 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Parameter and Memory Efficient Pretraining for LLM: Recent Algorithmic Advances and Benchmarking
May 28, 2025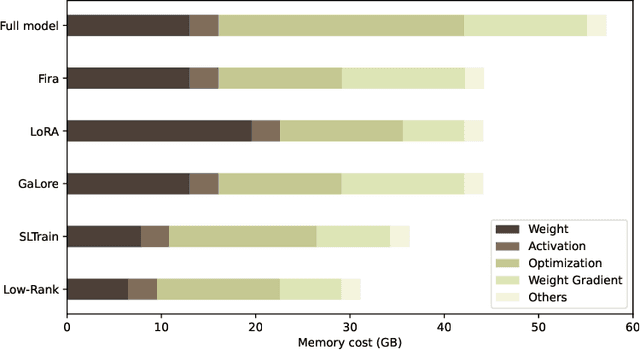



Fueled by their remarkable ability to tackle diverse tasks across multiple domains, large language models (LLMs) have grown at an unprecedented rate, with some recent models containing trillions of parameters. This growth is accompanied by substantial computational challenges, particularly regarding the memory and compute resources required for training and fine-tuning. Numerous approaches have been explored to address these issues, such as LoRA. While these methods are effective for fine-tuning, their application to pre-training is significantly more challenging due to the need to learn vast datasets. Motivated by this issue, we aim to address the following questions: Can parameter- or memory-efficient methods enhance pre-training efficiency while achieving performance comparable to full-model training? How can the performance gap be narrowed? To this end, the contributions of this work are the following. (1) We begin by conducting a comprehensive survey that summarizes state-of-the-art methods for efficient pre-training. (2) We perform a benchmark evaluation of several representative memory efficient pre-training approaches to comprehensively evaluate their performance across model sizes. We observe that with a proper choice of optimizer and hyperparameters, full-rank training delivers the best performance, as expected. We also notice that incorporating high-rank updates in low-rank approaches is the key to improving their performance. (3) Finally, we propose two practical techniques, namely weight refactorization and momentum reset, to enhance the performance of efficient pre-training methods. We observe that applying these techniques to the low-rank method (on a 1B model) can achieve a lower perplexity than popular memory efficient algorithms such as GaLore and Fira, while simultaneously using about 25% less memory.
Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment
May 17, 2025



This paper investigates approaches to enhance the reasoning capabilities of Large Language Model (LLM) agents using Reinforcement Learning (RL). Specifically, we focus on multi-turn tool-use scenarios, which can be naturally modeled as Markov Decision Processes (MDPs). While existing approaches often train multi-turn LLM agents with trajectory-level advantage estimation in bandit settings, they struggle with turn-level credit assignment across multiple decision steps, limiting their performance on multi-turn reasoning tasks. To address this, we introduce a fine-grained turn-level advantage estimation strategy to enable more precise credit assignment in multi-turn agent interactions. The strategy is general and can be incorporated into various RL algorithms such as Group Relative Preference Optimization (GRPO). Our experimental evaluation on multi-turn reasoning and search-based tool-use tasks with GRPO implementations highlights the effectiveness of the MDP framework and the turn-level credit assignment in advancing the multi-turn reasoning capabilities of LLM agents in complex decision-making settings. Our method achieves 100% success in tool execution and 50% accuracy in exact answer matching, significantly outperforming baselines, which fail to invoke tools and achieve only 20-30% exact match accuracy.
RoSTE: An Efficient Quantization-Aware Supervised Fine-Tuning Approach for Large Language Models
Feb 13, 2025Supervised fine-tuning is a standard method for adapting pre-trained large language models (LLMs) to downstream tasks. Quantization has been recently studied as a post-training technique for efficient LLM deployment. To obtain quantized fine-tuned LLMs, conventional pipelines would first fine-tune the pre-trained models, followed by post-training quantization. This often yields suboptimal performance as it fails to leverage the synergy between fine-tuning and quantization. To effectively realize low-bit quantization of weights, activations, and KV caches in LLMs, we propose an algorithm named Rotated Straight-Through-Estimator (RoSTE), which combines quantization-aware supervised fine-tuning (QA-SFT) with an adaptive rotation strategy that identifies an effective rotation configuration to reduce activation outliers. We provide theoretical insights on RoSTE by analyzing its prediction error when applied to an overparameterized least square quantized training problem. Our findings reveal that the prediction error is directly proportional to the quantization error of the converged weights, which can be effectively managed through an optimized rotation configuration. Experiments on Pythia and Llama models of different sizes demonstrate the effectiveness of RoSTE. Compared to existing post-SFT quantization baselines, our method consistently achieves superior performances across various tasks and different LLM architectures.