 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation
Nov 18, 2022



We introduce GENIUS: a conditional text generation model using sketches as input, which can fill in the missing contexts for a given sketch (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large-scale textual corpus with a novel reconstruction from sketch objective using an extreme and selective masking strategy, enabling it to generate diverse and high-quality texts given sketches. Comparison with other competitive conditional language models (CLMs) reveals the superiority of GENIUS's text generation quality. We further show that GENIUS can be used as a strong and ready-to-use data augmentation tool for various natural language processing (NLP) tasks. Most existing textual data augmentation methods are either too conservative, by making small changes to the original text, or too aggressive, by creating entirely new samples. With GENIUS, we propose GeniusAug, which first extracts the target-aware sketches from the original training set and then generates new samples based on the sketches. Empirical experiments on 6 text classification datasets show that GeniusAug significantly improves the models' performance in both in-distribution (ID) and out-of-distribution (OOD) settings. We also demonstrate the effectiveness of GeniusAug on named entity recognition (NER) and machine reading comprehension (MRC) tasks. (Code and models are publicly available at https://github.com/microsoft/SCGLab and https://github.com/beyondguo/genius)
Execution-based Evaluation for Data Science Code Generation Models
Nov 17, 2022



Code generation models can benefit data scientists' productivity by automatically generating code from context and text descriptions. An important measure of the modeling progress is whether a model can generate code that can correctly execute to solve the task. However, due to the lack of an evaluation dataset that directly supports execution-based model evaluation, existing work relies on code surface form similarity metrics (e.g., BLEU, CodeBLEU) for model selection, which can be inaccurate. To remedy this, we introduce ExeDS, an evaluation dataset for execution evaluation for data science code generation tasks. ExeDS contains a set of 534 problems from Jupyter Notebooks, each consisting of code context, task description, reference program, and the desired execution output. With ExeDS, we evaluate the execution performance of five state-of-the-art code generation models that have achieved high surface-form evaluation scores. Our experiments show that models with high surface-form scores do not necessarily perform well on execution metrics, and execution-based metrics can better capture model code generation errors. Source code and data can be found at https://github.com/Jun-jie-Huang/ExeDS
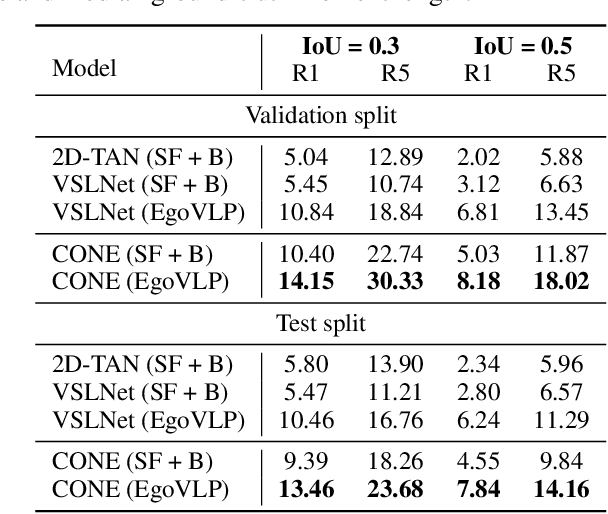
An Efficient COarse-to-fiNE Alignment Framework @ Ego4D Natural Language Queries Challenge 2022
Nov 16, 2022



This technical report describes the CONE approach for Ego4D Natural Language Queries (NLQ) Challenge in ECCV 2022. We leverage our model CONE, an efficient window-centric COarse-to-fiNE alignment framework. Specifically, CONE dynamically slices the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of the contrastive vision-text pre-trained model EgoVLP. On the blind test set, CONE achieves 15.26 and 9.24 for R1@IoU=0.3 and R1@IoU=0.5, respectively.
Disentangling Reasoning Capabilities from Language Models with Compositional Reasoning Transformers
Oct 20, 2022
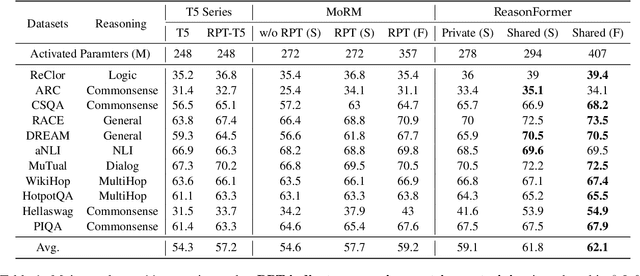
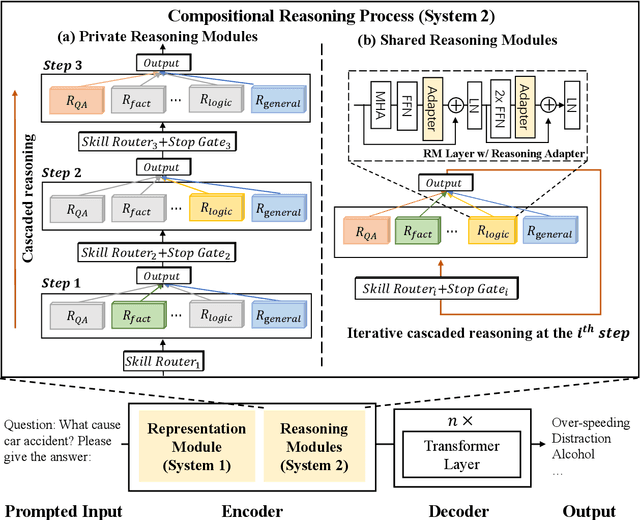
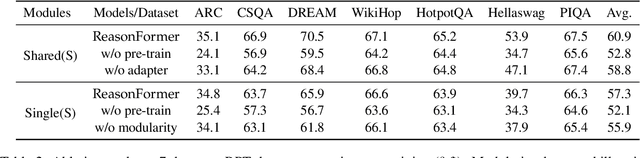
This paper presents ReasonFormer, a unified reasoning framework for mirroring the modular and compositional reasoning process of humans in complex decision making. Inspired by dual-process theory in cognitive science, the representation module (automatic thinking) and reasoning modules (controlled thinking) are disentangled to capture different levels of cognition. Upon the top of the representation module, the pre-trained reasoning modules are modular and expertise in specific and fundamental reasoning skills (e.g., logic, simple QA, etc). To mimic the controlled compositional thinking process, different reasoning modules are dynamically activated and composed in both parallel and cascaded manners to control what reasoning skills are activated and how deep the reasoning process will be reached to solve the current problems. The unified reasoning framework solves multiple tasks with a single model,and is trained and inferred in an end-to-end manner. Evaluated on 11 datasets requiring different reasoning skills and complexity, ReasonFormer demonstrates substantial performance boosts, revealing the compositional reasoning ability. Few-shot experiments exhibit better generalization ability by learning to compose pre-trained skills for new tasks with limited data,and decoupling the representation module and the reasoning modules. Further analysis shows the modularity of reasoning modules as different tasks activate distinct reasoning skills at different reasoning depths.
Sentiment-Aware Word and Sentence Level Pre-training for Sentiment Analysis
Oct 19, 2022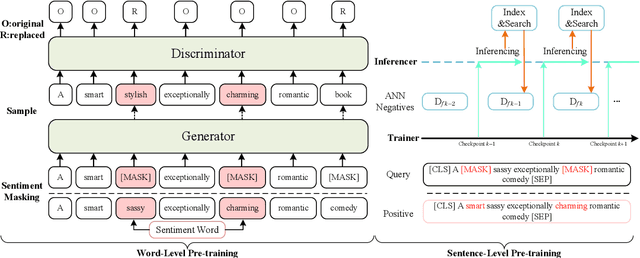
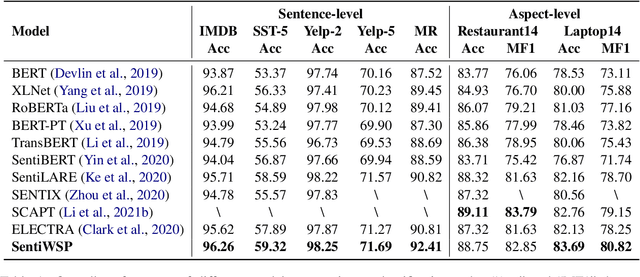
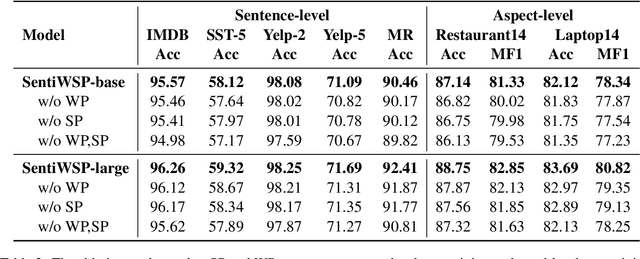
Most existing pre-trained language representation models (PLMs) are sub-optimal in sentiment analysis tasks, as they capture the sentiment information from word-level while under-considering sentence-level information. In this paper, we propose SentiWSP, a novel Sentiment-aware pre-trained language model with combined Word-level and Sentence-level Pre-training tasks. The word level pre-training task detects replaced sentiment words, via a generator-discriminator framework, to enhance the PLM's knowledge about sentiment words. The sentence level pre-training task further strengthens the discriminator via a contrastive learning framework, with similar sentences as negative samples, to encode sentiments in a sentence. Extensive experimental results show that SentiWSP achieves new state-of-the-art performance on various sentence-level and aspect-level sentiment classification benchmarks. We have made our code and model publicly available at https://github.com/XMUDM/SentiWSP.
Soft-Labeled Contrastive Pre-training for Function-level Code Representation
Oct 18, 2022
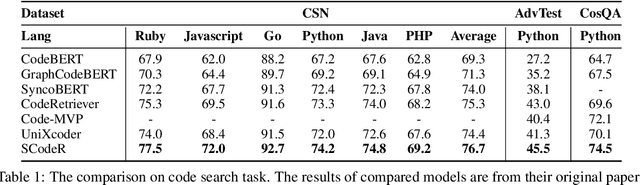
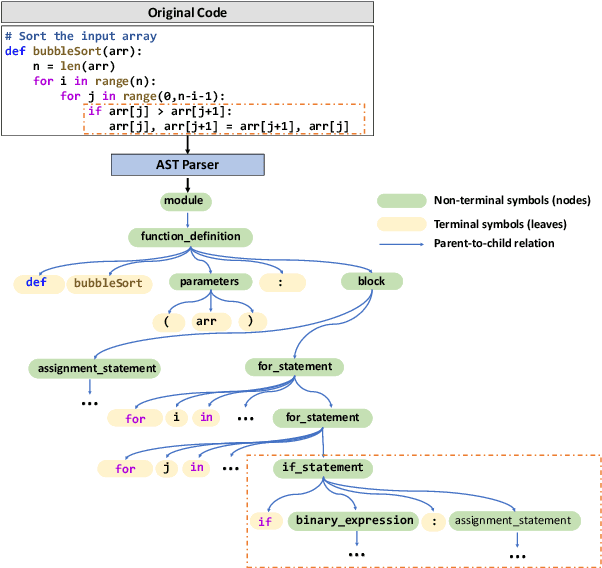
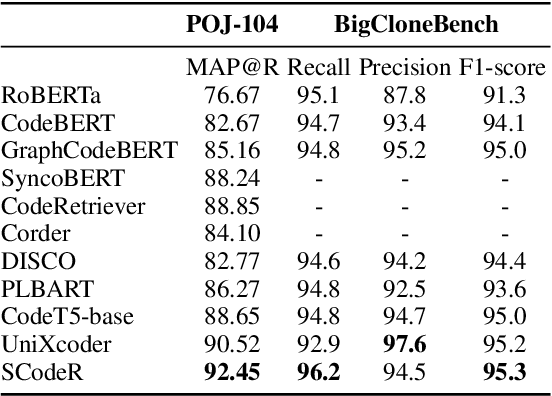
Code contrastive pre-training has recently achieved significant progress on code-related tasks. In this paper, we present \textbf{SCodeR}, a \textbf{S}oft-labeled contrastive pre-training framework with two positive sample construction methods to learn functional-level \textbf{Code} \textbf{R}epresentation. Considering the relevance between codes in a large-scale code corpus, the soft-labeled contrastive pre-training can obtain fine-grained soft-labels through an iterative adversarial manner and use them to learn better code representation. The positive sample construction is another key for contrastive pre-training. Previous works use transformation-based methods like variable renaming to generate semantically equal positive codes. However, they usually result in the generated code with a highly similar surface form, and thus mislead the model to focus on superficial code structure instead of code semantics. To encourage SCodeR to capture semantic information from the code, we utilize code comments and abstract syntax sub-trees of the code to build positive samples. We conduct experiments on four code-related tasks over seven datasets. Extensive experimental results show that SCodeR achieves new state-of-the-art performance on all of them, which illustrates the effectiveness of the proposed pre-training method.
Mixed-modality Representation Learning and Pre-training for Joint Table-and-Text Retrieval in OpenQA
Oct 11, 2022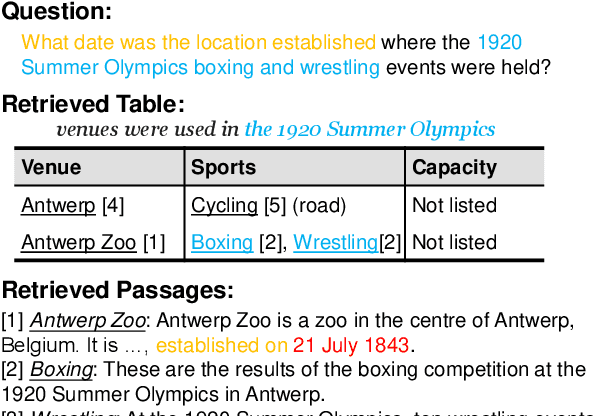

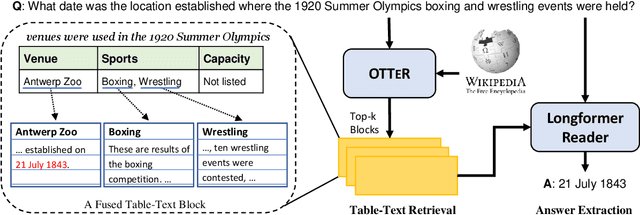
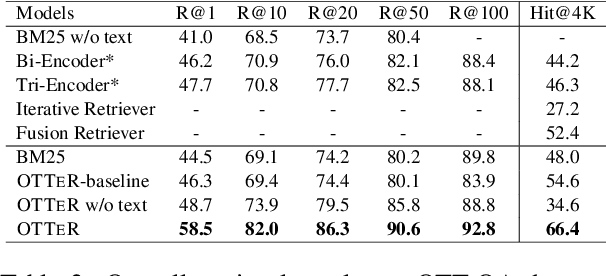
Retrieving evidences from tabular and textual resources is essential for open-domain question answering (OpenQA), which provides more comprehensive information. However, training an effective dense table-text retriever is difficult due to the challenges of table-text discrepancy and data sparsity problem. To address the above challenges, we introduce an optimized OpenQA Table-Text Retriever (OTTeR) to jointly retrieve tabular and textual evidences. Firstly, we propose to enhance mixed-modality representation learning via two mechanisms: modality-enhanced representation and mixed-modality negative sampling strategy. Secondly, to alleviate data sparsity problem and enhance the general retrieval ability, we conduct retrieval-centric mixed-modality synthetic pre-training. Experimental results demonstrate that OTTeR substantially improves the performance of table-and-text retrieval on the OTT-QA dataset. Comprehensive analyses examine the effectiveness of all the proposed mechanisms. Besides, equipped with OTTeR, our OpenQA system achieves the state-of-the-art result on the downstream QA task, with 10.1\% absolute improvement in terms of the exact match over the previous best system. \footnote{All the code and data are available at \url{https://github.com/Jun-jie-Huang/OTTeR}.}
HORIZON: A High-Resolution Panorama Synthesis Framework
Oct 10, 2022
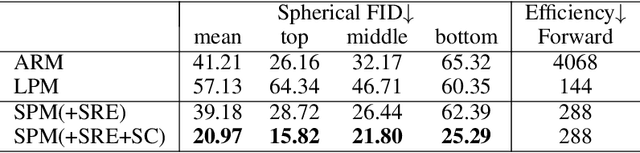
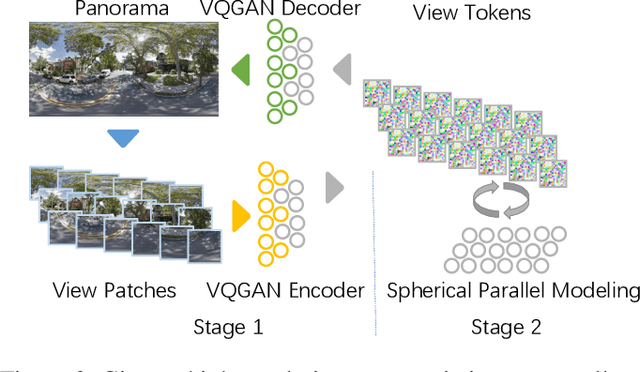

Panorama synthesis aims to generate a visual scene with all 360-degree views and enables an immersive virtual world. If the panorama synthesis process can be semantically controlled, we can then build an interactive virtual world and form an unprecedented human-computer interaction experience. Existing panoramic synthesis methods mainly focus on dealing with the inherent challenges brought by panoramas' spherical structure such as the projection distortion and the in-continuity problem when stitching edges, but is hard to effectively control semantics. The recent success of visual synthesis like DALL.E generates promising 2D flat images with semantic control, however, it is hard to directly be applied to panorama synthesis which inevitably generates distorted content. Besides, both of the above methods can not effectively synthesize high-resolution panoramas either because of quality or inference speed. In this work, we propose a new generation framework for high-resolution panorama images. The contributions include 1) alleviating the spherical distortion and edge in-continuity problem through spherical modeling, 2) supporting semantic control through both image and text hints, and 3) effectively generating high-resolution panoramas through parallel decoding. Our experimental results on a large-scale high-resolution Street View dataset validated the superiority of our approach quantitatively and qualitatively.
PROD: Progressive Distillation for Dense Retrieval
Sep 27, 2022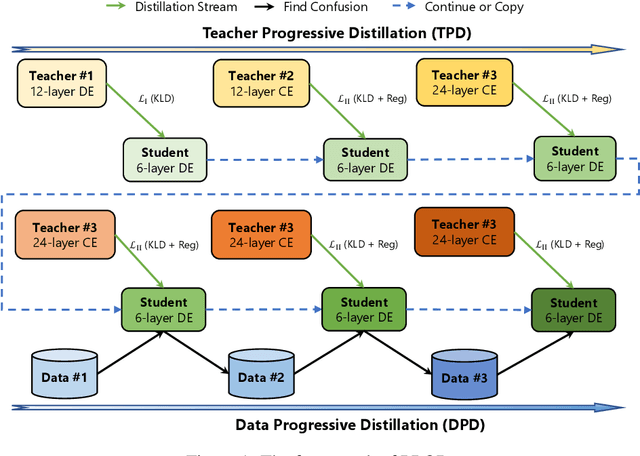
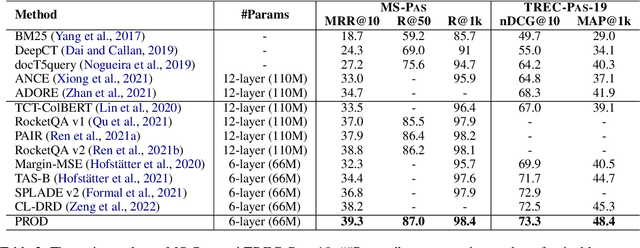
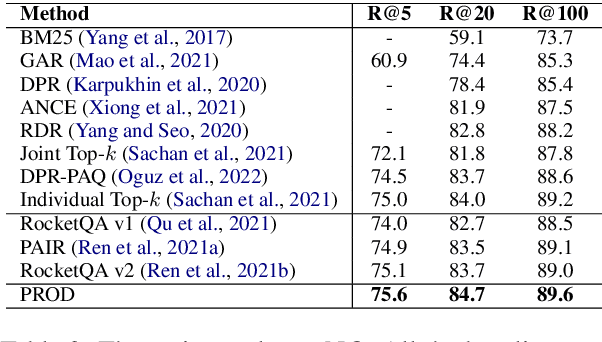
Knowledge distillation is an effective way to transfer knowledge from a strong teacher to an efficient student model. Ideally, we expect the better the teacher is, the better the student. However, this expectation does not always come true. It is common that a better teacher model results in a bad student via distillation due to the nonnegligible gap between teacher and student. To bridge the gap, we propose PROD, a PROgressive Distillation method, for dense retrieval. PROD consists of a teacher progressive distillation and a data progressive distillation to gradually improve the student. We conduct extensive experiments on five widely-used benchmarks, MS MARCO Passage, TREC Passage 19, TREC Document 19, MS MARCO Document and Natural Questions, where PROD achieves the state-of-the-art within the distillation methods for dense retrieval. The code and models will be released.
CONE: An Efficient COarse-to-fiNE Alignment Framework for Long Video Temporal Grounding
Sep 22, 2022

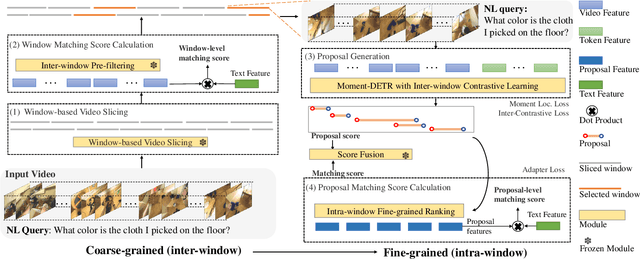
Video temporal grounding (VTG) targets to localize temporal moments in an untrimmed video according to a natural language (NL) description. Since real-world applications provide a never-ending video stream, it raises demands for temporal grounding for long-form videos, which leads to two major challenges: (1) the long video length makes it difficult to process the entire video without decreasing sample rate and leads to high computational burden; (2) the accurate multi-modal alignment is more challenging as the number of moment candidates increases. To address these challenges, we propose CONE, an efficient window-centric COarse-to-fiNE alignment framework, which flexibly handles long-form video inputs with higher inference speed, and enhances the temporal grounding via our novel coarse-to-fine multi-modal alignment framework. Specifically, we dynamically slice the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of a contrastive vision-text pre-trained model. Extensive experiments on two large-scale VTG benchmarks for long videos consistently show a substantial performance gain (from 3.13% to 6.87% on MAD and from 10.46% to 13.46% on Ego4d-NLQ) and CONE achieves the SOTA results on both datasets. Analysis reveals the effectiveness of components and higher efficiency in long video grounding as our system improves the inference speed by 2x on Ego4d-NLQ and 15x on MAD while keeping the SOTA performance of CONE.