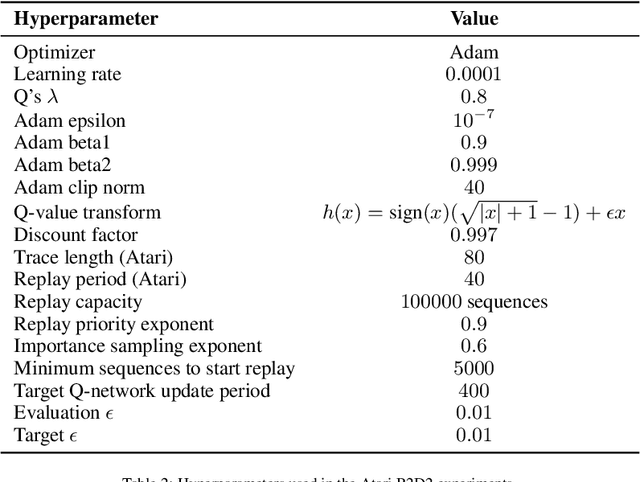
NeuPL: Neural Population Learning
Feb 15, 2022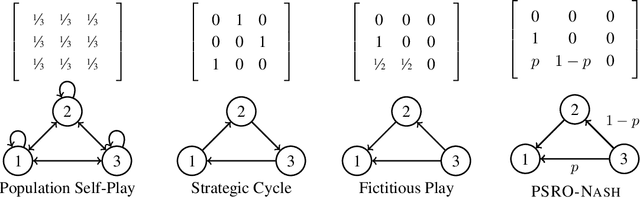
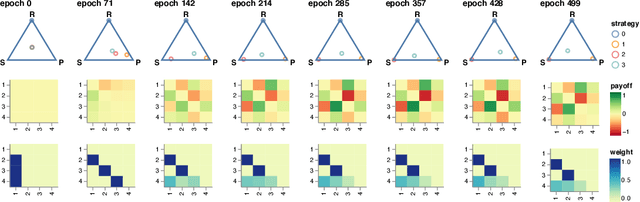
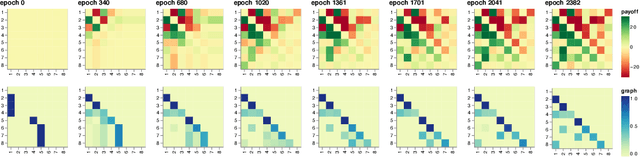
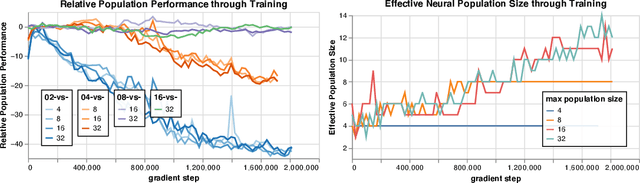
Learning in strategy games (e.g. StarCraft, poker) requires the discovery of diverse policies. This is often achieved by iteratively training new policies against existing ones, growing a policy population that is robust to exploit. This iterative approach suffers from two issues in real-world games: a) under finite budget, approximate best-response operators at each iteration needs truncating, resulting in under-trained good-responses populating the population; b) repeated learning of basic skills at each iteration is wasteful and becomes intractable in the presence of increasingly strong opponents. In this work, we propose Neural Population Learning (NeuPL) as a solution to both issues. NeuPL offers convergence guarantees to a population of best-responses under mild assumptions. By representing a population of policies within a single conditional model, NeuPL enables transfer learning across policies. Empirically, we show the generality, improved performance and efficiency of NeuPL across several test domains. Most interestingly, we show that novel strategies become more accessible, not less, as the neural population expands.
Learning Transferable Motor Skills with Hierarchical Latent Mixture Policies
Dec 09, 2021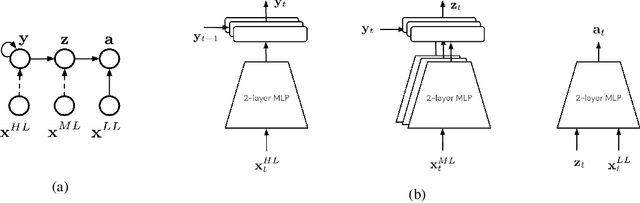
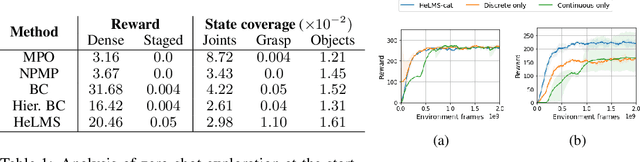
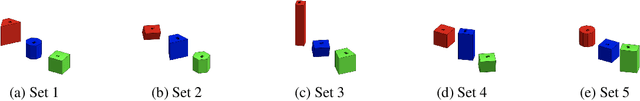
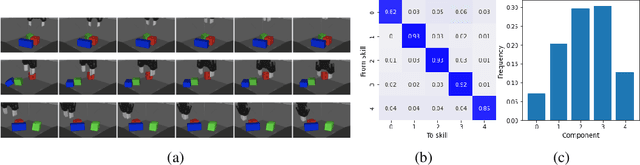
For robots operating in the real world, it is desirable to learn reusable behaviours that can effectively be transferred and adapted to numerous tasks and scenarios. We propose an approach to learn abstract motor skills from data using a hierarchical mixture latent variable model. In contrast to existing work, our method exploits a three-level hierarchy of both discrete and continuous latent variables, to capture a set of high-level behaviours while allowing for variance in how they are executed. We demonstrate in manipulation domains that the method can effectively cluster offline data into distinct, executable behaviours, while retaining the flexibility of a continuous latent variable model. The resulting skills can be transferred and fine-tuned on new tasks, unseen objects, and from state to vision-based policies, yielding better sample efficiency and asymptotic performance compared to existing skill- and imitation-based methods. We further analyse how and when the skills are most beneficial: they encourage directed exploration to cover large regions of the state space relevant to the task, making them most effective in challenging sparse-reward settings.
Learning Coordinated Terrain-Adaptive Locomotion by Imitating a Centroidal Dynamics Planner
Oct 30, 2021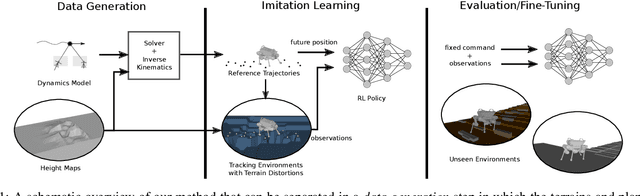
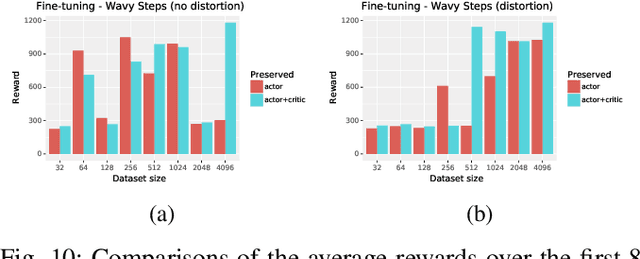

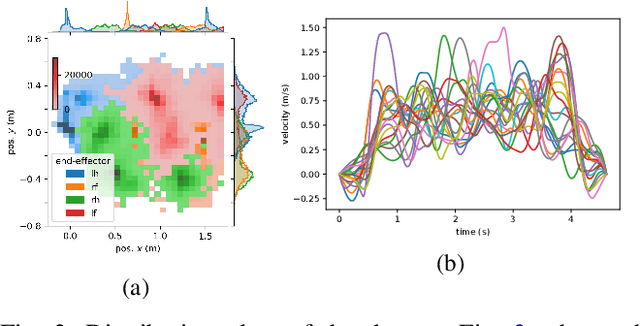
Dynamic quadruped locomotion over challenging terrains with precise foot placements is a hard problem for both optimal control methods and Reinforcement Learning (RL). Non-linear solvers can produce coordinated constraint satisfying motions, but often take too long to converge for online application. RL methods can learn dynamic reactive controllers but require carefully tuned shaping rewards to produce good gaits and can have trouble discovering precise coordinated movements. Imitation learning circumvents this problem and has been used with motion capture data to extract quadruped gaits for flat terrains. However, it would be costly to acquire motion capture data for a very large variety of terrains with height differences. In this work, we combine the advantages of trajectory optimization and learning methods and show that terrain adaptive controllers can be obtained by training policies to imitate trajectories that have been planned over procedural terrains by a non-linear solver. We show that the learned policies transfer to unseen terrains and can be fine-tuned to dynamically traverse challenging terrains that require precise foot placements and are very hard to solve with standard RL.