 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
Mar 19, 2026Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) and artificial intelligence (AI) agents have significantly automated data science workflow. However, it remains unclear to what extent AI agents can match the performance of human experts on domain-specific data science tasks, and in which aspects human expertise continues to provide advantages. We introduce AgentDS, a benchmark and competition designed to evaluate both AI agents and human-AI collaboration performance in domain-specific data science. AgentDS consists of 17 challenges across six industries: commerce, food production, healthcare, insurance, manufacturing, and retail banking. We conducted an open competition involving 29 teams and 80 participants, enabling systematic comparison between human-AI collaborative approaches and AI-only baselines. Our results show that current AI agents struggle with domain-specific reasoning. AI-only baselines perform near or below the median of competition participants, while the strongest solutions arise from human-AI collaboration. These findings challenge the narrative of complete automation by AI and underscore the enduring importance of human expertise in data science, while illuminating directions for the next generation of AI. Visit the AgentDS website here: https://agentds.org/ and open source datasets here: https://huggingface.co/datasets/lainmn/AgentDS .
Differentially Private Truncation of Unbounded Data via Public Second Moments
Feb 25, 2026Data privacy is important in the AI era, and differential privacy (DP) is one of the golden solutions. However, DP is typically applicable only if data have a bounded underlying distribution. We address this limitation by leveraging second-moment information from a small amount of public data. We propose Public-moment-guided Truncation (PMT), which transforms private data using the public second-moment matrix and applies a principled truncation whose radius depends only on non-private quantities: data dimension and sample size. This transformation yields a well-conditioned second-moment matrix, enabling its inversion with a significantly strengthened ability to resist the DP noise. Furthermore, we demonstrate the applicability of PMT by using penalized and generalized linear regressions. Specifically, we design new loss functions and algorithms, ensuring that solutions in the transformed space can be mapped back to the original domain. We have established improvements in the models' DP estimation through theoretical error bounds, robustness guarantees, and convergence results, attributing the gains to the conditioning effect of PMT. Experiments on synthetic and real datasets confirm that PMT substantially improves the accuracy and stability of DP models.
Recommending Composite Items Using Multi-Level Preference Information: A Joint Interaction Modeling Approach
Jan 26, 2026With the advancement of machine learning and artificial intelligence technologies, recommender systems have been increasingly used across a vast variety of platforms to efficiently and effectively match users with items. As application contexts become more diverse and complex, there is a growing need for more sophisticated recommendation techniques. One example is the composite item (for example, fashion outfit) recommendation where multiple levels of user preference information might be available and relevant. In this study, we propose JIMA, a joint interaction modeling approach that uses a single model to take advantage of all data from different levels of granularity and incorporate interactions to learn the complex relationships among lower-order (atomic item) and higher-order (composite item) user preferences as well as domain expertise (e.g., on the stylistic fit). We comprehensively evaluate the proposed method and compare it with advanced baselines through multiple simulation studies as well as with real data in both offline and online settings. The results consistently demonstrate the superior performance of the proposed approach.
Can Agentic AI Match the Performance of Human Data Scientists?
Dec 24, 2025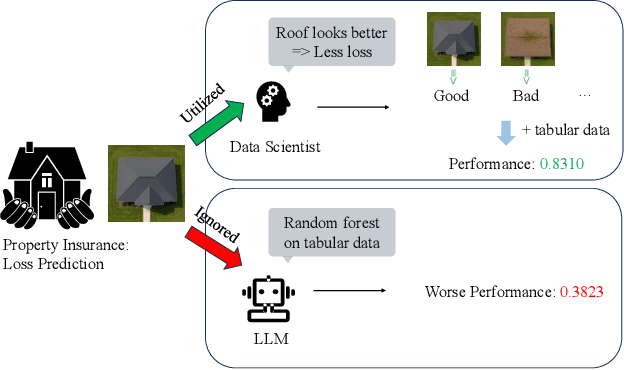

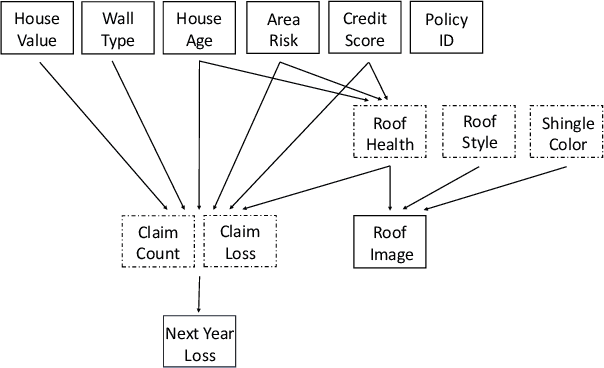

Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) have significantly automated data science workflows, but a fundamental question persists: Can these agentic AI systems truly match the performance of human data scientists who routinely leverage domain-specific knowledge? We explore this question by designing a prediction task where a crucial latent variable is hidden in relevant image data instead of tabular features. As a result, agentic AI that generates generic codes for modeling tabular data cannot perform well, while human experts could identify the important hidden variable using domain knowledge. We demonstrate this idea with a synthetic dataset for property insurance. Our experiments show that agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights. This highlights a key limitation of the current agentic AI for data science and underscores the need for future research to develop agentic AI systems that can better recognize and incorporate domain knowledge.
An Outlook on the Opportunities and Challenges of Multi-Agent AI Systems
May 23, 2025Multi-agent AI systems (MAS) offer a promising framework for distributed intelligence, enabling collaborative reasoning, planning, and decision-making across autonomous agents. This paper provides a systematic outlook on the current opportunities and challenges of MAS, drawing insights from recent advances in large language models (LLMs), federated optimization, and human-AI interaction. We formalize key concepts including agent topology, coordination protocols, and shared objectives, and identify major risks such as dependency, misalignment, and vulnerabilities arising from training data overlap. Through a biologically inspired simulation and comprehensive theoretical framing, we highlight critical pathways for developing robust, scalable, and secure MAS in real-world settings.
Demystifying Poisoning Backdoor Attacks from a Statistical Perspective
Oct 18, 2023



The growing dependence on machine learning in real-world applications emphasizes the importance of understanding and ensuring its safety. Backdoor attacks pose a significant security risk due to their stealthy nature and potentially serious consequences. Such attacks involve embedding triggers within a learning model with the intention of causing malicious behavior when an active trigger is present while maintaining regular functionality without it. This paper evaluates the effectiveness of any backdoor attack incorporating a constant trigger, by establishing tight lower and upper boundaries for the performance of the compromised model on both clean and backdoor test data. The developed theory answers a series of fundamental but previously underexplored problems, including (1) what are the determining factors for a backdoor attack's success, (2) what is the direction of the most effective backdoor attack, and (3) when will a human-imperceptible trigger succeed. Our derived understanding applies to both discriminative and generative models. We also demonstrate the theory by conducting experiments using benchmark datasets and state-of-the-art backdoor attack scenarios.
Welfare and Fairness Dynamics in Federated Learning: A Client Selection Perspective
Feb 17, 2023



Federated learning (FL) is a privacy-preserving learning technique that enables distributed computing devices to train shared learning models across data silos collaboratively. Existing FL works mostly focus on designing advanced FL algorithms to improve the model performance. However, the economic considerations of the clients, such as fairness and incentive, are yet to be fully explored. Without such considerations, self-motivated clients may lose interest and leave the federation. To address this problem, we designed a novel incentive mechanism that involves a client selection process to remove low-quality clients and a money transfer process to ensure a fair reward distribution. Our experimental results strongly demonstrate that the proposed incentive mechanism can effectively improve the duration and fairness of the federation.
Distribution-Invariant Differential Privacy
Nov 08, 2021
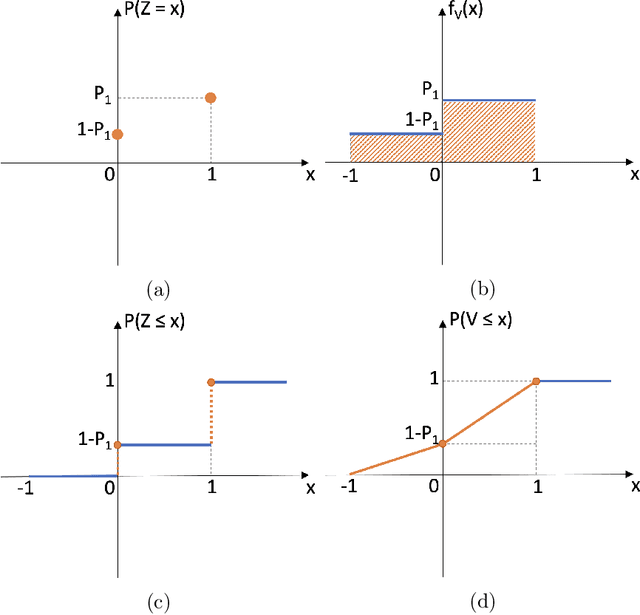
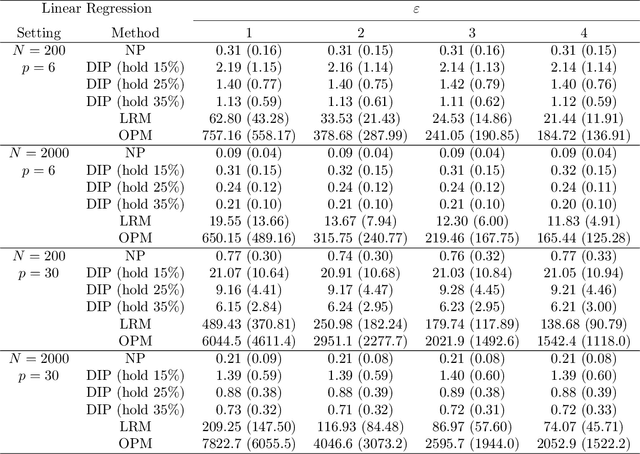
Differential privacy is becoming one gold standard for protecting the privacy of publicly shared data. It has been widely used in social science, data science, public health, information technology, and the U.S. decennial census. Nevertheless, to guarantee differential privacy, existing methods may unavoidably alter the conclusion of original data analysis, as privatization often changes the sample distribution. This phenomenon is known as the trade-off between privacy protection and statistical accuracy. In this work, we break this trade-off by developing a distribution-invariant privatization (DIP) method to reconcile both high statistical accuracy and strict differential privacy. As a result, any downstream statistical or machine learning task yields essentially the same conclusion as if one used the original data. Numerically, under the same strictness of privacy protection, DIP achieves superior statistical accuracy in two simulations and on three real-world benchmarks.
Improving Sales Forecasting Accuracy: A Tensor Factorization Approach with Demand Awareness
Nov 06, 2020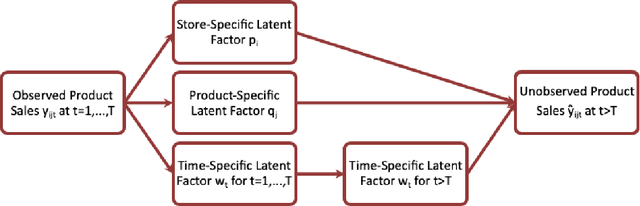
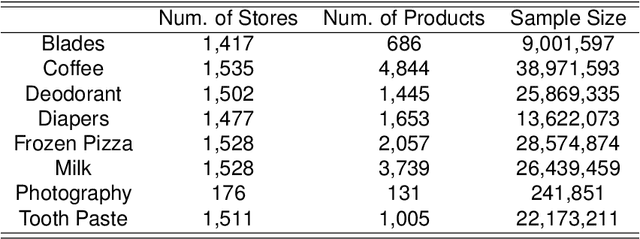
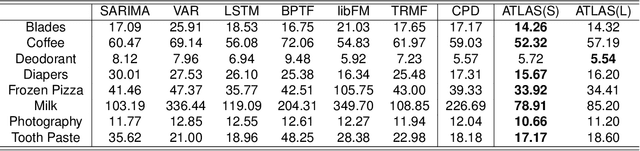
Due to accessible big data collections from consumers, products, and stores, advanced sales forecasting capabilities have drawn great attention from many companies especially in the retail business because of its importance in decision making. Improvement of the forecasting accuracy, even by a small percentage, may have a substantial impact on companies' production and financial planning, marketing strategies, inventory controls, supply chain management, and eventually stock prices. Specifically, our research goal is to forecast the sales of each product in each store in the near future. Motivated by tensor factorization methodologies for personalized context-aware recommender systems, we propose a novel approach called the Advanced Temporal Latent-factor Approach to Sales forecasting (ATLAS), which achieves accurate and individualized prediction for sales by building a single tensor-factorization model across multiple stores and products. Our contribution is a combination of: tensor framework (to leverage information across stores and products), a new regularization function (to incorporate demand dynamics), and extrapolation of tensor into future time periods using state-of-the-art statistical (seasonal auto-regressive integrated moving-average models) and machine-learning (recurrent neural networks) models. The advantages of ATLAS are demonstrated on eight product category datasets collected by the Information Resource, Inc., where a total of 165 million weekly sales transactions from more than 1,500 grocery stores over 15,560 products are analyzed.
Individualized Multilayer Tensor Learning with An Application in Imaging Analysis
Mar 21, 2019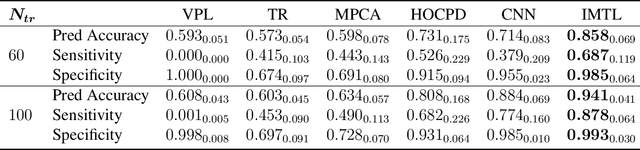
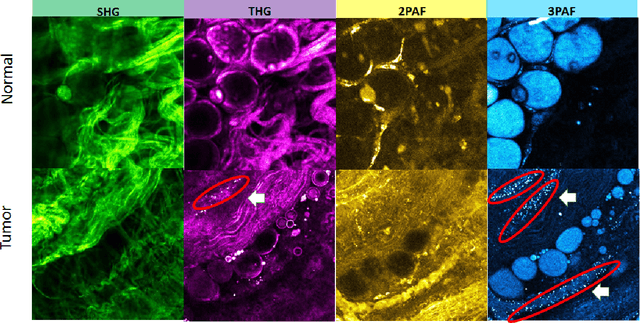

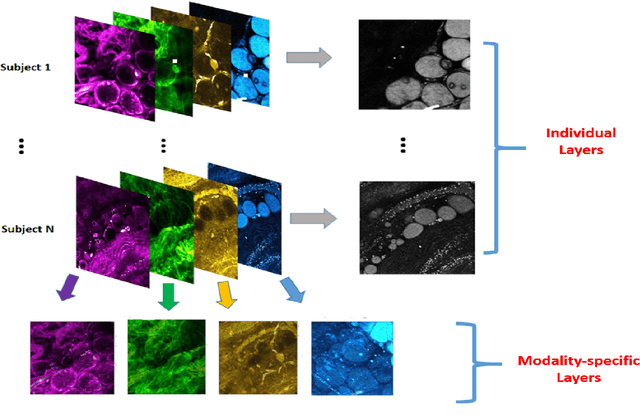
This work is motivated by multimodality breast cancer imaging data, which is quite challenging in that the signals of discrete tumor-associated microvesicles (TMVs) are randomly distributed with heterogeneous patterns. This imposes a significant challenge for conventional imaging regression and dimension reduction models assuming a homogeneous feature structure. We develop an innovative multilayer tensor learning method to incorporate heterogeneity to a higher-order tensor decomposition and predict disease status effectively through utilizing subject-wise imaging features and multimodality information. Specifically, we construct a multilayer decomposition which leverages an individualized imaging layer in addition to a modality-specific tensor structure. One major advantage of our approach is that we are able to efficiently capture the heterogeneous spatial features of signals that are not characterized by a population structure as well as integrating multimodality information simultaneously. To achieve scalable computing, we develop a new bi-level block improvement algorithm. In theory, we investigate both the algorithm convergence property, tensor signal recovery error bound and asymptotic consistency for prediction model estimation. We also apply the proposed method for simulated and human breast cancer imaging data. Numerical results demonstrate that the proposed method outperforms other existing competing methods.