 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Outlook on the Opportunities and Challenges of Multi-Agent AI Systems
May 23, 2025Multi-agent AI systems (MAS) offer a promising framework for distributed intelligence, enabling collaborative reasoning, planning, and decision-making across autonomous agents. This paper provides a systematic outlook on the current opportunities and challenges of MAS, drawing insights from recent advances in large language models (LLMs), federated optimization, and human-AI interaction. We formalize key concepts including agent topology, coordination protocols, and shared objectives, and identify major risks such as dependency, misalignment, and vulnerabilities arising from training data overlap. Through a biologically inspired simulation and comprehensive theoretical framing, we highlight critical pathways for developing robust, scalable, and secure MAS in real-world settings.
Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment
May 17, 2025This paper investigates approaches to enhance the reasoning capabilities of Large Language Model (LLM) agents using Reinforcement Learning (RL). Specifically, we focus on multi-turn tool-use scenarios, which can be naturally modeled as Markov Decision Processes (MDPs). While existing approaches often train multi-turn LLM agents with trajectory-level advantage estimation in bandit settings, they struggle with turn-level credit assignment across multiple decision steps, limiting their performance on multi-turn reasoning tasks. To address this, we introduce a fine-grained turn-level advantage estimation strategy to enable more precise credit assignment in multi-turn agent interactions. The strategy is general and can be incorporated into various RL algorithms such as Group Relative Preference Optimization (GRPO). Our experimental evaluation on multi-turn reasoning and search-based tool-use tasks with GRPO implementations highlights the effectiveness of the MDP framework and the turn-level credit assignment in advancing the multi-turn reasoning capabilities of LLM agents in complex decision-making settings. Our method achieves 100% success in tool execution and 50% accuracy in exact answer matching, significantly outperforming baselines, which fail to invoke tools and achieve only 20-30% exact match accuracy.
InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
May 16, 2025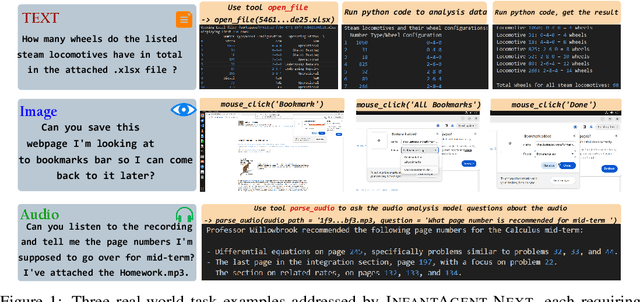

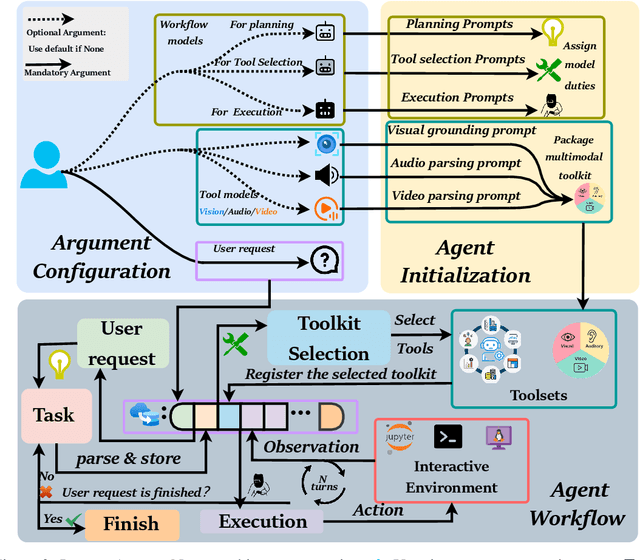
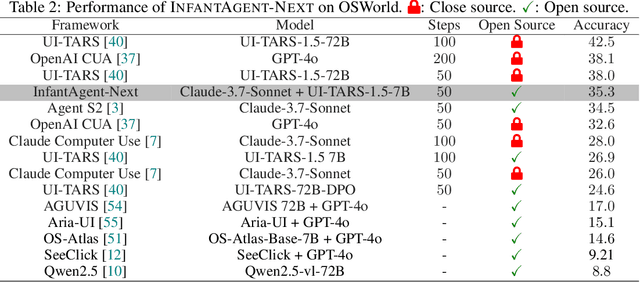
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27\%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
Optimization Problem Solving Can Transition to Evolutionary Agentic Workflows
May 07, 2025This position paper argues that optimization problem solving can transition from expert-dependent to evolutionary agentic workflows. Traditional optimization practices rely on human specialists for problem formulation, algorithm selection, and hyperparameter tuning, creating bottlenecks that impede industrial adoption of cutting-edge methods. We contend that an evolutionary agentic workflow, powered by foundation models and evolutionary search, can autonomously navigate the optimization space, comprising problem, formulation, algorithm, and hyperparameter spaces. Through case studies in cloud resource scheduling and ADMM parameter adaptation, we demonstrate how this approach can bridge the gap between academic innovation and industrial implementation. Our position challenges the status quo of human-centric optimization workflows and advocates for a more scalable, adaptive approach to solving real-world optimization problems.
Learning Explainable Dense Reward Shapes via Bayesian Optimization
Apr 22, 2025Current reinforcement learning from human feedback (RLHF) pipelines for large language model (LLM) alignment typically assign scalar rewards to sequences, using the final token as a surrogate indicator for the quality of the entire sequence. However, this leads to sparse feedback and suboptimal token-level credit assignment. In this work, we frame reward shaping as an optimization problem focused on token-level credit assignment. We propose a reward-shaping function leveraging explainability methods such as SHAP and LIME to estimate per-token rewards from the reward model. To learn parameters of this shaping function, we employ a bilevel optimization framework that integrates Bayesian Optimization and policy training to handle noise from the token reward estimates. Our experiments show that achieving a better balance of token-level reward attribution leads to performance improvements over baselines on downstream tasks and finds an optimal policy faster during training. Furthermore, we show theoretically that explainability methods that are feature additive attribution functions maintain the optimal policy as the original reward.
From Demonstrations to Rewards: Alignment Without Explicit Human Preferences
Mar 15, 2025One of the challenges of aligning large models with human preferences lies in both the data requirements and the technical complexities of current approaches. Predominant methods, such as RLHF, involve multiple steps, each demanding distinct types of data, including demonstration data and preference data. In RLHF, human preferences are typically modeled through a reward model, which serves as a proxy to guide policy learning during the reinforcement learning stage, ultimately producing a policy aligned with human preferences. However, in this paper, we propose a fresh perspective on learning alignment based on inverse reinforcement learning principles, where the optimal policy is still derived from reward maximization. However, instead of relying on preference data, we directly learn the reward model from demonstration data. This new formulation offers the flexibility to be applied even when only demonstration data is available, a capability that current RLHF methods lack, and it also shows that demonstration data offers more utility than what conventional wisdom suggests. Our extensive evaluation, based on public reward benchmark, HuggingFace Open LLM Leaderboard and MT-Bench, demonstrates that our approach compares favorably to state-of-the-art methods that rely solely on demonstration data.
Effectively Steer LLM To Follow Preference via Building Confident Directions
Mar 04, 2025Having an LLM that aligns with human preferences is essential for accommodating individual needs, such as maintaining writing style or generating specific topics of interest. The majority of current alignment methods rely on fine-tuning or prompting, which can be either costly or difficult to control. Model steering algorithms, which modify the model output by constructing specific steering directions, are typically easy to implement and optimization-free. However, their capabilities are typically limited to steering the model into one of the two directions (i.e., bidirectional steering), and there has been no theoretical understanding to guarantee their performance. In this work, we propose a theoretical framework to understand and quantify the model steering methods. Inspired by the framework, we propose a confident direction steering method (CONFST) that steers LLMs via modifying their activations at inference time. More specifically, CONFST builds a confident direction that is closely aligned with users' preferences, and this direction is then added to the activations of the LLMs to effectively steer the model output. Our approach offers three key advantages over popular bidirectional model steering methods: 1) It is more powerful, since multiple (i.e. more than two) users' preferences can be aligned simultaneously; 2) It is simple to implement, since there is no need to determine which layer to add the steering vector to; 3) No explicit user instruction is required. We validate our method on GPT-2 XL (1.5B), Mistral (7B) and Gemma-it (9B) models for tasks that require shifting the output of LLMs across various topics and styles, achieving superior performance over competing methods.
LUME: LLM Unlearning with Multitask Evaluations
Feb 20, 2025



Unlearning aims to remove copyrighted, sensitive, or private content from large language models (LLMs) without a full retraining. In this work, we develop a multi-task unlearning benchmark (LUME) which features three tasks: (1) unlearn synthetically generated creative short novels, (2) unlearn synthetic biographies with sensitive information, and (3) unlearn a collection of public biographies. We further release two fine-tuned LLMs of 1B and 7B parameter sizes as the target models. We conduct detailed evaluations of several recently proposed unlearning algorithms and present results on carefully crafted metrics to understand their behavior and limitations.
Do LLMs Recognize Your Preferences? Evaluating Personalized Preference Following in LLMs
Feb 13, 2025



Large Language Models (LLMs) are increasingly used as chatbots, yet their ability to personalize responses to user preferences remains limited. We introduce PrefEval, a benchmark for evaluating LLMs' ability to infer, memorize and adhere to user preferences in a long-context conversational setting. PrefEval comprises 3,000 manually curated user preference and query pairs spanning 20 topics. PrefEval contains user personalization or preference information in both explicit and implicit forms, and evaluates LLM performance using a generation and a classification task. With PrefEval, we evaluated the aforementioned preference following capabilities of 10 open-source and proprietary LLMs in multi-session conversations with varying context lengths up to 100k tokens. We benchmark with various prompting, iterative feedback, and retrieval-augmented generation methods. Our benchmarking effort reveals that state-of-the-art LLMs face significant challenges in proactively following users' preferences during conversations. In particular, in zero-shot settings, preference following accuracy falls below 10% at merely 10 turns (~3k tokens) across most evaluated models. Even with advanced prompting and retrieval methods, preference following still deteriorates in long-context conversations. Furthermore, we show that fine-tuning on PrefEval significantly improves performance. We believe PrefEval serves as a valuable resource for measuring, understanding, and enhancing LLMs' preference following abilities, paving the way for personalized conversational agents. Our code and dataset are available at https://prefeval.github.io/.
RoSTE: An Efficient Quantization-Aware Supervised Fine-Tuning Approach for Large Language Models
Feb 13, 2025Supervised fine-tuning is a standard method for adapting pre-trained large language models (LLMs) to downstream tasks. Quantization has been recently studied as a post-training technique for efficient LLM deployment. To obtain quantized fine-tuned LLMs, conventional pipelines would first fine-tune the pre-trained models, followed by post-training quantization. This often yields suboptimal performance as it fails to leverage the synergy between fine-tuning and quantization. To effectively realize low-bit quantization of weights, activations, and KV caches in LLMs, we propose an algorithm named Rotated Straight-Through-Estimator (RoSTE), which combines quantization-aware supervised fine-tuning (QA-SFT) with an adaptive rotation strategy that identifies an effective rotation configuration to reduce activation outliers. We provide theoretical insights on RoSTE by analyzing its prediction error when applied to an overparameterized least square quantized training problem. Our findings reveal that the prediction error is directly proportional to the quantization error of the converged weights, which can be effectively managed through an optimized rotation configuration. Experiments on Pythia and Llama models of different sizes demonstrate the effectiveness of RoSTE. Compared to existing post-SFT quantization baselines, our method consistently achieves superior performances across various tasks and different LLM architectures.