 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Amazing Agent Race: Strong Tool Users, Weak Navigators
Apr 11, 2026Existing tool-use benchmarks for LLM agents are overwhelmingly linear: our analysis of six benchmarks shows 55 to 100% of instances are simple chains of 2 to 5 steps. We introduce The Amazing Agent Race (AAR), a benchmark featuring directed acyclic graph (DAG) puzzles (or "legs") with fork-merge tool chains. We release 1,400 instances across two variants: sequential (800 legs) and compositional (600 DAG legs). Agents must navigate Wikipedia, execute multi-step tool chains, and aggregate results into a verifiable answer. Legs are procedurally generated from Wikipedia seeds across four difficulty levels with live-API validation. Three complementary metrics (finish-line accuracy, pit-stop visit rate, and roadblock completion rate) separately diagnose navigation, tool-use, and arithmetic failures. Evaluating three agent frameworks on 1,400 legs, the best achieves only 37.2% accuracy. Navigation errors dominate (27 to 52% of trials) while tool-use errors remain below 17%, and agent architecture matters as much as model scale (Claude Code matches Codex CLI at 37% with 6x fewer tokens). The compositional structure of AAR reveals that agents fail not at calling tools but at navigating to the right pages, a blind spot invisible to linear benchmarks. The project page can be accessed at: https://minnesotanlp.github.io/the-amazing-agent-race
Reasoning Beyond Literal: Cross-style Multimodal Reasoning for Figurative Language Understanding
Jan 23, 2026Vision-language models (VLMs) have demonstrated strong reasoning abilities in literal multimodal tasks such as visual mathematics and science question answering. However, figurative language, such as sarcasm, humor, and metaphor, remains a significant challenge, as it conveys intent and emotion through subtle incongruities between expressed and intended meanings. In multimodal settings, accompanying images can amplify or invert textual meaning, demanding models that reason across modalities and account for subjectivity. We propose a three-step framework for developing efficient multimodal reasoning models that can (i) interpret multimodal figurative language, (ii) provide transparent reasoning traces, and (iii) generalize across multiple figurative styles. Experiments across four styles show that (1) incorporating reasoning traces substantially improves multimodal figurative understanding, (2) reasoning learned in one style can transfer to others, especially between related styles like sarcasm and humor, and (3) training jointly across styles yields a generalized reasoning VLM that outperforms much larger open- and closed-source models. Our findings show that lightweight VLMs with verifiable reasoning achieve robust cross-style generalization while providing inspectable reasoning traces for multimodal tasks. The code and implementation are available at https://github.com/scheshmi/CrossStyle-MMR.
Scaling Unverifiable Rewards: A Case Study on Visual Insights
Dec 27, 2025Large Language Model (LLM) agents can increasingly automate complex reasoning through Test-Time Scaling (TTS), iterative refinement guided by reward signals. However, many real-world tasks involve multi-stage pipeline whose final outcomes lack verifiable rewards or sufficient data to train robust reward models, making judge-based refinement prone to accumulate error over stages. We propose Selective TTS, a process-based refinement framework that scales inference across different stages in multi-agent pipeline, instead of repeated refinement over time by prior work. By distributing compute across stages and pruning low-quality branches early using process-specific judges, Selective TTS mitigates the judge drift and stabilizes refinement. Grounded in the data science pipeline, we build an end-to-end multi-agent pipeline for generating visually insightful charts and report of given dataset, and design a reliable LLM-based judge model, aligned with human experts (Kendall's τ=0.55). Our proposed selective TTS then improves insight quality under a fixed compute budget, increasing mean scores from 61.64 to 65.86 while reducing variance. We hope our findings serve as the first step toward to scaling complex, open-ended tasks with unverifiable rewards, such as scientific discovery and story generation.
A2P-Vis: an Analyzer-to-Presenter Agentic Pipeline for Visual Insights Generation and Reporting
Dec 26, 2025Automating end-to-end data science pipeline with AI agents still stalls on two gaps: generating insightful, diverse visual evidence and assembling it into a coherent, professional report. We present A2P-Vis, a two-part, multi-agent pipeline that turns raw datasets into a high-quality data-visualization report. The Data Analyzer orchestrates profiling, proposes diverse visualization directions, generates and executes plotting code, filters low-quality figures with a legibility checker, and elicits candidate insights that are automatically scored for depth, correctness, specificity, depth and actionability. The Presenter then orders topics, composes chart-grounded narratives from the top-ranked insights, writes justified transitions, and revises the document for clarity and consistency, yielding a coherent, publication-ready report. Together, these agents convert raw data into curated materials (charts + vetted insights) and into a readable narrative without manual glue work. We claim that by coupling a quality-assured Analyzer with a narrative Presenter, A2P-Vis operationalizes co-analysis end-to-end, improving the real-world usefulness of automated data analysis for practitioners. For the complete dataset report, please see: https://www.visagent.org/api/output/f2a3486d-2c3b-4825-98d4-5af25a819f56.
* 3 pages, 3 figures; Accepted by 1st Workshop on GenAI, Agents and the Future of VIS as Mini-challenge paper and win the Honorable Mention award. Submit number is 7597 and the paper is archived on the workshop website: https://visxgenai.github.io/subs-2025/7597/7597-doc.pdf
Mary, the Cheeseburger-Eating Vegetarian: Do LLMs Recognize Incoherence in Narratives?
Dec 08, 2025



Leveraging a dataset of paired narratives, we investigate the extent to which large language models (LLMs) can reliably separate incoherent and coherent stories. A probing study finds that LLMs' internal representations can reliably identify incoherent narratives. However, LLMs generate responses to rating questions that fail to satisfactorily separate the coherent and incoherent narratives across several prompt variations, hinting at a gap in LLM's understanding of storytelling. The reasoning LLMs tested do not eliminate these deficits, indicating that thought strings may not be able to fully address the discrepancy between model internal state and behavior. Additionally, we find that LLMs appear to be more sensitive to incoherence resulting from an event that violates the setting (e.g., a rainy day in the desert) than to incoherence arising from a character violating an established trait (e.g., Mary, a vegetarian, later orders a cheeseburger), suggesting that LLMs may rely more on prototypical world knowledge than building meaning-based narrative coherence. The consistent asymmetry found in our results suggests that LLMs do not have a complete grasp on narrative coherence.
Are LLM Agents Behaviorally Coherent? Latent Profiles for Social Simulation
Sep 03, 2025The impressive capabilities of Large Language Models (LLMs) have fueled the notion that synthetic agents can serve as substitutes for real participants in human-subject research. In an effort to evaluate the merits of this claim, social science researchers have largely focused on whether LLM-generated survey data corresponds to that of a human counterpart whom the LLM is prompted to represent. In contrast, we address a more fundamental question: Do agents maintain internal consistency, retaining similar behaviors when examined under different experimental settings? To this end, we develop a study designed to (a) reveal the agent's internal state and (b) examine agent behavior in a basic dialogue setting. This design enables us to explore a set of behavioral hypotheses to assess whether an agent's conversation behavior is consistent with what we would expect from their revealed internal state. Our findings on these hypotheses show significant internal inconsistencies in LLMs across model families and at differing model sizes. Most importantly, we find that, although agents may generate responses matching those of their human counterparts, they fail to be internally consistent, representing a critical gap in their capabilities to accurately substitute for real participants in human-subject research. Our simulation code and data are publicly accessible.
Toward Evaluative Thinking: Meta Policy Optimization with Evolving Reward Models
Apr 28, 2025



Reward-based alignment methods for large language models (LLMs) face two key limitations: vulnerability to reward hacking, where models exploit flaws in the reward signal; and reliance on brittle, labor-intensive prompt engineering when LLMs are used as reward models. We introduce Meta Policy Optimization (MPO), a framework that addresses these challenges by integrating a meta-reward model that dynamically refines the reward model's prompt throughout training. In MPO, the meta-reward model monitors the evolving training context and continuously adjusts the reward model's prompt to maintain high alignment, providing an adaptive reward signal that resists exploitation by the policy. This meta-learning approach promotes a more stable policy optimization, and greatly reduces the need for manual reward prompt design. It yields performance on par with or better than models guided by extensively hand-crafted reward prompts. Furthermore, we show that MPO maintains its effectiveness across diverse tasks, such as question answering and mathematical reasoning, without requiring specialized reward designs. Beyond standard RLAIF, MPO's meta-learning formulation is readily extensible to higher-level alignment frameworks. Overall, this method addresses theoretical and practical challenges in reward-based RL alignment for LLMs, paving the way for more robust and adaptable alignment strategies. The code and models will be publicly shared.
LawFlow : Collecting and Simulating Lawyers' Thought Processes
Apr 26, 2025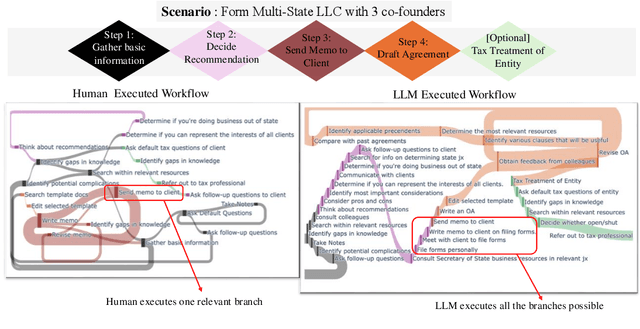
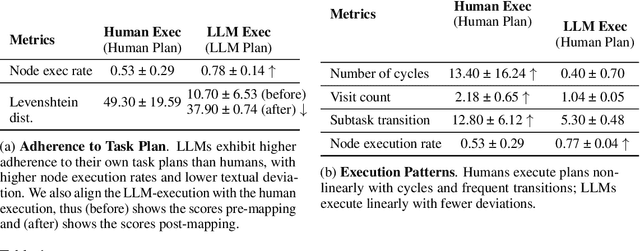
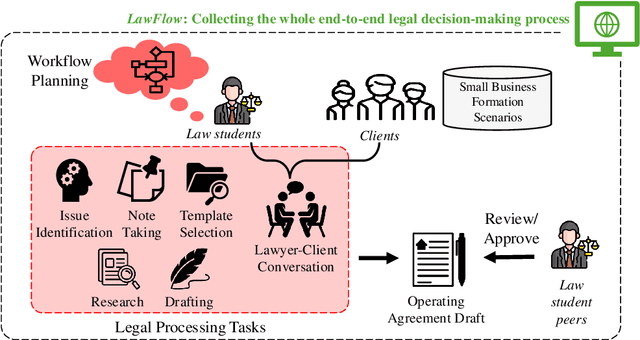
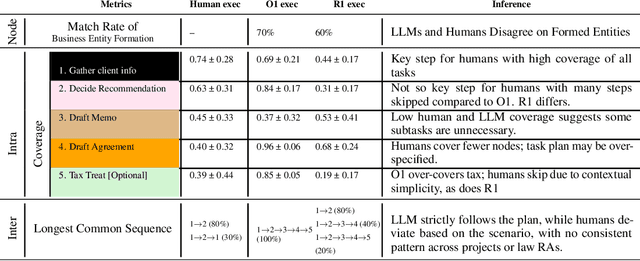
Legal practitioners, particularly those early in their careers, face complex, high-stakes tasks that require adaptive, context-sensitive reasoning. While AI holds promise in supporting legal work, current datasets and models are narrowly focused on isolated subtasks and fail to capture the end-to-end decision-making required in real-world practice. To address this gap, we introduce LawFlow, a dataset of complete end-to-end legal workflows collected from trained law students, grounded in real-world business entity formation scenarios. Unlike prior datasets focused on input-output pairs or linear chains of thought, LawFlow captures dynamic, modular, and iterative reasoning processes that reflect the ambiguity, revision, and client-adaptive strategies of legal practice. Using LawFlow, we compare human and LLM-generated workflows, revealing systematic differences in structure, reasoning flexibility, and plan execution. Human workflows tend to be modular and adaptive, while LLM workflows are more sequential, exhaustive, and less sensitive to downstream implications. Our findings also suggest that legal professionals prefer AI to carry out supportive roles, such as brainstorming, identifying blind spots, and surfacing alternatives, rather than executing complex workflows end-to-end. Building on these findings, we propose a set of design suggestions, rooted in empirical observations, that align AI assistance with human goals of clarity, completeness, creativity, and efficiency, through hybrid planning, adaptive execution, and decision-point support. Our results highlight both the current limitations of LLMs in supporting complex legal workflows and opportunities for developing more collaborative, reasoning-aware legal AI systems. All data and code are available on our project page (https://minnesotanlp.github.io/LawFlow-website/).
Stealing Creator's Workflow: A Creator-Inspired Agentic Framework with Iterative Feedback Loop for Improved Scientific Short-form Generation
Apr 26, 2025Generating engaging, accurate short-form videos from scientific papers is challenging due to content complexity and the gap between expert authors and readers. Existing end-to-end methods often suffer from factual inaccuracies and visual artifacts, limiting their utility for scientific dissemination. To address these issues, we propose SciTalk, a novel multi-LLM agentic framework, grounding videos in various sources, such as text, figures, visual styles, and avatars. Inspired by content creators' workflows, SciTalk uses specialized agents for content summarization, visual scene planning, and text and layout editing, and incorporates an iterative feedback mechanism where video agents simulate user roles to give feedback on generated videos from previous iterations and refine generation prompts. Experimental evaluations show that SciTalk outperforms simple prompting methods in generating scientifically accurate and engaging content over the refined loop of video generation. Although preliminary results are still not yet matching human creators' quality, our framework provides valuable insights into the challenges and benefits of feedback-driven video generation. Our code, data, and generated videos will be publicly available.
Learning Explainable Dense Reward Shapes via Bayesian Optimization
Apr 22, 2025Current reinforcement learning from human feedback (RLHF) pipelines for large language model (LLM) alignment typically assign scalar rewards to sequences, using the final token as a surrogate indicator for the quality of the entire sequence. However, this leads to sparse feedback and suboptimal token-level credit assignment. In this work, we frame reward shaping as an optimization problem focused on token-level credit assignment. We propose a reward-shaping function leveraging explainability methods such as SHAP and LIME to estimate per-token rewards from the reward model. To learn parameters of this shaping function, we employ a bilevel optimization framework that integrates Bayesian Optimization and policy training to handle noise from the token reward estimates. Our experiments show that achieving a better balance of token-level reward attribution leads to performance improvements over baselines on downstream tasks and finds an optimal policy faster during training. Furthermore, we show theoretically that explainability methods that are feature additive attribution functions maintain the optimal policy as the original reward.