 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
Mar 19, 2026Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) and artificial intelligence (AI) agents have significantly automated data science workflow. However, it remains unclear to what extent AI agents can match the performance of human experts on domain-specific data science tasks, and in which aspects human expertise continues to provide advantages. We introduce AgentDS, a benchmark and competition designed to evaluate both AI agents and human-AI collaboration performance in domain-specific data science. AgentDS consists of 17 challenges across six industries: commerce, food production, healthcare, insurance, manufacturing, and retail banking. We conducted an open competition involving 29 teams and 80 participants, enabling systematic comparison between human-AI collaborative approaches and AI-only baselines. Our results show that current AI agents struggle with domain-specific reasoning. AI-only baselines perform near or below the median of competition participants, while the strongest solutions arise from human-AI collaboration. These findings challenge the narrative of complete automation by AI and underscore the enduring importance of human expertise in data science, while illuminating directions for the next generation of AI. Visit the AgentDS website here: https://agentds.org/ and open source datasets here: https://huggingface.co/datasets/lainmn/AgentDS .
Can Agentic AI Match the Performance of Human Data Scientists?
Dec 24, 2025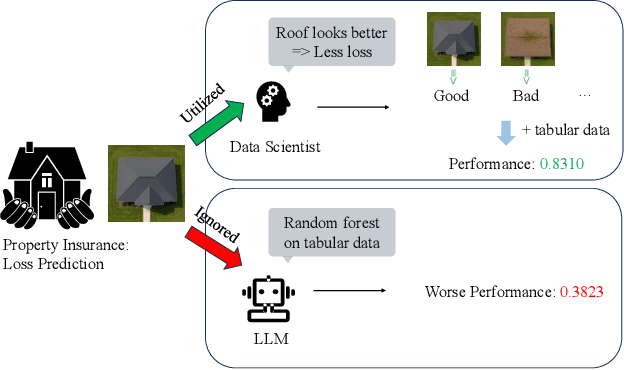

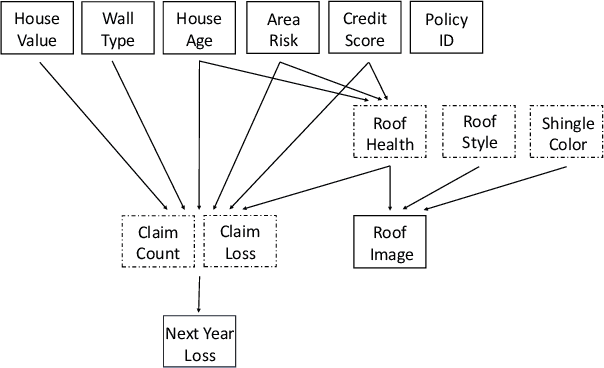

Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) have significantly automated data science workflows, but a fundamental question persists: Can these agentic AI systems truly match the performance of human data scientists who routinely leverage domain-specific knowledge? We explore this question by designing a prediction task where a crucial latent variable is hidden in relevant image data instead of tabular features. As a result, agentic AI that generates generic codes for modeling tabular data cannot perform well, while human experts could identify the important hidden variable using domain knowledge. We demonstrate this idea with a synthetic dataset for property insurance. Our experiments show that agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights. This highlights a key limitation of the current agentic AI for data science and underscores the need for future research to develop agentic AI systems that can better recognize and incorporate domain knowledge.
A benchmark multimodal oro-dental dataset for large vision-language models
Nov 07, 2025



The advancement of artificial intelligence in oral healthcare relies on the availability of large-scale multimodal datasets that capture the complexity of clinical practice. In this paper, we present a comprehensive multimodal dataset, comprising 8775 dental checkups from 4800 patients collected over eight years (2018-2025), with patients ranging from 10 to 90 years of age. The dataset includes 50000 intraoral images, 8056 radiographs, and detailed textual records, including diagnoses, treatment plans, and follow-up notes. The data were collected under standard ethical guidelines and annotated for benchmarking. To demonstrate its utility, we fine-tuned state-of-the-art large vision-language models, Qwen-VL 3B and 7B, and evaluated them on two tasks: classification of six oro-dental anomalies and generation of complete diagnostic reports from multimodal inputs. We compared the fine-tuned models with their base counterparts and GPT-4o. The fine-tuned models achieved substantial gains over these baselines, validating the dataset and underscoring its effectiveness in advancing AI-driven oro-dental healthcare solutions. The dataset is publicly available, providing an essential resource for future research in AI dentistry.
An Outlook on the Opportunities and Challenges of Multi-Agent AI Systems
May 23, 2025Multi-agent AI systems (MAS) offer a promising framework for distributed intelligence, enabling collaborative reasoning, planning, and decision-making across autonomous agents. This paper provides a systematic outlook on the current opportunities and challenges of MAS, drawing insights from recent advances in large language models (LLMs), federated optimization, and human-AI interaction. We formalize key concepts including agent topology, coordination protocols, and shared objectives, and identify major risks such as dependency, misalignment, and vulnerabilities arising from training data overlap. Through a biologically inspired simulation and comprehensive theoretical framing, we highlight critical pathways for developing robust, scalable, and secure MAS in real-world settings.
Ice Cream Doesn't Cause Drowning: Benchmarking LLMs Against Statistical Pitfalls in Causal Inference
May 19, 2025Reliable causal inference is essential for making decisions in high-stakes areas like medicine, economics, and public policy. However, it remains unclear whether large language models (LLMs) can handle rigorous and trustworthy statistical causal inference. Current benchmarks usually involve simplified tasks. For example, these tasks might only ask LLMs to identify semantic causal relationships or draw conclusions directly from raw data. As a result, models may overlook important statistical pitfalls, such as Simpson's paradox or selection bias. This oversight limits the applicability of LLMs in the real world. To address these limitations, we propose CausalPitfalls, a comprehensive benchmark designed to rigorously evaluate the capability of LLMs in overcoming common causal inference pitfalls. Our benchmark features structured challenges across multiple difficulty levels, each paired with grading rubrics. This approach allows us to quantitatively measure both causal reasoning capabilities and the reliability of LLMs' responses. We evaluate models using two protocols: (1) direct prompting, which assesses intrinsic causal reasoning, and (2) code-assisted prompting, where models generate executable code for explicit statistical analysis. Additionally, we validate the effectiveness of this judge by comparing its scoring with assessments from human experts. Our results reveal significant limitations in current LLMs when performing statistical causal inference. The CausalPitfalls benchmark provides essential guidance and quantitative metrics to advance the development of trustworthy causal reasoning systems.
Drift to Remember
Sep 21, 2024

Lifelong learning in artificial intelligence (AI) aims to mimic the biological brain's ability to continuously learn and retain knowledge, yet it faces challenges such as catastrophic forgetting. Recent neuroscience research suggests that neural activity in biological systems undergoes representational drift, where neural responses evolve over time, even with consistent inputs and tasks. We hypothesize that representational drift can alleviate catastrophic forgetting in AI during new task acquisition. To test this, we introduce DriftNet, a network designed to constantly explore various local minima in the loss landscape while dynamically retrieving relevant tasks. This approach ensures efficient integration of new information and preserves existing knowledge. Experimental studies in image classification and natural language processing demonstrate that DriftNet outperforms existing models in lifelong learning. Importantly, DriftNet is scalable in handling a sequence of tasks such as sentiment analysis and question answering using large language models (LLMs) with billions of parameters on a single Nvidia A100 GPU. DriftNet efficiently updates LLMs using only new data, avoiding the need for full dataset retraining. Tested on GPT-2 and RoBERTa, DriftNet is a robust, cost-effective solution for lifelong learning in LLMs. This study not only advances AI systems to emulate biological learning, but also provides insights into the adaptive mechanisms of biological neural systems, deepening our understanding of lifelong learning in nature.