 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer from Teachers to Learners in Growing-Batch Reinforcement Learning
May 09, 2023



Standard approaches to sequential decision-making exploit an agent's ability to continually interact with its environment and improve its control policy. However, due to safety, ethical, and practicality constraints, this type of trial-and-error experimentation is often infeasible in many real-world domains such as healthcare and robotics. Instead, control policies in these domains are typically trained offline from previously logged data or in a growing-batch manner. In this setting a fixed policy is deployed to the environment and used to gather an entire batch of new data before being aggregated with past batches and used to update the policy. This improvement cycle can then be repeated multiple times. While a limited number of such cycles is feasible in real-world domains, the quality and diversity of the resulting data are much lower than in the standard continually-interacting approach. However, data collection in these domains is often performed in conjunction with human experts, who are able to label or annotate the collected data. In this paper, we first explore the trade-offs present in this growing-batch setting, and then investigate how information provided by a teacher (i.e., demonstrations, expert actions, and gradient information) can be leveraged at training time to mitigate the sample complexity and coverage requirements for actor-critic methods. We validate our contributions on tasks from the DeepMind Control Suite.
Multi-step Planning for Automated Hyperparameter Optimization with OptFormer
Oct 10, 2022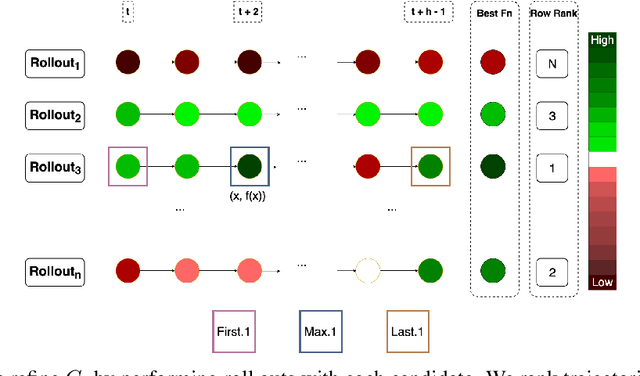
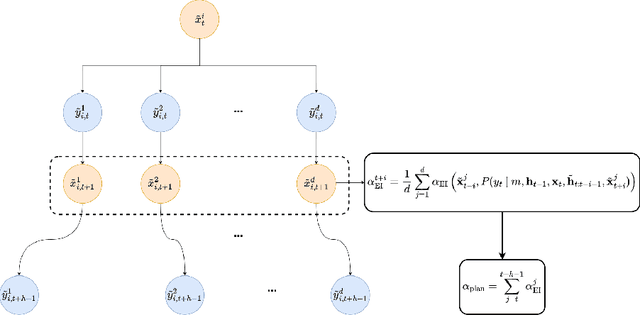
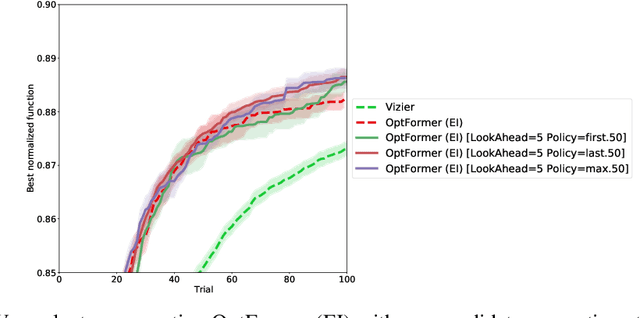
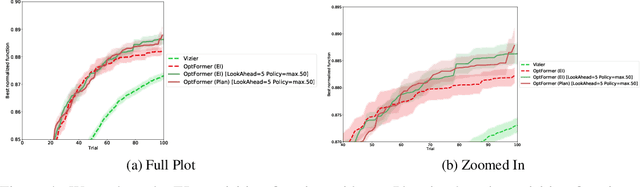
As machine learning permeates more industries and models become more expensive and time consuming to train, the need for efficient automated hyperparameter optimization (HPO) has never been more pressing. Multi-step planning based approaches to hyperparameter optimization promise improved efficiency over myopic alternatives by more effectively balancing out exploration and exploitation. However, the potential of these approaches has not been fully realized due to their technical complexity and computational intensity. In this work, we leverage recent advances in Transformer-based, natural-language-interfaced hyperparameter optimization to circumvent these barriers. We build on top of the recently proposed OptFormer which casts both hyperparameter suggestion and target function approximation as autoregressive generation thus making planning via rollouts simple and efficient. We conduct extensive exploration of different strategies for performing multi-step planning on top of the OptFormer model to highlight its potential for use in constructing non-myopic HPO strategies.
Retrieval-Augmented Reinforcement Learning
Mar 09, 2022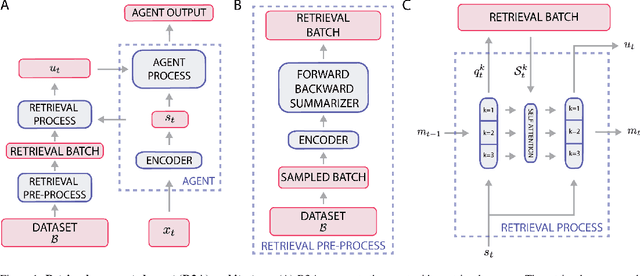

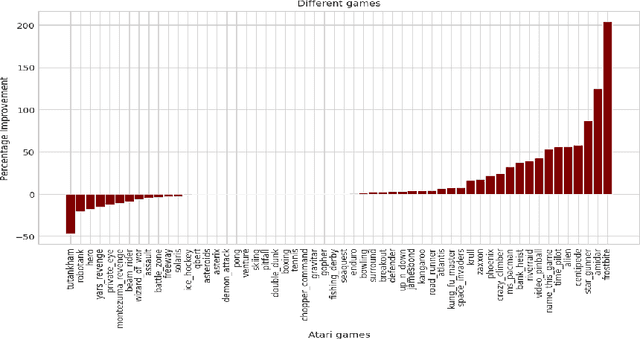
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.
On the role of planning in model-based deep reinforcement learning
Nov 08, 2020

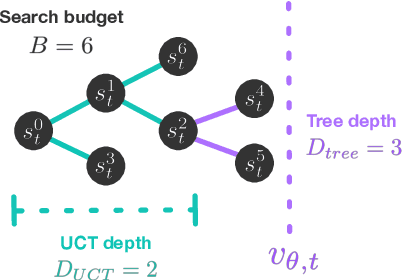
Model-based planning is often thought to be necessary for deep, careful reasoning and generalization in artificial agents. While recent successes of model-based reinforcement learning (MBRL) with deep function approximation have strengthened this hypothesis, the resulting diversity of model-based methods has also made it difficult to track which components drive success and why. In this paper, we seek to disentangle the contributions of recent methods by focusing on three questions: (1) How does planning benefit MBRL agents? (2) Within planning, what choices drive performance? (3) To what extent does planning improve generalization? To answer these questions, we study the performance of MuZero (Schrittwieser et al., 2019), a state-of-the-art MBRL algorithm, under a number of interventions and ablations and across a wide range of environments including control tasks, Atari, and 9x9 Go. Our results suggest the following: (1) The primary benefit of planning is in driving policy learning. (2) Using shallow trees with simple Monte-Carlo rollouts is as performant as more complex methods, except in the most difficult reasoning tasks. (3) Planning alone is insufficient to drive strong generalization. These results indicate where and how to utilize planning in reinforcement learning settings, and highlight a number of open questions for future MBRL research.
Modular Meta-Learning with Shrinkage
Sep 12, 2019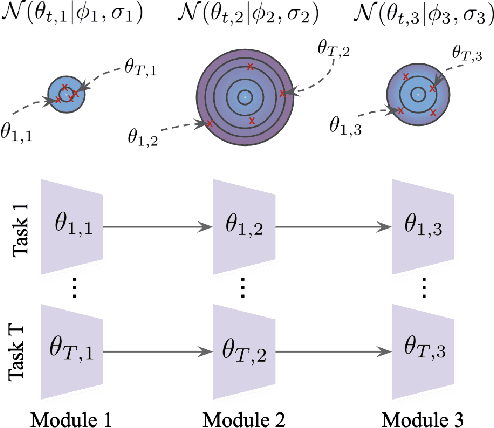
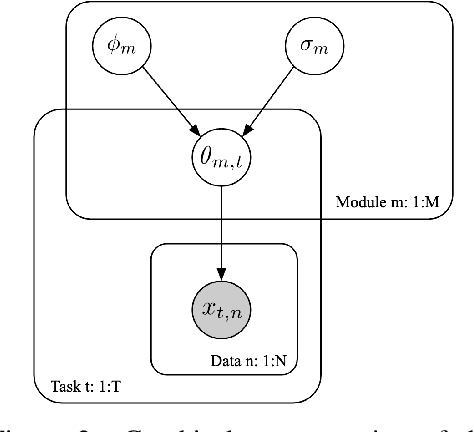
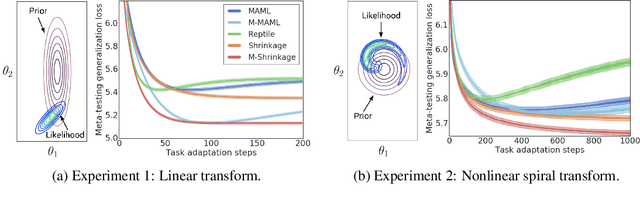
Most gradient-based approaches to meta-learning do not explicitly account for the fact that different parts of the underlying model adapt by different amounts when applied to a new task. For example, the input layers of an image classification convnet typically adapt very little, while the output layers can change significantly. This can cause parts of the model to begin to overfit while others underfit. To address this, we introduce a hierarchical Bayesian model with per-module shrinkage parameters, which we propose to learn by maximizing an approximation of the predictive likelihood using implicit differentiation. Our algorithm subsumes Reptile and outperforms variants of MAML on two synthetic few-shot meta-learning problems.
Deep Learning as a Mixed Convex-Combinatorial Optimization Problem
Apr 16, 2018

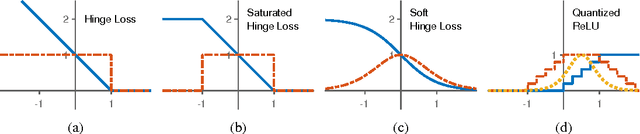
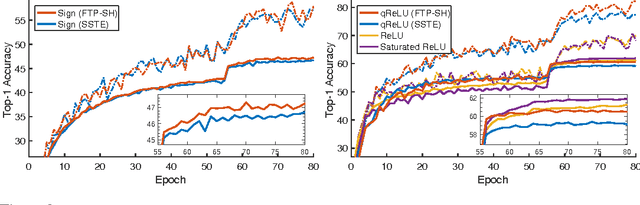
As neural networks grow deeper and wider, learning networks with hard-threshold activations is becoming increasingly important, both for network quantization, which can drastically reduce time and energy requirements, and for creating large integrated systems of deep networks, which may have non-differentiable components and must avoid vanishing and exploding gradients for effective learning. However, since gradient descent is not applicable to hard-threshold functions, it is not clear how to learn networks of them in a principled way. We address this problem by observing that setting targets for hard-threshold hidden units in order to minimize loss is a discrete optimization problem, and can be solved as such. The discrete optimization goal is to find a set of targets such that each unit, including the output, has a linearly separable problem to solve. Given these targets, the network decomposes into individual perceptrons, which can then be learned with standard convex approaches. Based on this, we develop a recursive mini-batch algorithm for learning deep hard-threshold networks that includes the popular but poorly justified straight-through estimator as a special case. Empirically, we show that our algorithm improves classification accuracy in a number of settings, including for AlexNet and ResNet-18 on ImageNet, when compared to the straight-through estimator.
* 14 pages (9 body, 5 pages of references and appendices)
The Sum-Product Theorem: A Foundation for Learning Tractable Models
Nov 11, 2016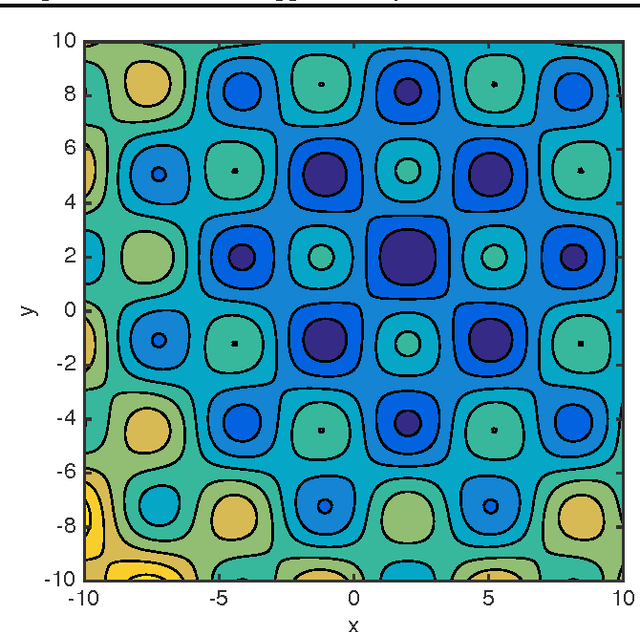
Inference in expressive probabilistic models is generally intractable, which makes them difficult to learn and limits their applicability. Sum-product networks are a class of deep models where, surprisingly, inference remains tractable even when an arbitrary number of hidden layers are present. In this paper, we generalize this result to a much broader set of learning problems: all those where inference consists of summing a function over a semiring. This includes satisfiability, constraint satisfaction, optimization, integration, and others. In any semiring, for summation to be tractable it suffices that the factors of every product have disjoint scopes. This unifies and extends many previous results in the literature. Enforcing this condition at learning time thus ensures that the learned models are tractable. We illustrate the power and generality of this approach by applying it to a new type of structured prediction problem: learning a nonconvex function that can be globally optimized in polynomial time. We show empirically that this greatly outperforms the standard approach of learning without regard to the cost of optimization.
* 15 pages (10 body, 5 pages of appendices)
Recursive Decomposition for Nonconvex Optimization
Nov 08, 2016
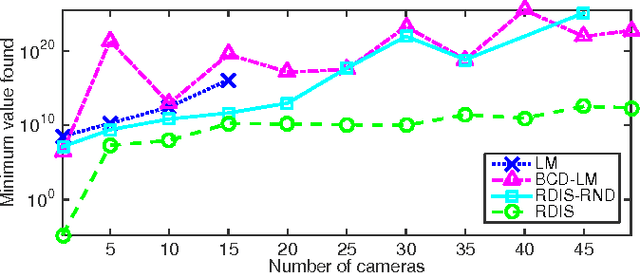

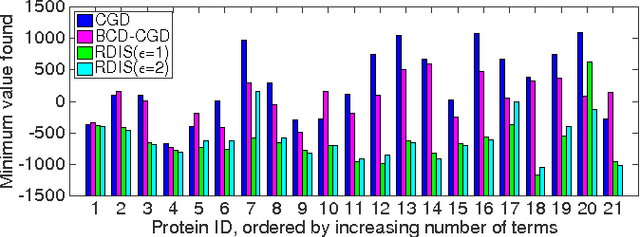
Continuous optimization is an important problem in many areas of AI, including vision, robotics, probabilistic inference, and machine learning. Unfortunately, most real-world optimization problems are nonconvex, causing standard convex techniques to find only local optima, even with extensions like random restarts and simulated annealing. We observe that, in many cases, the local modes of the objective function have combinatorial structure, and thus ideas from combinatorial optimization can be brought to bear. Based on this, we propose a problem-decomposition approach to nonconvex optimization. Similarly to DPLL-style SAT solvers and recursive conditioning in probabilistic inference, our algorithm, RDIS, recursively sets variables so as to simplify and decompose the objective function into approximately independent sub-functions, until the remaining functions are simple enough to be optimized by standard techniques like gradient descent. The variables to set are chosen by graph partitioning, ensuring decomposition whenever possible. We show analytically that RDIS can solve a broad class of nonconvex optimization problems exponentially faster than gradient descent with random restarts. Experimentally, RDIS outperforms standard techniques on problems like structure from motion and protein folding.
* 11 pages, 7 figures, pdflatex